Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Storage at Microsoft
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
access based enumeration abe
Android
Announcements
automated system recovery asr
Azure Edition
Azure IoT
Backup
biggerpoolthankanye
BitLocker
block blob
cau
client side caching csc
cluster aware updating
clustering
Cmdlets
completepc backup
Containers
continuous availability
data deduplication
data protection manager dpm
dedup
deduplication
dfsn
dfs namespaces
dfsr
dfs replication
disk defragmenter
disk management
diskspd
DPM
dynamic access control
encrypted file system efs
erasure coding
Events
failover clustering
faqs
fibre channel
file classification infrastructure fci
file replication service
File Server
file server resource manager fsrm
file services
file sharing in windows vista
file systems
frs
fsct
General
Hardware
hotfixes
hyper converged
hyper converged infrastructure
hyper v
Ignite
iOS
iPad
iSCSI
knowledge base kb articles
linux
lun
Management
microsoft most valuable professionals mvps
Migration
monitoring
multi resilient volumes
myths
Nano Server
network attached storage nas
network load balancing nlb
NFS
ntfs
offline files
Open Source
Pages
Performance
PowerShell
QoS
QUIC
raid
RDMA
redfish
refs
remote differential compression rdc
remote procedure calls rpc
reserved storage
s2d
scalability
scale out file server
SDK
SDS
Security
server clusters
server manager
shadow copies of shared folders
single instance store sis
SMB
smb 3 0
smi s
SMS
snia
software defined storage
SSL
Storage
storage area network san
Storage Explorer
storage management
storage manager for sans
Storage Migration Service
storage replica
storage server
Storage Spaces
Storage Spaces Direct
systeminsights
system restore
sysvol
team bio
testing
tlsv1 2
tools
universal disk format udf
user data management
validation
VDI
virtual disk service vds
Virtualization
vmfleet
VMM
volume shadowcopy service vss
vss
wan
webcasts and chats
Windows
Windows 10
Windows 7
Windows Admin Center
Windows Server
windows server 2008
windows server 2008 r2
windows server 2012
windows server 2012 r2
Windows server 2016
Windows Server 2022
Windows server backup
windows server technical preview
windows storage server 2012 r2
windows unified data storage server wudss
Windows Update
windows vista
windows vista backup
wmi
work folders
- Home
- Windows Server
- Storage at Microsoft
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed

10.9K

3,813
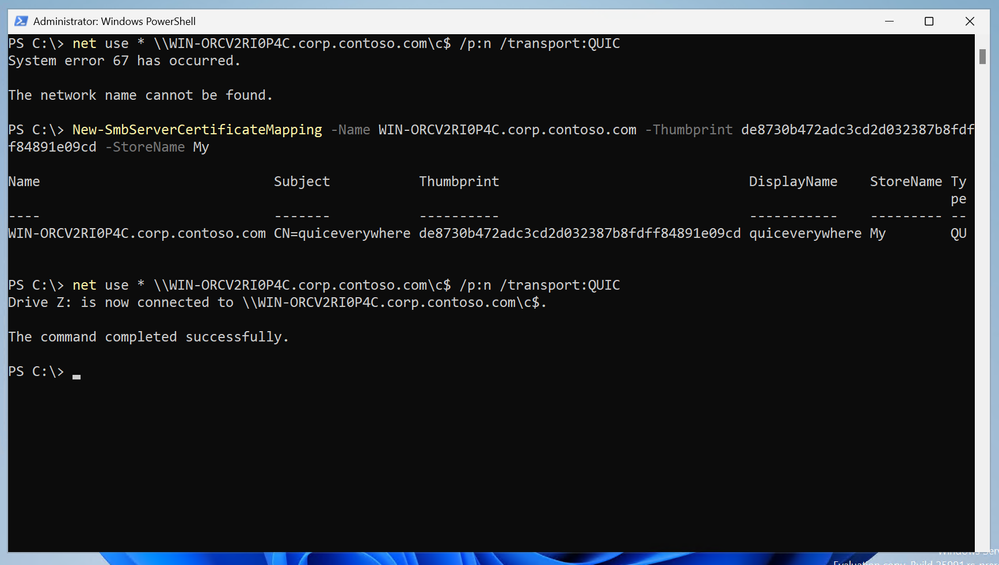
6,168

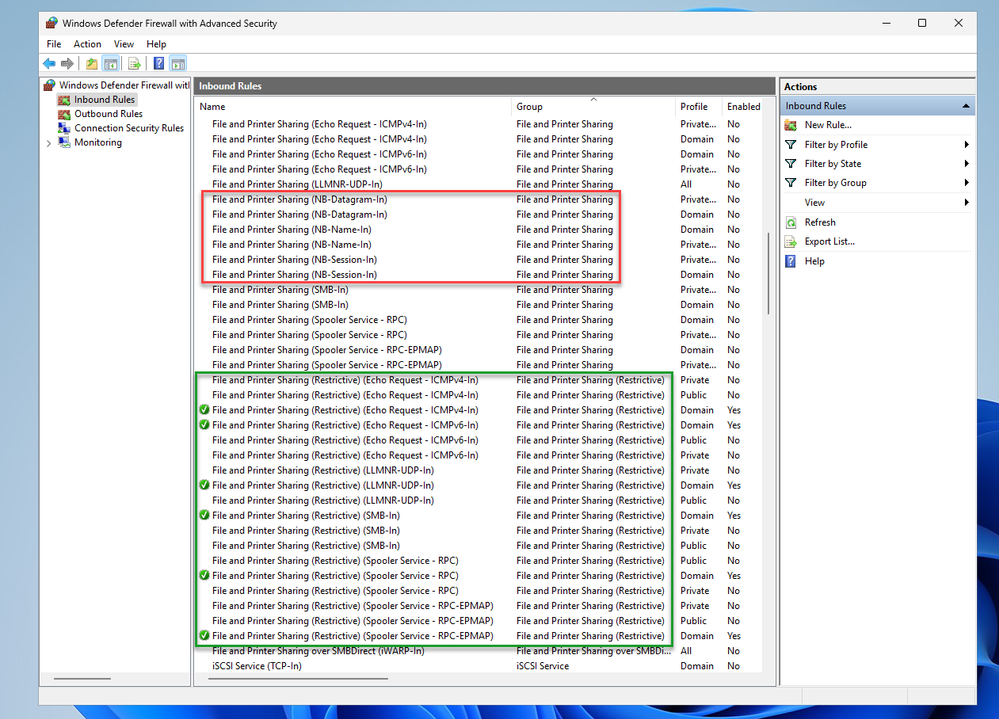

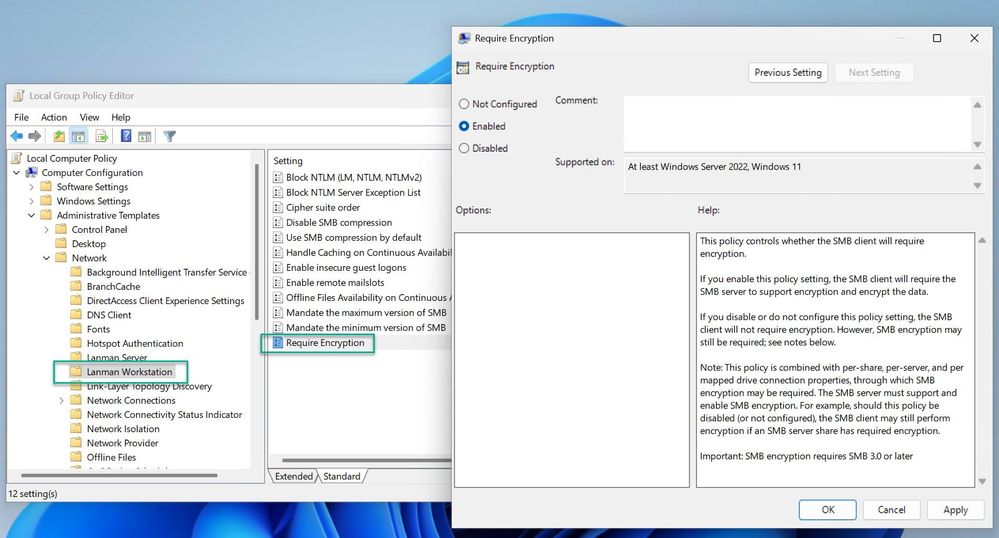
13.5K


12.3K
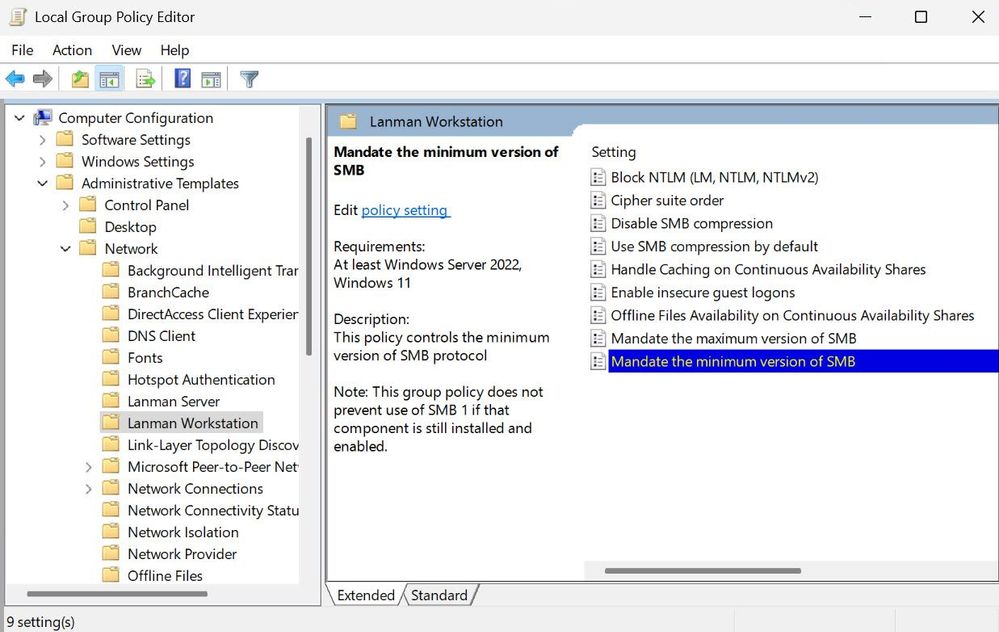



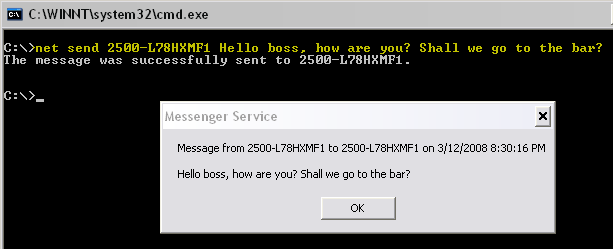
13.8K
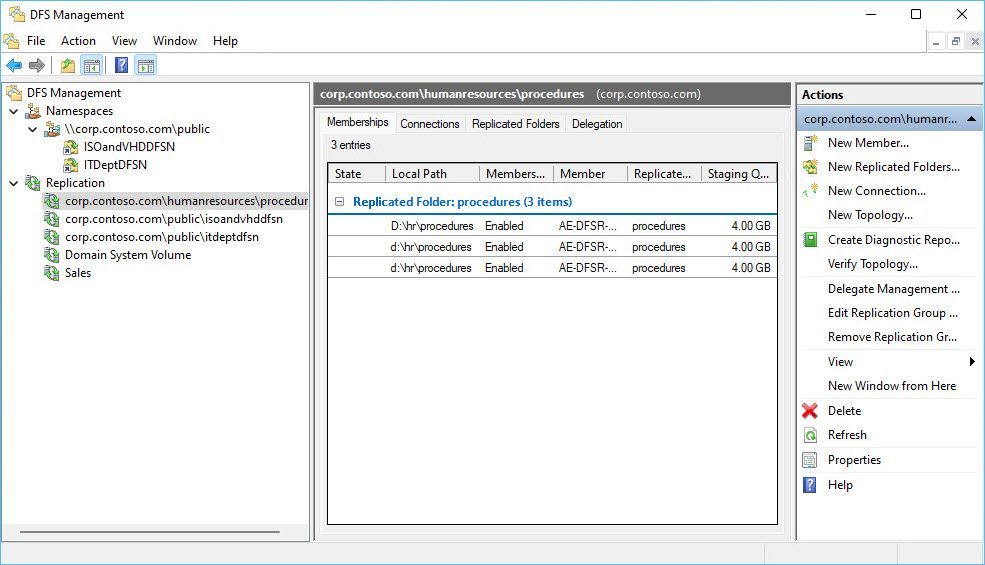
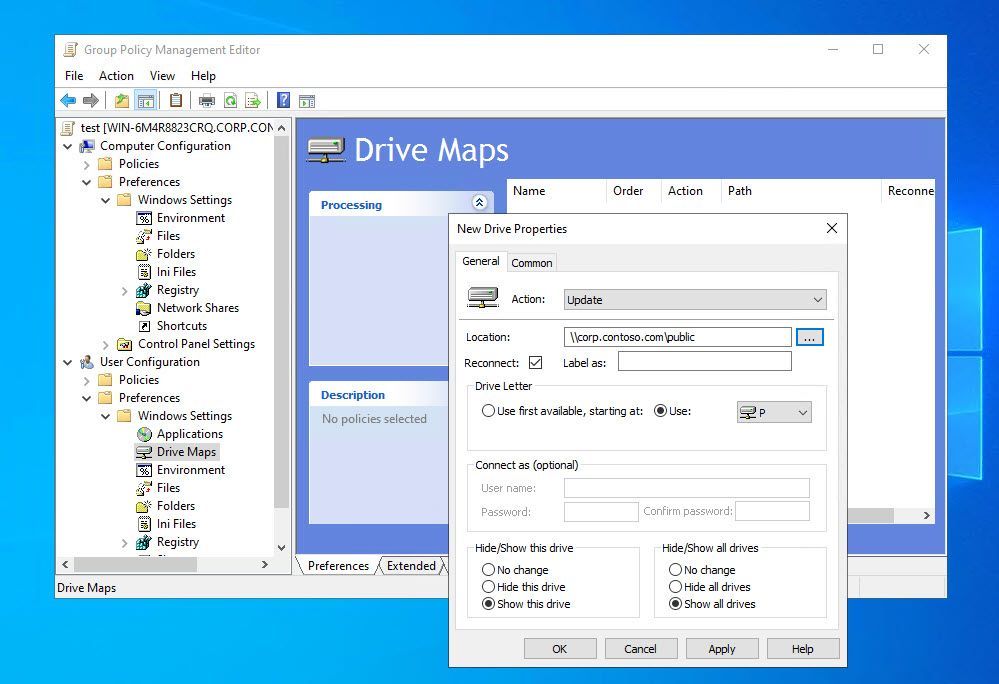

13.6K

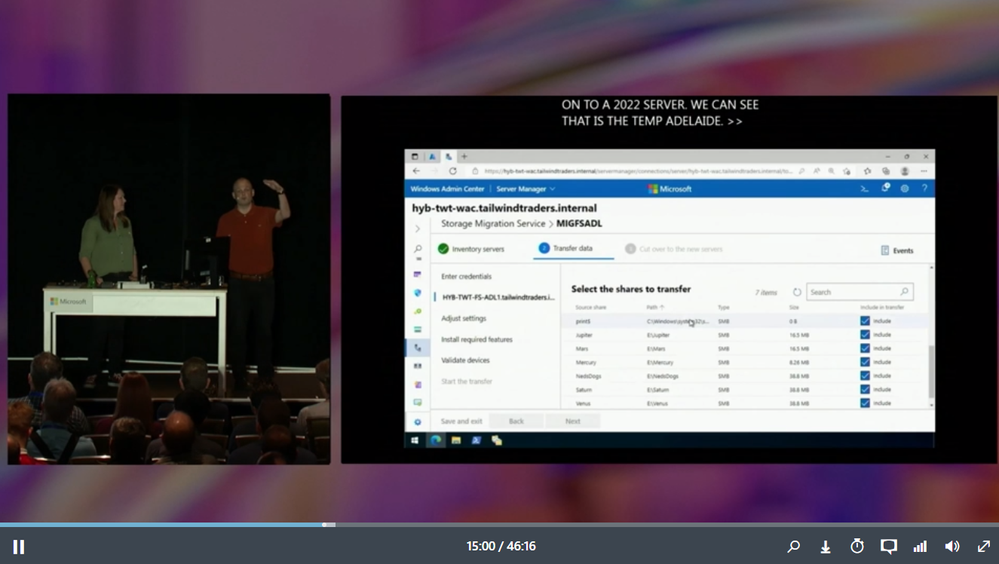
9,220
19.9K
6,147
Latest Comments