Generate random content for SharePoint - 2
This is the second chapter of the Generate Random Content For SharePoint series. Yes, it turns out to be a series, as I was not 100% satisfied with what I've written in the previous post.
Chapters:
- Generate random content for SharePoint - About how to create big files for upload testing.
- Generate random content for SharePoint 2 - About how to generate Word files for Search and integration testing. (This article.)
- Generate random content for SharePoint 3 - About how to generate Excel files for Search and integration testing.
- Generate random content for SharePoint 4 - About how to generate PowerPoint files for Search and integration testing.
(If you don’t want to read through all the drama, jump directly to the Falling Action section.)
Exposition
So in my previous post I explained how to create random big files for upload testing. Part of the solution was that the content gets uniquely indexed. This made me thinking though. Biggest problem is, that even though I've used GUIDs to generate the content, and these GUIDs would be indexed individually, this does not smell like real life. Why not? Simply because who on earth would search for massive number of GUIDs? Also, this will have an impact on the Index component, as there will be no duplicates in there, so it falsifies the numbers in various ways.
So how could one create random content that makes a bit more sense than this one?
Rising Action
Act 1
Those who have read my previous post around the topic, or are familiar with Word know well, that there is the famous =rand(x,y) function. In previous versions of Word the function generated a text starting with:
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
The Word 2016 however is using an English text beginning with:
Video provides a powerful way to help you prove your point.
Now this would do, you might say, but I still have a problem with it, as there is a repeating pattern in the text. As a matter of fact, Word is generating 239 words, 1,063 characters (1,301 with spaces), then starts repeating it. as many times as you instructed it with the above function. Still far from smelling real life.
I could use an English corpus from the Internet. There are plenty available, some are for money, some might be free for use. Sounds good, but I might bounce into some licensing issues, so I thought to myself, why not creating a script, that is using words of the English language (or in fact any other language) to generate random content with it. Of course the text in it will be gibberish, since we're putting random words next to each other, but it would be way closer to real life than simply using the GUIDs. Wouldn't it? Yes, it would.
Where can I get a list of all the English words? If you are reading this article, then you most probably are familiar with this thing called the Internet. A simple query for the term "list of English words download" in your favorite search engine will give you loads of results. Also, if you query for other languages, with a few minutes of browsing you'll find similar downloads.
Act 2
I was so excited that things like this (that is a list of all English words) are available on the internet. I thought maybe there are corpuses available for analysis. (Yeah, if I would be a linguist, this would probably be obvious, but since I am not...) I assume you already guessed there are. So out of mere curiosity I ran a quick query against the ONAC (Open American National Corpus) database to see the separator statistics. You know, to know how many spaces and periods and so on you have in a text. This is what I've found:
| Punctuation mark | Ratio |
|---|---|
| Space | 87.5819 |
| Full stop | 3.7542 |
| Comma | 3.9734 |
| Colon | 0.2435 |
| Semicolon | 0.1832 |
| Apostrophe | 1.6572 |
| Exclamation mark | 0.0342 |
| Question mark | 0.1124 |
| Doublequotes | 0.7048 |
| Hyphen | 1.7455 |
| Underscore | 0.0098 |
Interesting, isn't it. How would this come handy? Well... The SharePoint search infrastructure could be used for a lot of things. You could drag statistics, modify relevancy, results sets, etc. Would it not be nice to have this incorporated in our document? I though it would.
What would be the best way to randomly choose a punctuation mark based on their weight in the above table. Maybe there are other ideas as well, as for me, I've chosen to create a file that contains 10,000 rows, each containing one of the punctuation marks. For example it would have 8,758 rows with space, 375 full stop, etc. To support other languages, I've created a script that would create such a separator file, you just need to use the parameters with the ratio of your choice. (See the Falling Action section below.)
Climax
Act 3
So I have a corpus, I have a file that contains the punctuations as separators. Next question is, how to choose items from them randomly? I'm still using PowerShell, so I asked my fried Daniel Vetro, what would be the best way. He came up with a really elegant solution:
$DictionaryFile = Get-Content '.\words_en.txt'<br>$DictionaryFile | Get-Random
Tiny little problem, that this turned out to be slow. Run it against a corpus of 500,000 words and you'll find that generating documents of 82,000 words will take just too long. So I had to go back to the basics and use the "good old" addressing of arrays. Something like this:
$DictionaryFileRows = $DictionaryFile.Count<br>$RandomWordLine = Get-Random -ProviderName 1 -Maximum $DictionaryFileRows<br>$RandomWord = $DictionaryFileContent[$RandomWordLine]
Act 4
Awesome. So now that we are able to randomly choose words and separators, we should put them into a document. Obviously PowerShell cannot create a Word file directly (well, technically it could as a DOCX is a ZIP file after all, but the structure and the content would be a bit too complicated) , but we have COM Objects that we can address. Something like this:
$WordApplication = New-Object -ComObject "Word.Application"<br>$WordDocument = $WordApplication.Documents.Add()<br>$WordSelection = $WordApplication.Selection<br>$WordSelection.InsertAfter($RandomWord)<br>$WordSelection.InsertAfter($RandomSeparator)
Too easy to be true, right? Right. It is too easy to be true. Just as earlier, it technically works. It is just slow like hell. A document with 120 words creates in about a minute. Go up to some thousand words and you sit there for hours. Not really what one would be looking for...
Luckily the Above COM object allows inserting a whole set of words. So we could create a long string, then add that to the Word document:
[string]$LongString = ''<br>For($i=1; $i -le $WordCount; $i++)<br>{ $RandomWordLine = Get-Random -Minimum 1 -Maximum $DictionaryFileRows $RandomWord = $DictionaryFileContent[$RandomWordLine] $RandomSeparator = $Separators[(Get-Random -Minimum 0 -Maximum $($Separators.Count))] $RandomWord = $RandomWord + $RandomSeparator $LongString = $LongString + $RandomWord<br>}<br>$WordSelection.Select()<br>$WordSelection.Delete()<br>$WordSelection.InsertAfter($LongString)
Act 5
Now we know how to generate random words, put random separators afterwards, and how to put it into a Word document. But is there more we could do. Of course there is. Remember that the SharePoint Search results have a few nice built-in refiners?
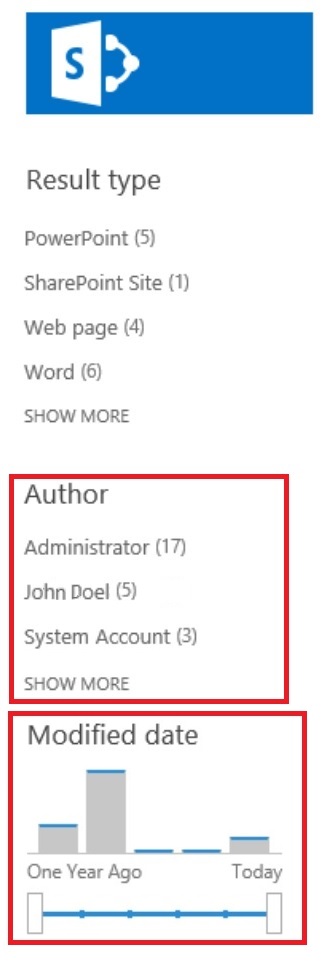
These refiners are coming from the document's property bag. Some part of this property bag is being updated by system automatically, another part manually by the actual users. The information is being saved within the DOCX file.
Would it not be great if we could somehow hack into that property bag and update something? I don't know, maybe fake who created or last modified the document? That would definitely give us something to play with in the search results...
Now, for those of you who wouldn't know, an Open Office XML file is technically a ZIP file with a nice little structure and a bunch of XML files. The structure looks like this:
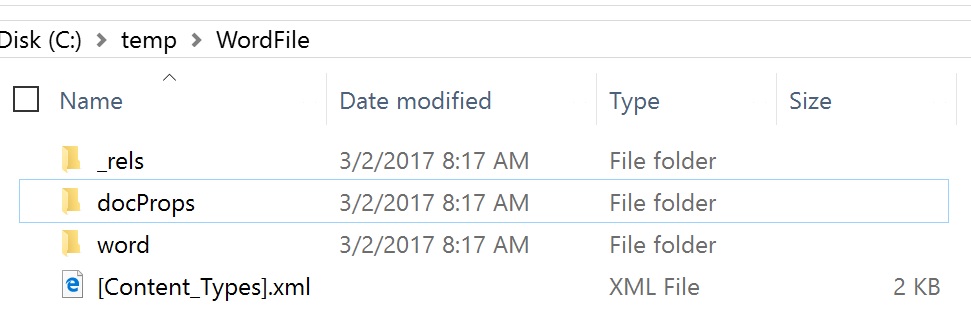 and
and 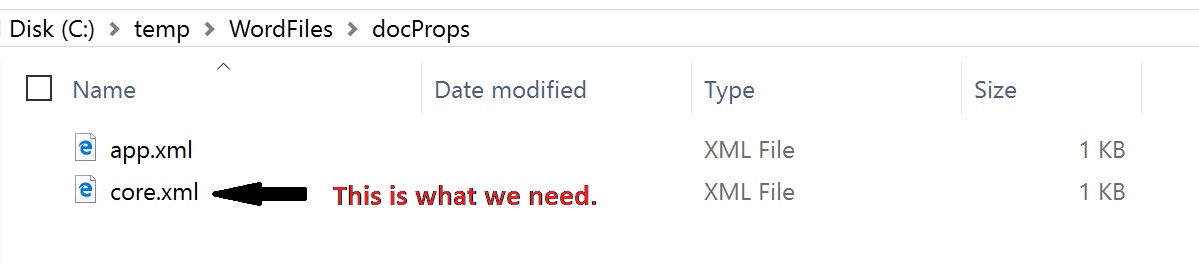
When you open the XML file you should see something like this:
<?xml version="1.0" encoding="UTF-8" standalone="true"?>
<cp:coreProperties xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xmlns:dcmitype="https://purl.org/dc/dcmitype/ " xmlns:dcterms="https://purl.org/dc/terms/ " xmlns:dc="https://purl.org/dc/elements/1.1/ " xmlns:cp="https://schemas.openxmlformats.org/package/2006/metadata/core-properties">
<dc:title/>
<dc:subject/>
<dc:creator>Zsolt Illes</dc:creator>
<cp:keywords/>
<dc:description/>
<cp:lastModifiedBy>Zsolt Illes</cp:lastModifiedBy>
<cp:revision>3</cp:revision>
<dcterms:created xsi:type="dcterms:W3CDTF">2017-03-02T07:17:00Z</dcterms:created>
<dcterms:modified xsi:type="dcterms:W3CDTF">2017-03-02T07:17:00Z</dcterms:modified>
</cp:coreProperties>
So what do we need to know about the above structure?
- The creator and lastModifiedBy fields should be presented in SIP format, so that the presence information
- The created and modified fields are in Sortable Time Format.
Thus what we need is two files; one that contains a list of people, and another one that contains the dates. Getting random data from these two files works just as we learned above. We - however - might wish to make sure that the time of modification is at least the same or later than the time of creation. Somehow like this:
$RandomDateNr = Get-Random -Minimum 0 -Maximum $DatesCount<br>$RandomDate = $DatesList[$RandomDateNr]<br>$CoreXML.coreProperties.created.'#text' = $RandomDate.ToString()<br># Here we need a trick, as we have to make sure the last modifed<br># date is not earlier than the date creation. (This is why we ordered the list.)<br>$RandomDateNr = Get-Random -Minimum $RandomDateNr -Maximum $DatesCount<br>$RandomDate = $DatesList[$RandomDateNr]<br>$CoreXML.coreProperties.modified.'#text' = $RandomDate.ToString()
Now, because - as we already discussed - a DOCX file is just a ZIP, we could simply write into them and update the core.xml file directly.
$WordFile = [System.IO.Compression.ZipFile]::Open( $WordFilePath, 'Update' )<br>$ZippedCoreXMLFile = [System.IO.StreamWriter]($WordFile.Entries | Where-Object { $_.FullName -match 'docProps/core.xml' }).Open()<br>$ZippedCoreXMLFile.BaseStream.SetLength(0)<br>$ZippedCoreXMLFile.Write($Script:CoreXML.OuterXml)<br>$ZippedCoreXMLFile.Flush()<br>$ZippedCoreXMLFile.Close()<br>$WordFile.Dispose()
Falling Action
Act 6
We have everything now to put the solution together.
- Dictionary for words,
- Separator list,
- A list for users and dates to update the document properties,
- and a nice way to push all this information into a Word document directly.
- I've not detailed it in this article, but my solution also contains a routine to use a pre-defined Word file template. This might come handy if you want to fine tune your search experience even more. (Just think about search driven solutions for example.)
The scripts are still available on Codeplex (link). Of course this solution still has room for improvement, but that is up for you guys to play with.
Dénouement
With these files on your environment you can test your search infrastructure in a near-life scenario.
Stay tuned for the next episode of the series where I detail the challenges with creating Excel files. In the same way. Then another one to create PowerPoint presentations.