Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Core Infrastructure and Security Blog
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
AbhishekSharan
AbrarMuhib
Active Directory
AdamStasiniewicz
AdrianCorona
AKS
alanlapietra
AlexRadutskiy
AllenSudbring
AmerKamal
AndrePereira
AndrewCoughlin
AnilAbraham
AnooshSaboori
AnthonyMarsiglia
AnthonyWatherston
arnabmitra
arthurclares
AshleyMcGlone
AtilGurcan
Atil Gurcan
Azure
BasvanBennekom
BenjaminMorgan
BernieWhite
BillKral
BillSpears
BindusarKushwaha
BradWatts
BrandonMcMillan
BrandonWilson
BrentWhitlow
BrunoGabrielli
BryanZink
CameronCox
CarlosLopez
CarstenKinder
CenkIscan
ChadMunkelt
CharityShelbourne
ChiragShah
ChrisSchmidt
ChrisThompson
ChristianHeim
ChristopherScott
ChrisVetter
ChrisWallen
ChrisWeaver
ChuckTimon
CliftonHughes
CTO
Customer Offerings
DagmarHeidecker
DanCuomo
DanielMetzger
DannyGuillory
DarrenTurchiarelli
DaveGuenthner
DaveNewman
DavidGregory
DavidLoder
DavidMorgan
DenzilRibeiro
DougGabbard
DougSymalla
EdoardoZonca
ElizabethGreene
EricJansen
EricLong
EricWoodruff
EvanMills
FabianSick
FanyVargas
felipebinotto
GaryGreen
GraemeBray
GregJaworski
HeinrichGantenbein
helderpinto
HelmutWagensonner
herbertf
HoussemDellai
IngmarOosterhoff
JacobLavender
JakeMowrer
JamesKey
JamesKlepikow
JasminHashmani
JasonMcClure
JeffStokes
JenniferRoss
JerryDevore
JesseEsquivel
JimKelly
JimmyHarper
JJStreicherBremer
JoaoBotto
JoelVickery
JoeMcTaggart
JoeZinn
JohannesFreundorfer
JohnBarbare
JohnClyburn
JohnLam
JojiVarghese
JonasOhmsen
JonathanWarnken
JoshuaLent
KeithBrewer
KevinConan
KevinKelling
KhushbuGandhi
KrisTackett
KurtHudson
KyleBlagg
LakshmanHariharan
LijuVarghese
LionelPenuchot
LisaGardner
MAD
magdysalem
MarkMorow
MarkSerafine
MartinLucas
MattBalzan
MatthewReynolds
MatthewWalker
MatthiasHerfurth
MattNovitsch
MichaelBazarewsky
MichaelGodfrey
Michael Hildebrand
MichaelKoeppl
MichaelKullish
MichaelRendino
MicheleFerrari
MikeKammer
MikeKline
MorneNaude
NandanSheth
NathanPenn
NaveenKanneganti
NeilBird
NicholasJones
Noteworthy News
PaddyDamodharan
PaulBergson
PaulHarrison
PaulIvey
PKI
PrestonParsard
RalphKyttle
RandyReyes
RandyTurner
RayZabilla
RicardoCarvalho
RickBergman
RickCastillo
RickSasser
RickSheikh
robertlightner
RobertSmith
RodTrent
RogerOsborne
RomainCasteres
RonGrzywacz
RussRimmerman
RyadBenSalah
RyanAdams
SairaShaik
SantosMartinez
ScottKissel
SeanGreenbaum
SeanLeonard
SebastianGernert
SergeZuidinga
SethPrice
SimoneFrigerio
SQLPFE
SrinivasVarukala
StanislavBelov
StefanRoell
StephenMathews
SteveMathias
SteveRachui
TajMohammed
TanTran
ThomasStringer
TimBeasley
TimChapman
TimMedina
TochiEzebube
TomAusburne
TomMoser
VenkatKalyanasundaram
VictorZapata
wernerrall
WesHammond
WillAftring
ZohebShaikh
- Home
- Security, Compliance, and Identity
- Core Infrastructure and Security Blog
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed
7,818
2,680


4,551
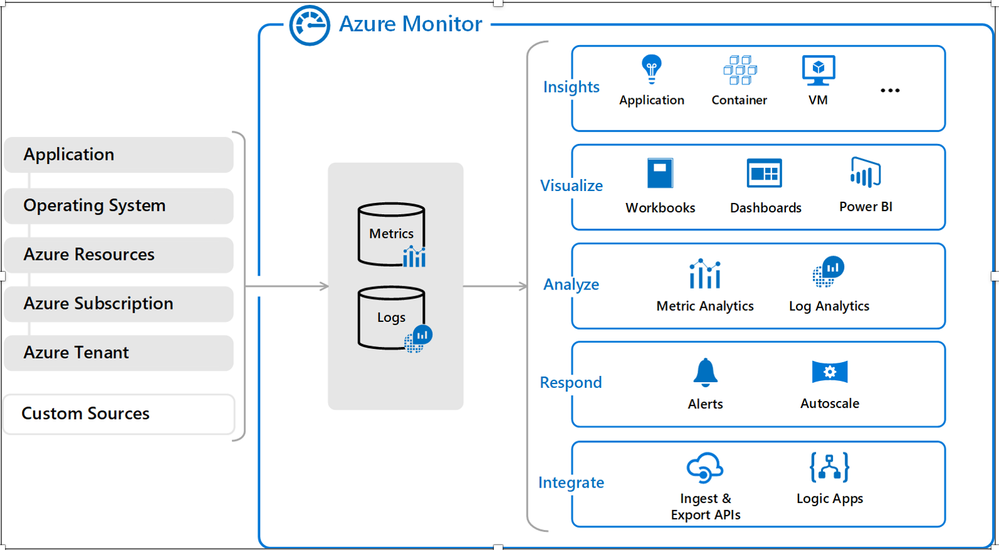

2,014

14.7K



13.1K

24.4K


2,730



5,280

5,420


6,686



5,853


8,466
Latest Comments