Building a dashboard on top of a web API with Power BI and Azure – Part 2
In Part 1 of this series we connected to the driveBC API in Power BI Desktop and built a simple dashboard. In Part 2 we will see how to design a more complete architecture capable of storing the data over time. In Part 3 we will implement that architecture.
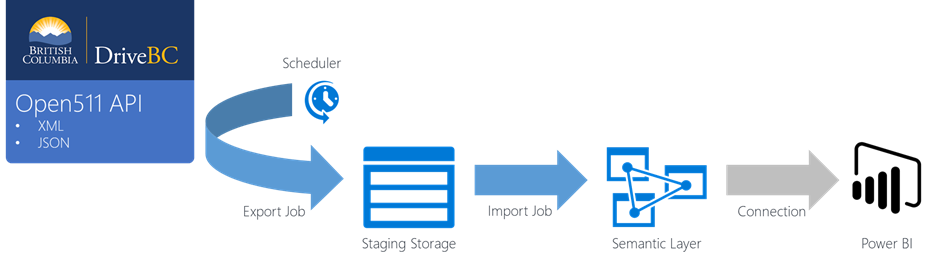
As we discussed in Part 1, one issue with the current architecture is that it doesn't store data over time. In order to enable that capability, we have to add storage to our solution. That storage will need to be updated regularly, on a schedule by a job capable of reaching out to the driveBC API and process the records properly. We will follow the best practices and keep these records as close as possible to their original format, and add a semantic layer to the solution. This semantic layer is just a model we will cast on our data so that it's easier to understand by our end users.
Since the data lives in the cloud, the best place to build our solution is the cloud. Microsoft Azure is a public cloud offering a wide range of integrated services, that we can easily combine into end-to-end solutions, making it an ideal environment to build our project.
The first step is to see which of these services we can use for each role of our architecture. Going over the documentation and experimenting a bit we can find the following candidates (compute, integration, databases, analytics - reference architectures):
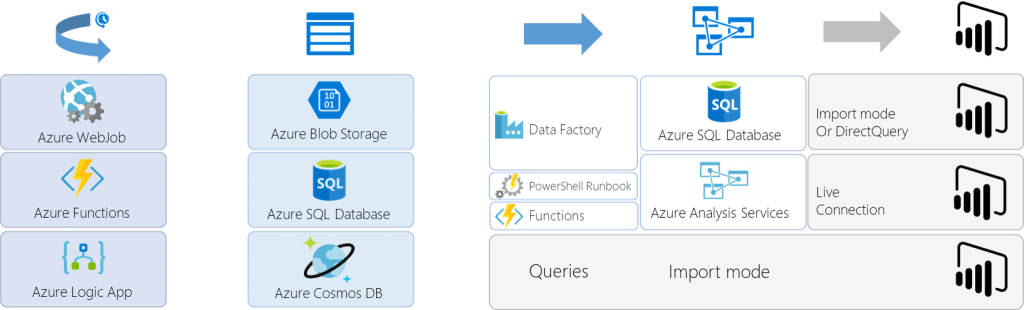
This allows us to separate the architecture into three independent areas so we can concentrate and identify which product best fits to each individual need.

- Export Job
- Complete comparison
- Azure WebJob (Web App)
- Pros: large choice of languages (C#, Python, Java, Node.js…), Visual Studio development experience
- Cons: separate scheduler, no in-browser development
- Azure Functions
- Pros: integrated scheduler, server-less architecture, in-browser development
- Cons: limited choice of languages at the time of writing (C#, Javascript)
- Azure Logic App
- Pros: integrated scheduler, in-browser drag and drop development, not code but workflow
- Cons: not a general-purpose programming language
For this specific architecture, I decided to use Logic Apps. I did build a WebJob in a first iteration, using C#, but decided to switch to Logic App to benefit from the integrated scheduler and the visual interface (for novelty, and being a BI developer and all…).
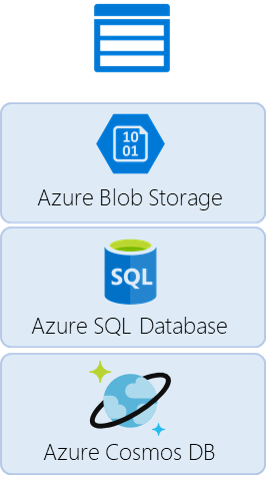
- Staging Storage
- Azure Blob Storage
- Massively-scalable storage for unstructured data
- Azure SQL Database
- Managed cloud SQL database
- Azure Cosmos DB
- Managed cloud NoSQL database
- Azure Blob Storage
Here the choice is based less on the capabilities of the storage system, and more on the format of the payload we need to store. In our case we are handling JSON documents and we want to limit the amount of processing we make in the export job. The best choice then is Cosmos DB which handles the format naturally. In Cosmos DB we will use the DocumentDB API, as it provides native JSON payload processing and SQL query capabilities.
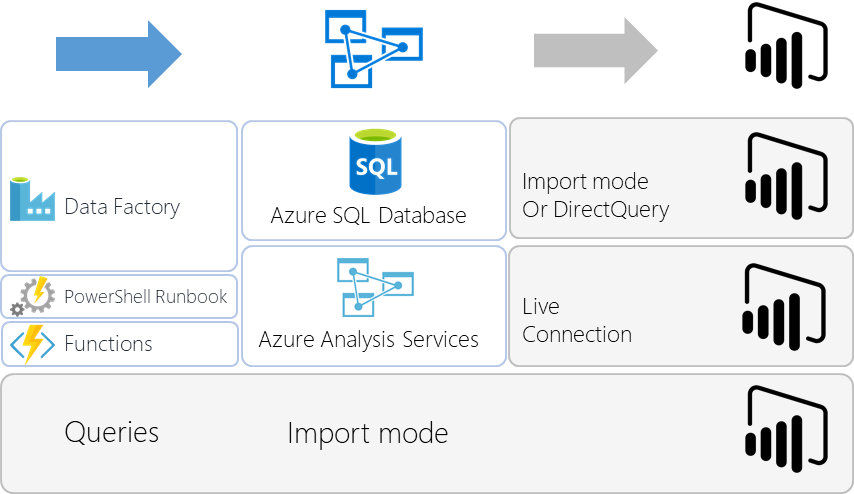
- Semantic Layer
- Azure SQL Database + Power BI Model
- If we were building a DataMart that needed to be shared across multiple semantic layers, we would store an intermediary copy in a SQL database
- Pros: shared ETL for all semantic layers (no code duplication)
- Cons: introducing another step of batch processing and another storage layer
- Azure Analysis Services
- When reaching large volume of data in Power BI, it is recommended to switch from import mode to using Analysis Services. Refreshed via Data Factory, PowerShell or Functions
- Pros: scalability, advanced administration capabilities, development experience
- Cons: too many moving parts for a simple prototype
- Power BI Model
- Connecting directly to Cosmos DB (DocumentDB) from Power BI Desktop, building a model there and publishing to the service
- Pros: the easiest to implement with less moving parts
- Cons: limited scalability, limited administration
- Azure SQL Database + Power BI Model
The best approach when experimenting is always to start simple, while knowing where to go to scale. Here the obvious answer is to start doing everything in Power BI, knowing that we will be able to migrate to Azure Analysis Services if we ever need.
Which makes our resulting architecture the following:

In the next part, we will look into the implementation of that architecture.