Using Microsoft’s Deep Learning Toolkit with Spark on Azure HDInsight Clusters
This post is authored by Miruna Oprescu, Software Engineer, and Mary Wahl, Data Scientist at Microsoft
Have you ever wondered what it would be like to combine the power of deep learning with the scalability of distributed computing? Say no more! We present a solution that uses leading-edge technologies to score images using a pre-trained deep learning model in a distributed and scalable fashion.
This post is a follow-up to the "Embarrassingly Parallel Image Classification, Using Cognitive Toolkit and TensorFlow on Azure HDInsight Spark" post that came out recently, and describes the methods and best practices used in configuring the Microsoft deep learning toolkit on an HDInsight cluster. Our approach is described in detail by our full tutorial and Jupyter notebook.
Recipe
- Begin with an Azure HDInsight Hadoop cluster pre-provisioned with an Apache Spark 2.1.0 distribution. Spark is a distributed-computing framework widely used for big data processing, streaming, and machine learning. Spark HDInsight clusters come with pre-configured Python environments where the Spark Python API (PySpark) can be used.
- Install the Microsoft Cognitive Toolkit (CNTK) on all cluster nodes using a Script Action. Cognitive Toolkit is an open-source deep-learning library from Microsoft. As of version 2.0, Cognitive Toolkit has high-level Python interfaces for both training models on CPUs/GPUs as well as loading and scoring pre-trained models. Cognitive Toolkit can be installed as a Python package in the existing Python environments on all nodes of the HDInsight cluster. Script actions enable this installation to be done in one step using one script, thus eliminating the hurdles involved in configuring each cluster node separately. In addition to installing necessary Python packages and required dependencies, script actions can also be used to restart any affected applications and services in order to maintain the cluster state consistent.
- Pre-process and score thousands of images in parallel using Cognitive Toolkit and PySpark in a Jupyter notebook. Python can be run interactively through Jupyter Notebooks which also provide a visualization environment. This solution uses the Cognitive Toolkit Python APIs and PySpark inside a Jupyter notebook on an HDInsight cluster.
The same strategy can also be used to extract features from image datasets in a scalable manner using pre-trained neural networks. More about this in the "Try it Out!" section.
Example
We followed this recipe on the CIFAR-10 image set compiled and distributed by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton. The CIFAR-10 dataset contains 60,000 32x32 color images belonging to 10 mutually exclusive classes:

For more details on the dataset, see Alex Krizhevsky's Learning Multiple Layers of Features from Tiny Images (2009).
The dataset was partitioned into a training set of 50,000 images and a test set of 10,000 images. The first set was used to train a twenty-layer deep convolutional residual network (ResNet) model using Cognitive Toolkit by following this tutorial from the Cognitive Toolkit GitHub repository. The remaining 10,000 images were used for testing the model's accuracy. This is where distributed computing comes into play: the task of preprocessing and scoring the images is highly parallelizable. With the saved trained model in hand, we used:
- PySpark to distribute the images and trained model to the cluster's worker nodes.
- Python to preprocess the images on each node.
- Cognitive Toolkit to load the model and score the pre-processed images on each node.
- Jupyter Notebooks to run the PySpark script, aggregate the results and use Scikit-Learn/Matplotlib to visualize the model performance.
The entire preprocessing/scoring of the 10,000 images takes less than one minute on a cluster with 4 worker nodes. The model accurately predicts the labels of ~9,100 (91%) images. A confusion matrix illustrates the most common classification errors:
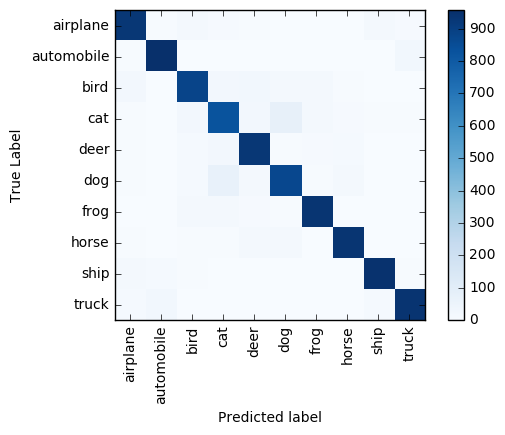
For example, the matrix shows that mislabeling dogs as cats and vice versa occurs more frequently than for other label pairs.
Conclusion
Apache Spark provides a framework for parallelizing computations over large datasets on a cluster while the Microsoft Cognitive Toolkit offers a state-of-the-art Python package for deep learning. Setting up a cluster where these tools interoperate efficiently and in a user-friendly environment is usually error-prone and time consuming. In this post, we described a "turnkey" setup script that can configure Cognitive Toolkit on an HDInsight Spark cluster, as well as an example Jupyter notebook that illustrates best practices in utilizing Cognitive Toolkit at scale for scoring and evaluating a pre-trained model.
Try it Out!
- Follow the tutorial here to implement this solution end-to-end: setup an HDInsight Spark cluster, install Cognitive Toolkit, and run the Jupyter Notebook that scores 10,000 CIFAR images.
- More advanced:
- Take your favorite image dataset.
- Obtain a pre-trained Cognitive Toolkit ResNet model (such as this) and remove the final dense layer to turn it into an image featurizer.
- Extract the image features and use them to train a scalable classifier with PySpark (see here). This step is fully parallelizable.
If you try out the techniques described in this post, please share your feedback below and let us know about your experience.
Miruna & Mary