Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
System Center Blog
- Home
- System Center
- System Center Blog
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed

2,418
3,182
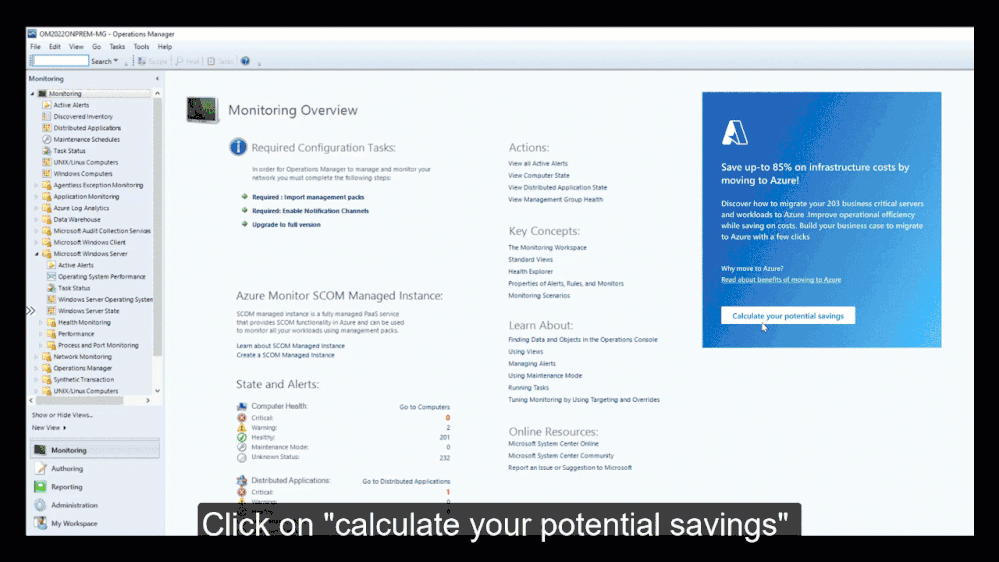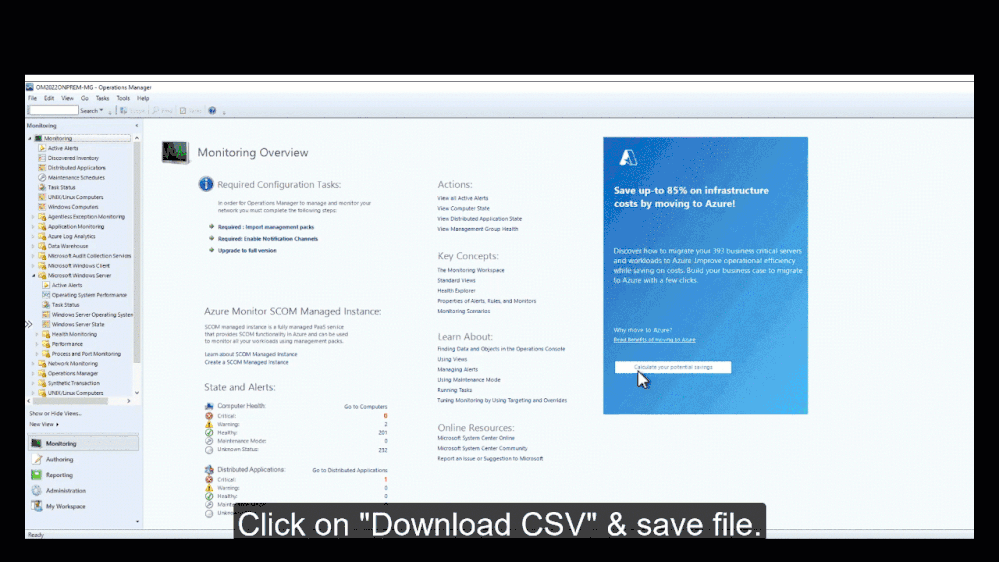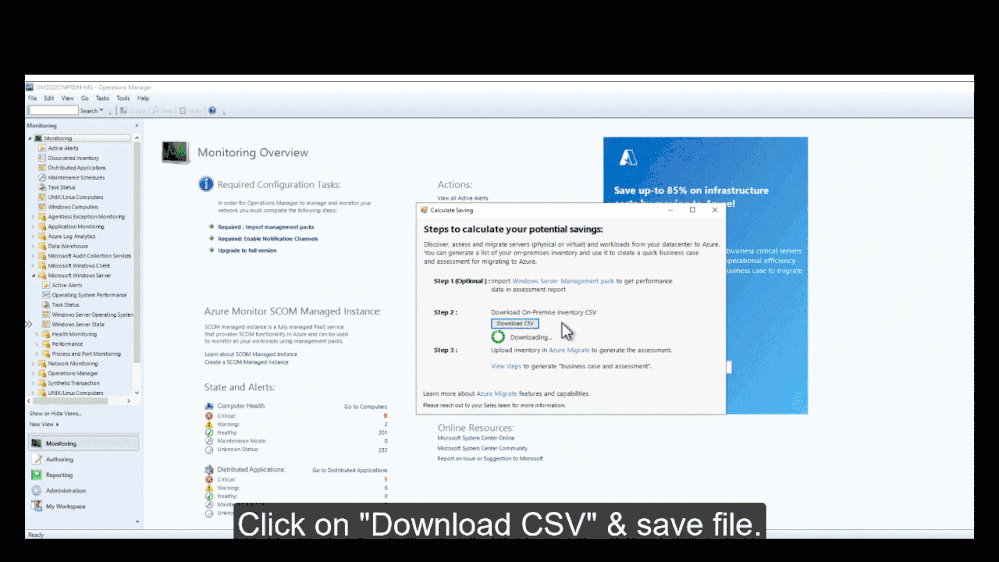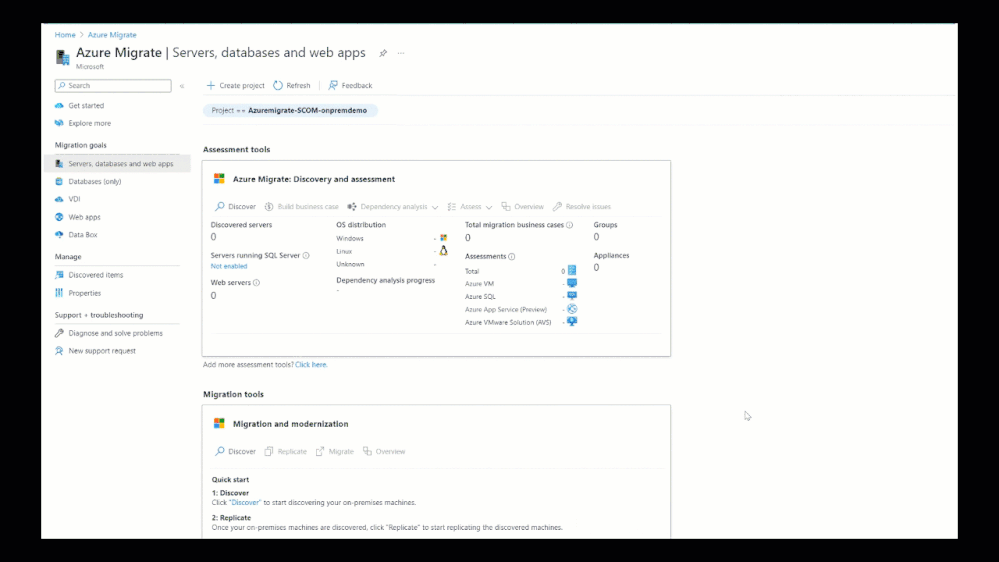

4,513
4,306
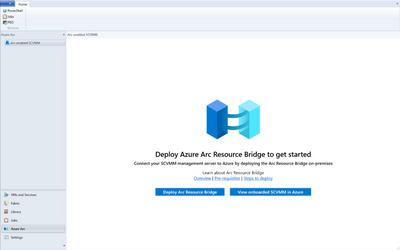
11.1K

6,969



9,042
13.2K
8,445
Latest Comments