- Home
- Windows Server
- Storage at Microsoft
- Storage Replica versus Robocopy: Fight!
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Hi folks, Ned here again. While we designed Storage Replica in Windows Server 2016 for synchronous, zero data-loss protection, it also offers a tantalizing option: extreme data mover . Today I compare Storage Replica’s performance with Robocopy and demonstrate using SR for more than just disaster planning peace of mind.
Oh, and you may accidentally learn about Perfmon data collector sets.
In this corner
Robocopy has been around for decades and is certainly the most advanced file copy utility shipped in Windows. Unlike the graphical File Explorer, it has many options for multithreading, security, large files, retry, logging, and more. You’ve seen me use it with DFSR preseeding . It’s a great tool for IT professionals who want real control over moving files.
That said, it is still a user-mode file-level utility running at the very top of the stack. Windows Server 2016 Storage Replica is a kernel-mode, block-level filter system operating near the bottom of the stack. It only does one thing – copy blocks of data under a Windows volume - but it does it very well.
How well, though?
Heavyweight bout
I started by stealing borrowing a couple of 1.45TB Intel P3700 SSDs. I wanted that model for its solid-state consistency. It’s very fast and low latency, thanks to its NVME PCIe architecture. Moreover, it has excellent drivers and firmware.
To ensure that the network did not throttle my NVME disks, I grabbed Chelsio’s latest Terminator 5 40Gb RDMA cards. With two interfaces per server, SMB Direct and SMB Multichannel had 80Gb of ultra-low latency throughput – there was no chance that my NVME would run out of pipe, which is a real possibility on these drives.

I then snagged two servers that I knew wouldn’t give me unreasonable bottlenecks in memory or CPU. That meant a couple of whitebox 2Us, each with 16 cores of Intel Xeon E5-2660 at 2.2Ghz, and 256GB of memory. As Bill Gates once famously said to Scarlett O’Hara, “Frankly my dear, 256GB of RAM should be enough for anyone.”

“Don’t make me throw a sherry glass at you, Ned.”
Ahem.
Finally, I needed to come up with some tests that included various file and size characteristics. I generated my files using a combination of FSUTIL and an internal tool:
|
File Count
|
Size
|
|
1
|
1.45TiB
|
|
100,000,000
|
1KiB each
|
|
1,110,510
|
One million random 1KiB-1MiB in size, one hundred thousand 5MiB, ten thousand 10MiB, five hundred 1GiB, ten 10GiB
|
Now I was ready for Robocopy and Storage Replica to meet at the pinnacle of the crucible of the octagon of the ultimate mêlée on the field of peril, where second is the first loser and… you know, Richard Hammond metaphors.
There are a few ways to approach this kind of testing: you can measure time taken to complete and declare victory. You can also see system impact and resource utilization.
Let’s start simply.
Round 1 – A single huge file
I began with the single file test. To create this hulk, I ran:
Then I copied it several times using differing syntax. First:
These command-line parameters ensured that I copied the file metadata (security, attributes, etc.) as well as used the restartable option, ensuring that if the file copy failed mid-stream due to an interruption, I could pick up where I left off. Moreover, I didn’t need permissions to the file, thanks to the backup API call.
Then again, with:
The /j means unbuffered IO, which makes it much faster to copy very large files – only! Don’t use that with a bunch of tiny ones.
Then I split the difference with:
Finally, I enabled Storage Replica and replicated that whole 1.45TiB volume, with its single 1.45TiB file. Then I removed replication so that the destination volume remounted.
The results:
|
Technique
|
Time to complete
|
|
Robocopy /copyall /zb
|
2 hours, 48 minutes, 26 seconds
|
|
Robocopy /copyall /j /zb
|
2 hours, 38 minutes, 8 seconds
|
|
Robocopy /copyall /j
|
15 minutes, 23 seconds
|
|
Storage Replica
|
14 minutes, 27 seconds
|
Round 1 went to Storage Replica – not even close, except for robocopy /j, and then you must hope nothing interrupts my copy, which would mean starting all over again. Any interruption to SR just means it picks up where it left off, automagically.
Round 2
For my next test, I had 1.1 million files ranging from 1KiB to 10GiB, weighing in at 1.45TiB – a typical mixed bag of shared user data on a file server. This is where Robocopy should be in its element – not too many files and the files aren’t too small or too big.
You can see I added an extra set of cmdline options. One was to copy all the files in the single subfolder I created on my D drive, and the other was to enable multithreading and copy 128 files simultaneously – the maximum robocopy supports. I sent everything to a log file and stopped the screen output, which makes robocopy faster (really!)
The results:
|
Technique
|
Time to complete
|
|
Robocopy /s /copyall /zb /mt:128
|
25 minutes, 0 seconds
|
|
Storage Replica
|
14 minutes, 29 seconds
|
Round 2 went to SR , beating robocopy by nearly half the time. Spoiler alert: SR is very consistent in its performance on a given set of hardware. On these servers, it will always be around ~14.5 minutes unless some outside force acts upon it.
What was the performance like during all this, though?
I fired up Performance Monitor on the source server and created a User Defined Data Collector Set . This gets me Process, Processor, Memory, Disk, Network, and System performance data.

I ensured its stop condition was set long enough to capture the entire operation and let robocopy rip again. Then I ate a burrito. It’s a well-known constant that a proper burrito takes exactly 25 minutes to eat. It’s called Señor Nedo’s Law. You can look it up.
I started another run of the same data collector, but shortened it to 15 minutes, and examined the reports.

Uh oh
Robocopy looked angry. I cracked open the BLG from the report and look at the chart.
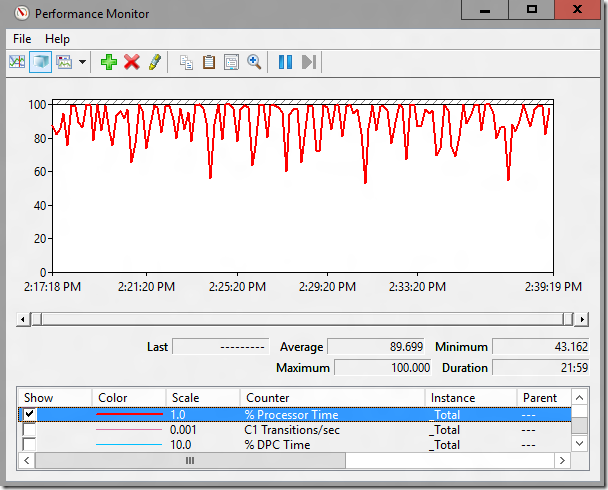
You’re getting your money’s worth on these processors, at least
To use a technical term, that is “dang near pegged”. How was Storage Replica looking during its run?
Oh yeah!
Not bad at all, it’s quite efficient on CPU thanks to operating in kernel.

Hello, Intel? I’d like to return some unused cores. Yes, I’ll hold.
That was the source machine. What did Storage Replica resource consumption look like on the destination?

The CPU was higher, but not much – in this case it averages 14%. The memory usage was much more aggressive than the source, as the destination is checksuming blocks for its bitmap during asynchronous initial sync. To perform that on an incredibly fast set of NVME storage, we need RAM. Storage Replica throttles at 50% of the total physical memory to ensure we don’t use too much. Robocopy doesn’t do this – depending on the copy characteristics in my three rounds of testing the source and destination server would use anywhere from 2% to 80%. Quite a bit of fluctuation on both nodes.
For comparison’s sake, when using some plain old hard disk drives, my memory usage dropped to around 20% used by Storage Replica. That’s spinning rust for ya – too slow to pressure the system. The future is solid state, dear reader.
Round 3
For my final test, I used one hundred million very small files, only 1KiB apiece. Remember, this is still the same 1.45TB drive. Meaning that Robocopy only had to copy 95GiB of data while Storage Replica had to copy more than 15 times as much data – every single block of that volume.

I feel like this picture should have Dr. Evil ‘shopped in
The results:
|
Technique
|
Time to complete
|
|
Robocopy /s /copyall /zb /mt:128
|
8 hours, 0 minutes and 12 seconds
|
|
Storage Replica
|
14 minutes, 23 seconds
|
Round 3 went to SR - understatement of the year! As you can see, SR was its usual 14+ minutes, but Robocopy was an all-day affair.
By the way, just like with round 2, CPU usage of robocopy with tiny files was gnarly and it was using a 25% of the RAM on the source and 64% on the destination at about an hour into the copy.

Robocopy source

Robocopy destination
In the end, depending on the files you were copying, SR should be gentler on CPU and perhaps even on memory than robocopy in many circumstances.
The winner by knockout
Storage Replica won. Sheesh. Didn’t you read the last three sections?
Down goes robocopy, down goes robocopy, down goes robocopy!
Here’s a roundup:
|
Technique
|
Data to copy
|
Time to complete
|
|
Robocopy /s /copyall /zb /mt:128
|
95GiB, 100M files
|
8 hours, 0 minutes and 12 seconds
|
|
Robocopy /copyall /zb
|
1.45TiB, 1 file
|
2 hours, 48 minutes, 26 seconds
|
|
Robocopy /copyall /j /zb
|
1.45TiB, 1 file
|
2 hours, 38 minutes, 8 seconds
|
|
Robocopy /s /copyall /zb /mt:128
|
1.45TiB, 1.11M files
|
25 minutes, 0 seconds
|
|
Robocopy /copyall /j
|
1.45TiB, 1 file
|
15 minutes, 23 seconds
|
|
Storage Replica
|
1.45TiB, the volume
|
14 minutes, 27 seconds
|
The kicker? I made it much easier for Robocopy than reality will dictate. Think about it:
- When I copied a file with robocopy /J, I could not use /ZB to gain resiliency; any interruption would force me to recopy the entire file all over again. The one and only time robocopy was almost as fast as SR, it was in the danger zone.
- I wasn’t making robocopy write through to disk in my tests; it was hitting a file server share with no clustering, meaning no Continuous Availability and always using cache. This gave robocopy an advantage in performance, at the expense of data resiliency. As you know from my previous blog post , robocopy would not write this fast to a share marked with CA. Storage Replica always hardens data to the disk.
- I didn’t introduce any users or apps into the tests. Robocopy might hit exclusively locked files if anyone was actually using the source machine, which would require retry attempts (note: consider DiskShadow as a potential workaround for this). Storage Replica operates beneath the file layer, where this is not an issue.
- I had no anti-virus software installed, where file scanning would have come into play. I won’t be mean to any anti-virus vendors here, but let’s all agree that you don’t use them for their performance enhancement.
- I wasn’t adding any more files! With Storage Replica, users can continue to add data that SR automatically replicates. You would need to run robocopy repeatedly for any new files.
The only realistic chance robocopy has to win? By copying a relatively small set of data from a very large volume. Even then, I could just shrink the volume temporarily, sync my data with SR, remove SR, then expand the volume. SR rides again!

Robocopy can be the right tool for the job. When moving a metric poop ton of data, SR may be better.
I’m no fool. I realize this requires you run our latest Windows Server 2016 preview build on both nodes, and you aren’t going to get such amazing numbers with terrible old HDDs and 1Gb Ethernet and 4GB of RAM. With that, now that you know the advantages of going all-in on our latest OS and its hardware capabilities when it releases, you have something to think about when you need to move some serious data.
Until next time,
- Ned “Sugar Ray” Pyle
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.