Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Home
- Windows Server
- Storage at Microsoft
- The new HCI industry record: 13.7 million IOPS with Windows Server 2019 and Intel® Optane™ DC persistent memory
The new HCI industry record: 13.7 million IOPS with Windows Server 2019 and Intel® Optane™ DC persistent memory
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Published
Apr 10 2019 07:52 AM
34.5K
Views
Apr 10 2019
07:52 AM
Apr 10 2019
07:52 AM
First published on TECHNET on Oct 30, 2018
Written by Cosmos Darwin, Senior PM on the Core OS team at Microsoft. Follow him on Twitter @cosmosdarwin .

Hyper-converged infrastructure is an important shift in datacenter technology. By moving away from proprietary storage arrays to an architecture built on industry-standard interconnects, x86 servers, and local drives, organizations can benefit from the latest cloud technology faster and more affordably than ever before.
Watch this demo from Microsoft Ignite 2018:
Intel® Optane™ DC persistent memory delivers breakthrough storage performance. To go with the fastest hardware, you need the fastest software. Hyper-V and Storage Spaces Direct in Windows Server 2019 are the foundational hypervisor and software-defined storage of the Microsoft Cloud. Purpose-built for efficiency and performance, they're embedded in the Windows kernel and meticulously optimized. To learn more about hyper-converged infrastructure powered by Windows Server, visit Microsoft.com/HCI .
For details about this demo, including some additional results, read on!
[caption id="attachment_9645" align="aligncenter" width="879"] The reference configuration developed jointly by Intel and Microsoft.[/caption]
The reference configuration developed jointly by Intel and Microsoft.[/caption]
Each server node:
[caption id="attachment_9675" align="aligncenter" width="879"] Intel® Optane™ DC modules are DDR4 pin compatible but provide native storage persistence.[/caption]
Intel® Optane™ DC modules are DDR4 pin compatible but provide native storage persistence.[/caption]
Windows OS. Every server node runs Windows Server 2019 Datacenter pre-release build 17763, the latest available on September 20, 2018. The power plan is set to High Performance, and all other settings are default, including applying relevant side-channel mitigations. (Specifically, mitigations for Spectre v1 and Meltdown are applied.)
Storage Spaces Direct. Best practice is to create one or two data volumes per server node, so we create 12 volumes with ReFS. Each volume is 8 TiB, for about 100 TiB of total usable storage. Each volume uses three-way mirror resiliency, with allocation delimited to three servers. All other settings, like columns and interleave, are default. To accurately measure IOPS to persistent storage only, the in-memory CSV read cache is disabled.
Hyper-V VMs. Ordinarily we’d create one virtual processor per physical core. For example, with 2 sockets x 28 cores we’d assign up to 56 virtual processors per server node. In this case, to saturate performance took 26 virtual machines x 4 virtual processors each = 104 virtual processors. That’s 312 total Hyper-V Gen 2 VMs across the 12 server nodes. Each VM runs Windows and is assigned 4 GiB of memory.
VHDXs. Every VM is assigned one fixed 40 GiB VHDX where it reads and writes to one 10 GiB test file. For the best performance, every VM runs on the server node that owns the volume where its VHDX file is stored. The total active working set, accounting for three-way mirror resiliency, is 312 x 10 GiB x 3 = 9.36 TiB, which fits comfortably within the Intel® Optane™ DC persistent memory.
There are many ways to measure storage performance, depending on the application. For example, you can measure the rate of data transfer (GB/s) by simply copying files, although this isn’t the best methodology. For databases, you can measure transactions per second (T/s). In virtualization and hyper-converged infrastructure, it’s standard to count storage input/output (I/O) operations per second, or “IOPS” – essentially, the number of reads or writes that virtual machines can perform.
More precisely, we know that Hyper-V virtual machines typically perform random 4 kB block-aligned IO, so that’s our benchmark of choice.
How do you generate 4 kB random IOPS?
In summary, here’s how DISKSPD is being invoked:
How do you count 4 kB random IOPS?
[caption id="attachment_9685" align="aligncenter" width="879"]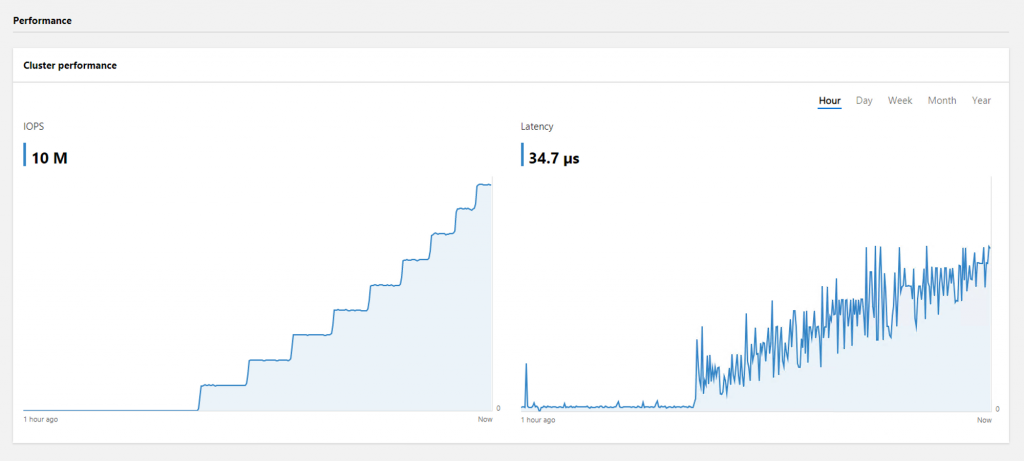 The HCI Dashboard in Windows Admin Center has charts for IOPS and IO latency.[/caption]
The HCI Dashboard in Windows Admin Center has charts for IOPS and IO latency.[/caption]
The other side to storage benchmarking is latency – how long an IO takes to complete. Many storage systems perform better under heavy queuing, which helps maximize parallelism and busy time at every layer of the stack. But there’s a tradeoff: queuing increases latency. For example, if you can do 100 IOPS with sub-millisecond latency, you may be able to achieve 200 IOPS if you accept higher latency. This is good to watch out for – sometimes the largest IOPS benchmark numbers are only possible with latency that would otherwise be unacceptable.
Cluster-wide aggregate IO latency, as measured at the same layer in Windows, is charted on the HCI Dashboard too.
Any storage system that provides fault tolerance necessarily makes distributed copies of writes, which must traverse the network and incurs backend write amplification. For this reason, the absolute largest IOPS benchmark numbers are typically achieved with reads only, especially if the storage system has common-sense optimizations to read from the local copy whenever possible, which Storage Spaces Direct does.
With 100% reads, the cluster delivers 13,798,674 IOPS.
[caption id="attachment_9655" align="aligncenter" width="879"] Industry-leading HCI benchmark of over 13.7M IOPS, with Windows Server 2019 and Intel® Optane™ DC persistent memory.[/caption]
Industry-leading HCI benchmark of over 13.7M IOPS, with Windows Server 2019 and Intel® Optane™ DC persistent memory.[/caption]
If you watch the video closely, what’s even more jaw-dropping is the latency: even at over 13.7 M IOPS, the filesystem in Windows is reporting latency that’s consistently less than 40 µs! (That’s the symbol for microseconds, one-millionths of a second.) This is an order of magnitude faster than what typical all-flash vendors proudly advertise today.
But most applications don’t just read, so we also measured with mixed reads and writes:
With 90% reads and 10% writes, the cluster delivers 9,459,587 IOPS.
In certain scenarios, like data warehouses, throughput (in GB/s) matters more, so we measured that too:
With larger 2 MB block size and sequential IO, the cluster can read 535.86 GB/s!
Here are all the results, with the same 12-server HCI cluster:
Together, Storage Spaces Direct in Windows Server 2019 and Intel® Optane™ DC persistent memory deliver breakthrough performance. This industry-leading HCI benchmark of over 13.7M IOPS, with predictable and extremely low latency, is more than double our previous industry-leading benchmark of 6.7M IOPS. What’s more, this time we needed just 12 server nodes, 25% fewer than two years ago.
[caption id="attachment_9635" align="aligncenter" width="879"] More than double our previous record, in just two years, with fewer server nodes.[/caption]
More than double our previous record, in just two years, with fewer server nodes.[/caption]
It’s an exciting time for Storage Spaces Direct. Early next year , the first wave of Windows Server Software-Defined (WSSD) offers with Windows Server 2019 will launch, delivering the latest cloud-inspired innovation to your datacenter, including native support for persistent memory. Intel® Optane™ DC persistent memory comes out early next year too.
We’re proud of these results, and we’re already working on what’s next. Hint: even bigger numbers!
Cosmos and the Storage Spaces Direct team at Microsoft,
and the Windows Operating System team at Intel

Written by Cosmos Darwin, Senior PM on the Core OS team at Microsoft. Follow him on Twitter @cosmosdarwin .
Hyper-converged infrastructure is an important shift in datacenter technology. By moving away from proprietary storage arrays to an architecture built on industry-standard interconnects, x86 servers, and local drives, organizations can benefit from the latest cloud technology faster and more affordably than ever before.
Watch this demo from Microsoft Ignite 2018:
Intel® Optane™ DC persistent memory delivers breakthrough storage performance. To go with the fastest hardware, you need the fastest software. Hyper-V and Storage Spaces Direct in Windows Server 2019 are the foundational hypervisor and software-defined storage of the Microsoft Cloud. Purpose-built for efficiency and performance, they're embedded in the Windows kernel and meticulously optimized. To learn more about hyper-converged infrastructure powered by Windows Server, visit Microsoft.com/HCI .
For details about this demo, including some additional results, read on!
Hardware
[caption id="attachment_9645" align="aligncenter" width="879"]
The reference configuration developed jointly by Intel and Microsoft.[/caption]
- 12 x 2U Intel® S2600WFT server nodes
- Intel® Turbo Boost ON, Intel® Hyper-Threading ON
Each server node:
- 384 GiB (12 x 32 GiB) DDR4 2666 memory
- 2 x 28-core future Intel® Xeon® Scalable processor
- 1.5 TB Intel® Optane™ DC persistent memory as cache
- 32 TB NVMe (4 x 8 TB Intel® DC P4510) as capacity
- 2 x Mellanox ConnectX-4 25 Gbps
[caption id="attachment_9675" align="aligncenter" width="879"]
Intel® Optane™ DC modules are DDR4 pin compatible but provide native storage persistence.[/caption]
Software
Windows OS. Every server node runs Windows Server 2019 Datacenter pre-release build 17763, the latest available on September 20, 2018. The power plan is set to High Performance, and all other settings are default, including applying relevant side-channel mitigations. (Specifically, mitigations for Spectre v1 and Meltdown are applied.)
Storage Spaces Direct. Best practice is to create one or two data volumes per server node, so we create 12 volumes with ReFS. Each volume is 8 TiB, for about 100 TiB of total usable storage. Each volume uses three-way mirror resiliency, with allocation delimited to three servers. All other settings, like columns and interleave, are default. To accurately measure IOPS to persistent storage only, the in-memory CSV read cache is disabled.
Hyper-V VMs. Ordinarily we’d create one virtual processor per physical core. For example, with 2 sockets x 28 cores we’d assign up to 56 virtual processors per server node. In this case, to saturate performance took 26 virtual machines x 4 virtual processors each = 104 virtual processors. That’s 312 total Hyper-V Gen 2 VMs across the 12 server nodes. Each VM runs Windows and is assigned 4 GiB of memory.
VHDXs. Every VM is assigned one fixed 40 GiB VHDX where it reads and writes to one 10 GiB test file. For the best performance, every VM runs on the server node that owns the volume where its VHDX file is stored. The total active working set, accounting for three-way mirror resiliency, is 312 x 10 GiB x 3 = 9.36 TiB, which fits comfortably within the Intel® Optane™ DC persistent memory.
Benchmark
There are many ways to measure storage performance, depending on the application. For example, you can measure the rate of data transfer (GB/s) by simply copying files, although this isn’t the best methodology. For databases, you can measure transactions per second (T/s). In virtualization and hyper-converged infrastructure, it’s standard to count storage input/output (I/O) operations per second, or “IOPS” – essentially, the number of reads or writes that virtual machines can perform.
More precisely, we know that Hyper-V virtual machines typically perform random 4 kB block-aligned IO, so that’s our benchmark of choice.
How do you generate 4 kB random IOPS?
- VM Fleet. We use the open-source VM Fleet tool available on GitHub. VM Fleet makes it easy to orchestrate running DISKSPD , the popular Windows micro-benchmark tool, in hundreds or thousands of Hyper-V virtual machines at once. To saturate performance, we specify 4 threads per file ( -t4 ) with 16 outstanding IOs per thread ( -o16 ). To skip the Windows cache manager, we specify unbuffered IO ( -Su ). And we specify random ( -r ) and 4 kB block-aligned ( -b4k ). We can vary the read/write mix by the -w parameter.
In summary, here’s how DISKSPD is being invoked:
.\diskspd.exe -d120 -t4 -o16 -Su -r -b4k -w0 [...]
How do you count 4 kB random IOPS?
- Windows Admin Center. Fortunately, Windows Admin Center makes it easy. The HCI Dashboard features an interactive chart plotting cluster-wide aggregate IOPS, as measured at the CSV filesystem layer in Windows. More detailed reporting is available in the command-line output of DISKSPD and VM Fleet.
[caption id="attachment_9685" align="aligncenter" width="879"]
The HCI Dashboard in Windows Admin Center has charts for IOPS and IO latency.[/caption]
The other side to storage benchmarking is latency – how long an IO takes to complete. Many storage systems perform better under heavy queuing, which helps maximize parallelism and busy time at every layer of the stack. But there’s a tradeoff: queuing increases latency. For example, if you can do 100 IOPS with sub-millisecond latency, you may be able to achieve 200 IOPS if you accept higher latency. This is good to watch out for – sometimes the largest IOPS benchmark numbers are only possible with latency that would otherwise be unacceptable.
Cluster-wide aggregate IO latency, as measured at the same layer in Windows, is charted on the HCI Dashboard too.
Results
Any storage system that provides fault tolerance necessarily makes distributed copies of writes, which must traverse the network and incurs backend write amplification. For this reason, the absolute largest IOPS benchmark numbers are typically achieved with reads only, especially if the storage system has common-sense optimizations to read from the local copy whenever possible, which Storage Spaces Direct does.
With 100% reads, the cluster delivers 13,798,674 IOPS.
[caption id="attachment_9655" align="aligncenter" width="879"]
Industry-leading HCI benchmark of over 13.7M IOPS, with Windows Server 2019 and Intel® Optane™ DC persistent memory.[/caption]
If you watch the video closely, what’s even more jaw-dropping is the latency: even at over 13.7 M IOPS, the filesystem in Windows is reporting latency that’s consistently less than 40 µs! (That’s the symbol for microseconds, one-millionths of a second.) This is an order of magnitude faster than what typical all-flash vendors proudly advertise today.
But most applications don’t just read, so we also measured with mixed reads and writes:
With 90% reads and 10% writes, the cluster delivers 9,459,587 IOPS.
In certain scenarios, like data warehouses, throughput (in GB/s) matters more, so we measured that too:
With larger 2 MB block size and sequential IO, the cluster can read 535.86 GB/s!
Here are all the results, with the same 12-server HCI cluster:
| Run | Parameters | Result |
| Maximize IOPS, all-read | 4 kB random, 100% read | 13,798,674 IOPS |
| Maximize IOPS, read/write | 4 kB random, 90% read, 10% write | 9,459,587 IOPS |
| Maximize throughput | 2 MB sequential, 100% read | 535.86 GB/s |
Conclusion
Together, Storage Spaces Direct in Windows Server 2019 and Intel® Optane™ DC persistent memory deliver breakthrough performance. This industry-leading HCI benchmark of over 13.7M IOPS, with predictable and extremely low latency, is more than double our previous industry-leading benchmark of 6.7M IOPS. What’s more, this time we needed just 12 server nodes, 25% fewer than two years ago.
[caption id="attachment_9635" align="aligncenter" width="879"]
More than double our previous record, in just two years, with fewer server nodes.[/caption]
It’s an exciting time for Storage Spaces Direct. Early next year , the first wave of Windows Server Software-Defined (WSSD) offers with Windows Server 2019 will launch, delivering the latest cloud-inspired innovation to your datacenter, including native support for persistent memory. Intel® Optane™ DC persistent memory comes out early next year too.
We’re proud of these results, and we’re already working on what’s next. Hint: even bigger numbers!
Cosmos and the Storage Spaces Direct team at Microsoft,
and the Windows Operating System team at Intel
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.