Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Skype for Business Blog
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
1 0
1000
1026
1 1
21 things
Active Directory
addomainnamingcontextlist
AddressBook
ADFS
administrative templates
allowsavepassword
alternate
alternate login
Android
Announcement
Announcements
announcement service
antivirus
application error
application pool
application pool crashes
Applications
application sharing
Archiving
Audio Conferencing
Authentication
autoattendant
Auto Attendant
bandwidth management
Best Practices
cac
Calling
Call Queues
Call Queues questions
calls
CCE
cdr
cdr throttle
Certificates
challenge
chat
client
client logs
clients and devices
cloud connector edition
cloud connector edition skype for business hybrid cce
Cloud PBX
cls
cls logging scenario
cls scenario
Cmdlets
codec
Collaboration
collect client logs
collect cls logging
collect lync client logs
collect skype for business client logs
comserv
conferencing
contacts
CQD
cqm
csconferencingpolicy
Customer Stories
datamcusvc exe
datetime
Deployment
Deployment & Operations
devices
dial in conferencing
dialplans
director
disable
domaincontrollerlist
e 164
e5
E911
edge servers
Enterprise Voice
Error
event id 30002
event id 30005
event id 30011
event id 30012
event id 30014
event id 30020
event id 30021
event id 30024
event id 30027
event id 30031
event id 30054
event id 30057
event id 56208
Exchange
exchange um
external user access
Federation
General
general ocs
general powershell
haiku
help
howto
Hybrid
hybrid voice
identities
im and presence
im presence
Integration
Interoperability
Interview
Licensing
Lync
lync 2013
lyncmd
lync mvp
lync online
lync pro
lync server 2010
Lync Server 2013
lync server powershell
Media
Meetings
Microsoft Teams
Migration
Mobility
modern auth
Modern authentication
monitoring
NET
net framework
News
NextHop
O365
ocs r2
Office365
Office 365
Operate
Operations
pchat
phones
Policies
PowerShell
Preview
Product Updates
properties
psreference
pstn connectivity
qoe
Quality & Reliability
quick start
RBAC
Readiness
reference
registrar
remoting
reskit tools
resource kit
Response Group
rgs
Roadmap
routing
script
SDN
Security
services
setup deployment
SfB
sfb client
sfb client sign in
sign in
sip trunk
Skype Academy
Skype for Business
Skype for Business Adoption
Skype for Business Online
skype for business server
skype online
Skype Operations Framework
snippets
Software Defined Networking
synthetic transactions
technical reference
telephony
tips
Tips & Tricks
tools
topology
tr11
Training
Troubleshooting
UM
um online
Unified Messaging
users
Voice
voice app
walkthrough
white paper
Wiki
- Home
- Skype for Business
- Skype for Business Blog
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed

7,715

5,605

9,347

11.5K
174K

15.8K

24.1K

11.4K
10.4K
22.8K
13.2K
9,600
8,091

15.2K

11.4K

35.4K
22.1K

10.7K
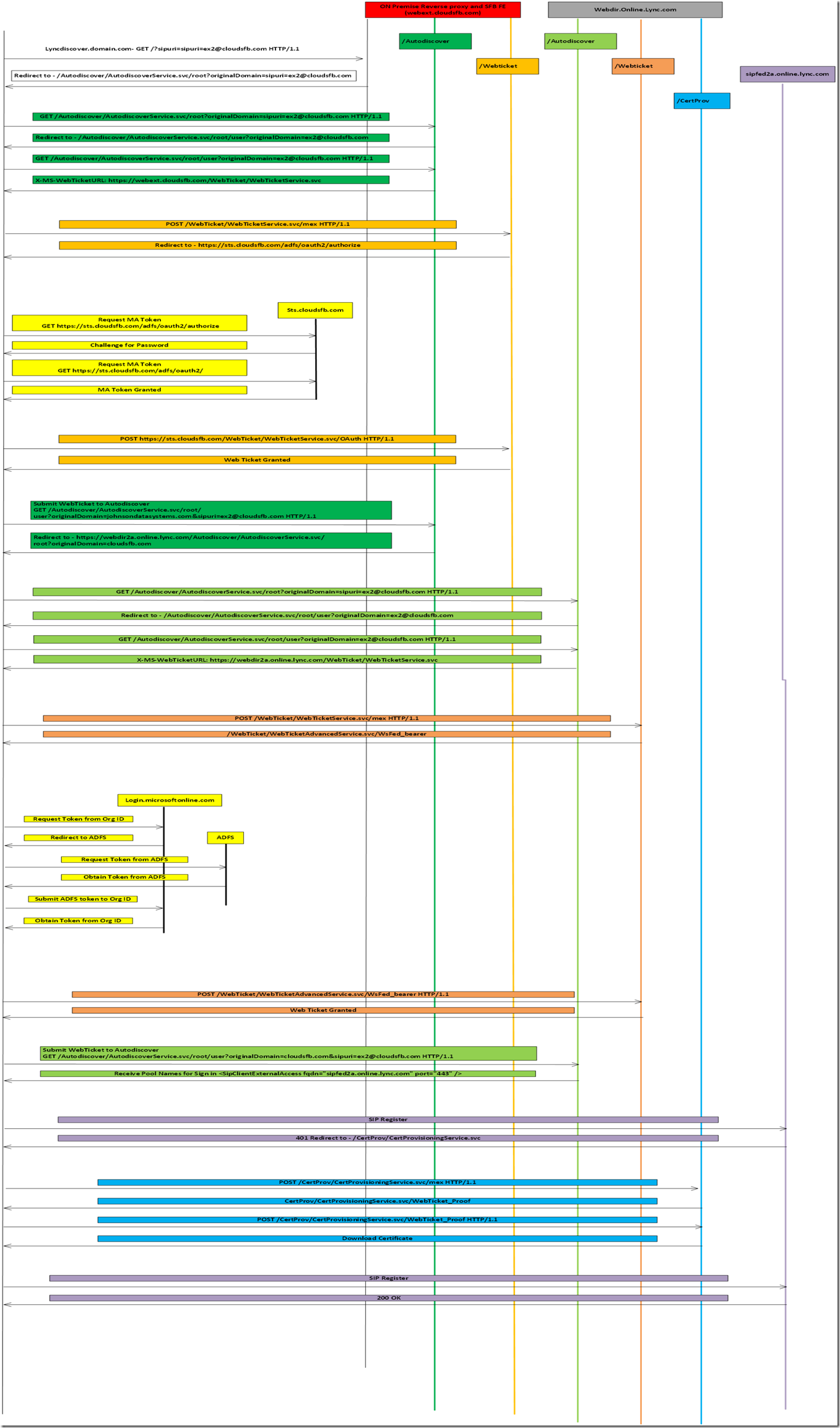
9,426
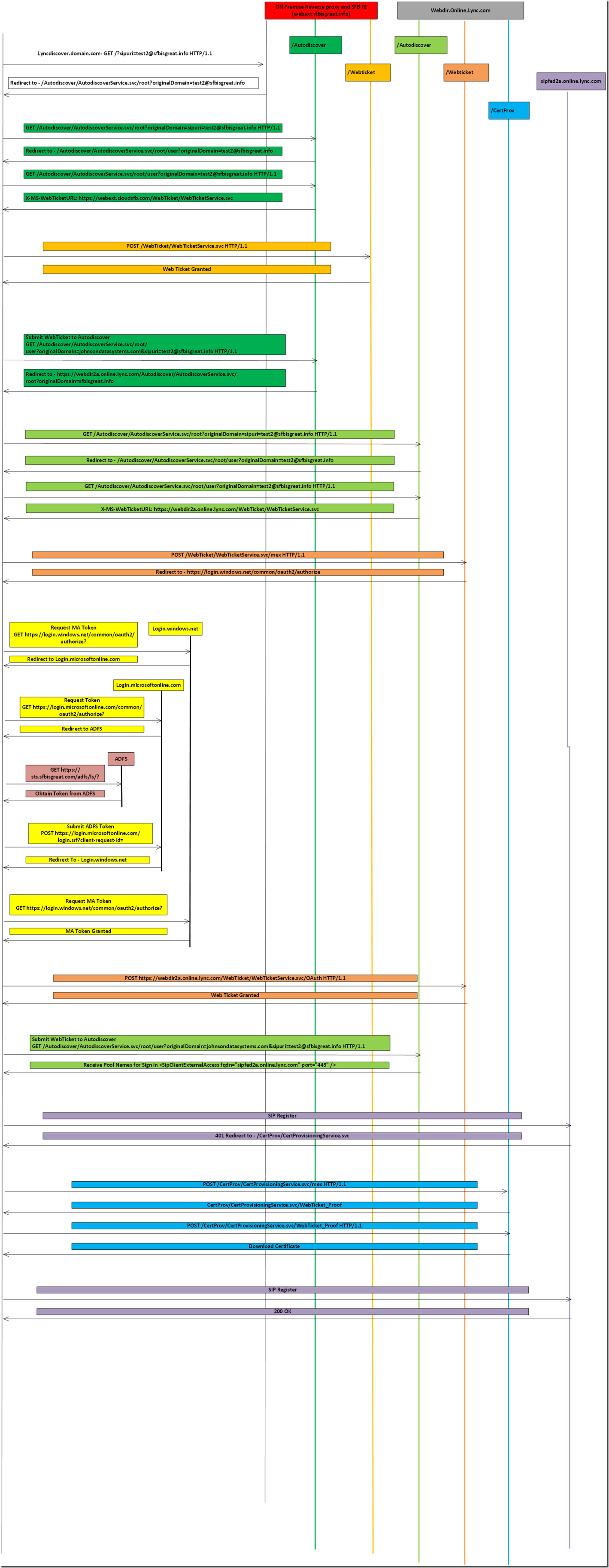
11K
8,755
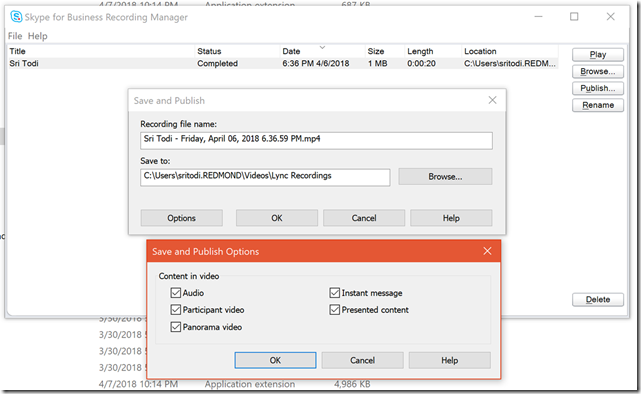
11.3K
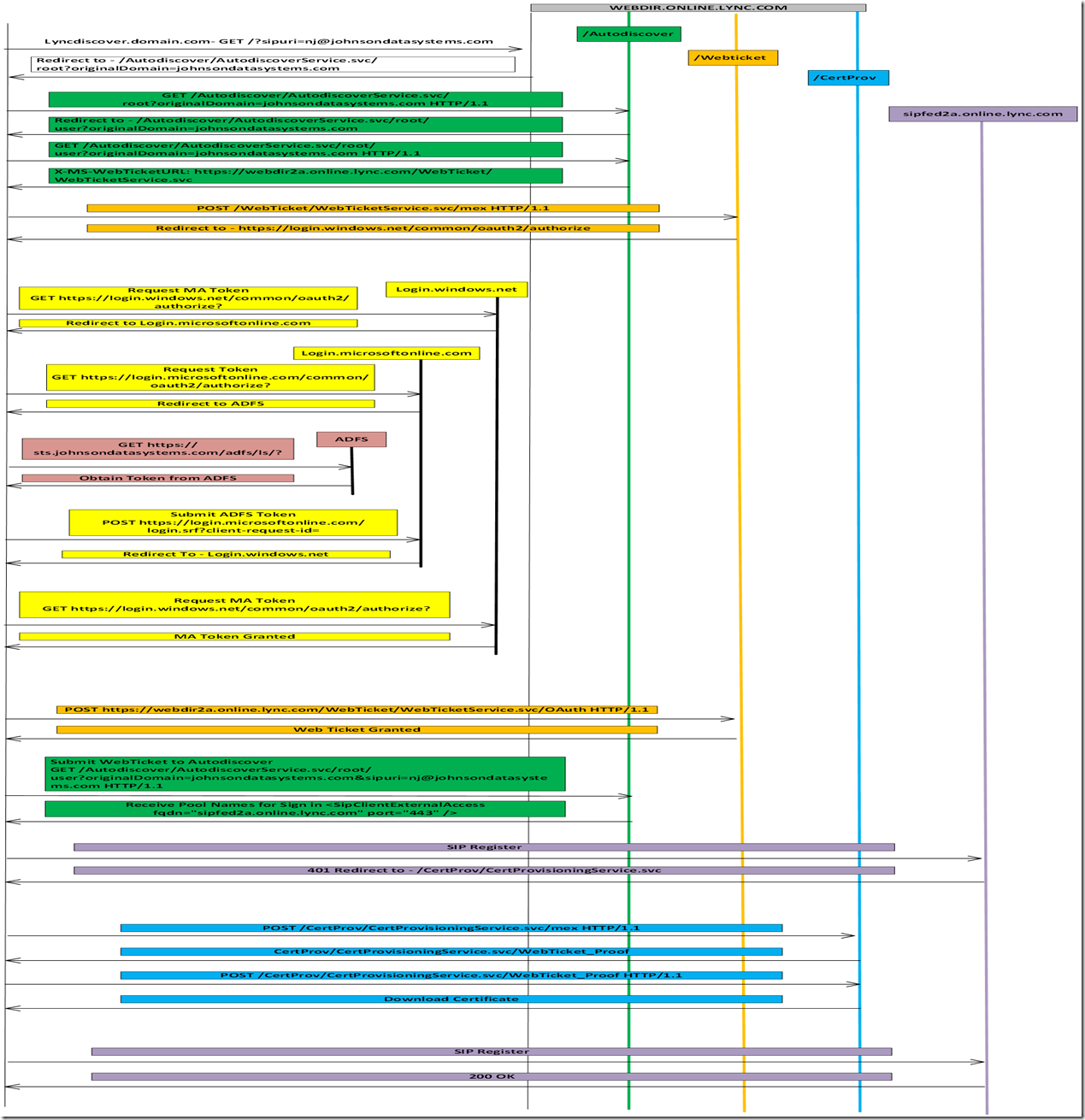
8,726

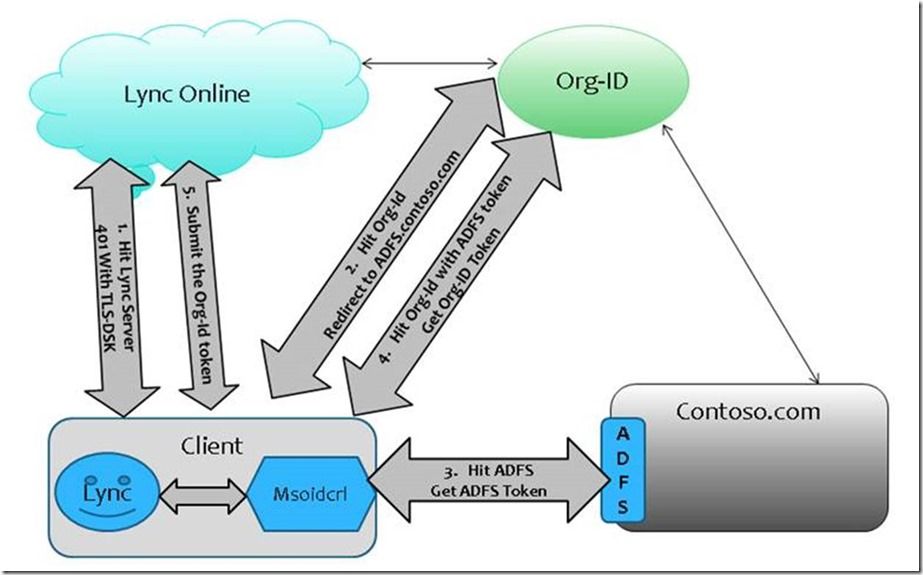
24.4K
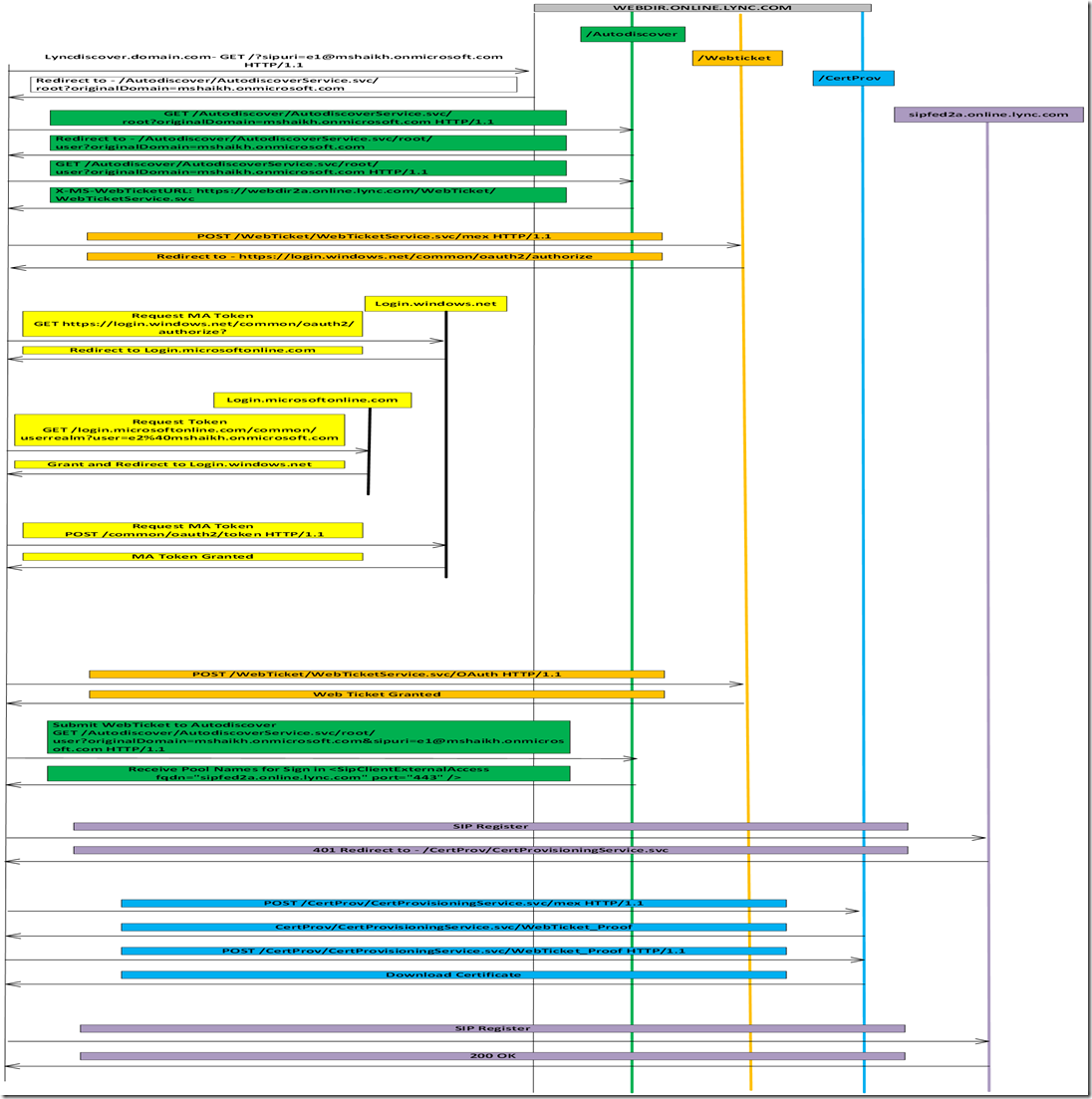
8,895
Latest Comments