Issues while assigning static IP Address with Windows RRAS using DOD (Dial on Demand) Interface
1. Introduction
This article is based on a support incident that I worked back on the Platforms day. It was originally published in Portuguese and since it is really interesting I decided to also publish here in my blog. The scenario is the one below:
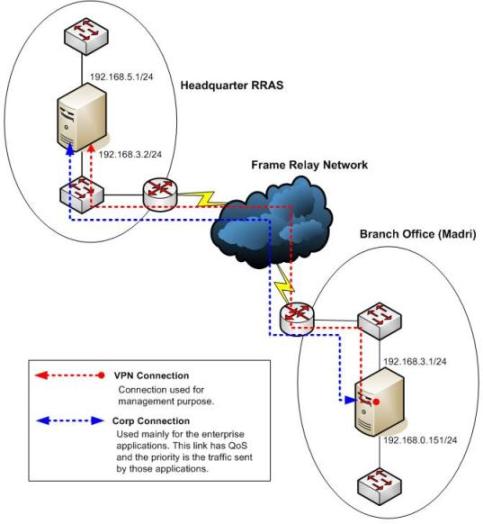
Figure 1 – Network Topology used in this case.
In this scenario the branches connected to the headquarter using a Frame Relay link with a dedicated router on each side. The Windows Server 2003 RRAS Server was used in this case because the customer wants to create a dedicated connection between those servers for management purpose. For each branch the customer created a user account in the domain controller located on the headquarter. Each account will represent the location where the server is (for example: Dallas, Austin, Madri etc).
The DOD connection on the branch office is using a dynamic IP address and the DHCP Server is located in the Headquarter. The RRAS Server in the branch office will obtain the IP address from the headquarter, but customer wants to control which IP will be used for each location. Then you might ask: if he wants to control the IP, why doesn’t he use a static IP address? The answer for that is: he wants to use static IP per location, but using dynamic IP address assignment. Customer wants to take advantage of one feature that exists on AD that allows you to assign an IP address for one specific account.
The reason behind that is: customer wants to be able to know what IP each location will have, however if he needs to change the IP for some reason he doesn’t need to go to the location and change it there manually. All the control will be done in the DC located in the headquarter.
During the implementation of these servers customer notices the following problem:
- When the administrator, physically located in the headquarter tried to RDP (Remote Desktop) to one server in the branch office using the IP that was assign to that location, the remote desktop was establishing the connection to another server from another location. Customer than realize that the static address assignment was failing, although the DOD connection in the branch office was correctly connected. Customer also notices that this behavior happened for some branches that were temporarily losing connection with the Headquarter.
The question than was: why, even using the static address assignment in the user’s properties, the server is getting a different IP while connecting using DOD with that user account?
2. Preparing the Environment to Obtain Data
To prepare the environment to obtain the correct information when the issue happens the following actions were done:
· Enable all RRAS logs using the command: netsh ras set tracing * enable
· Enable Netmon in both interfaces (RRAS on the Branch and in the Headquarter)
3. Analyzing the Data
After capture the data while the issue was happening it was possible to determine what was happening. But before show the logs, it is important to clarify some parameters of this configuration. Here is the connection’s properties for RRAS Server that starts the connection:
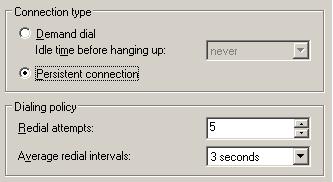
Figure 2 – Properties of the DOD connection on the Branch (Madri).
As you can see above, the redial interval is 3 seconds, which means that if the branch office cannot establish the connection it will try again in 3 seconds.
For this example, we are going to use the properties of the Madri’s account and check if the IP is correctly configured there:
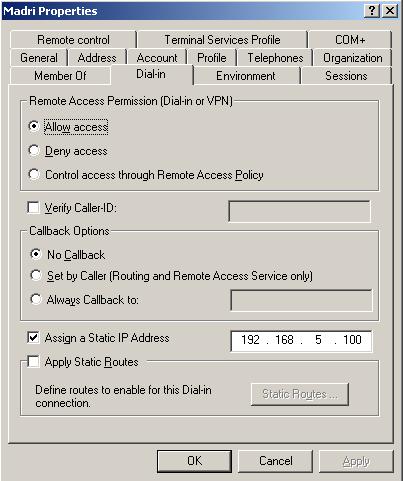
Figure 3 – Madri’s account in the DC located in the Headquarter.
As you can see, the Madri’s RRAS server establish the connection with the head quarter’s RRAS server it will receive the IP 192.168.5.100. Knowing that, we star t to review the data for an issue that happened on that location, around 7:12. At that time, this location lost connectivity with the Headquarter and then try to re-establish the connection in 3 seconds.
Reviewing the file RASIPHLP.LOG located in the head quarter’s RRAS server it was possible to see exactly the moment that the server tried to re-connect:
[2384] 02-20 07:15:09:506: RasSrvrAcquireAddress(hPort: 0x82, IP address: 0x6405a8c0, UserName: Madri, PortName: VPN4-126)
[2384] 02-20 07:15:09:506: rasSrvrGetAddressForServerAdapter
[2384] 02-20 07:15:09:506: Address 0x6405a8c0 is already in use
[2384] 02-20 07:15:09:506: RasDhcpAcquireAddress
[2384] 02-20 07:15:09:516: RasSrvrActivateIp(IpAddr = 0x6505a8c0, dwUsage = 0)
[2384] 02-20 07:15:09:516: RasTcpSetProxyArp(IP Addr: 0x6505a8c0, fAddAddress: TRUE)
[2384] 02-20 07:15:09:516: rasSrvrGetAddressForServerAdapter
The IP address that shows up above (0x6405a8c0) is exactly the one that we have for this server (192.168.5.100). To find out that use the following logic:
· Hexadecimal address that appears in the log = 0x6405a8c0
· Hexadecimal address inverted and separated by two digits = c0 a8 05 64
· Converting the hexadecimal address in decimal = 192.168.5.100
So, this piece of log pretty much says:
- At 7:15:09, the IP address 192.168.5.100 is already in use and therefore cannot be assigned. To fix that the address 0x6505a8c0 (192.168.5.151) was assigned.
Now let’s see why the head quarter’s RRAS server believes that this address is in use.
4. Understanding the Behavior
The conclusion here is that the Branch’s RRAS Server is redialing faster than the headquarter’s RRAS server takes to understand that the connection is down and release the IP. The default configuration for the RRAS service can takes between 2 and 3 minutes (for more information on those timers review the KB262990) to calculate that and release the connection.
4.1. But why the connection is dropped?
After identify the reason why this behavior was happening, customer wants to know why those branches were having that temporally disruption many times during the day.
Using a sample capture from one of the locations we could figure that out. On the netmon capture, around 8:20, it was possible to see that both servers (RRAS) were correctly exchange control packages:
8:19 192.168.3.2 192.168.3.1 PPTP PPTP: Control Message , Echo Request
8:19 192.168.3.1 192.168.3.2 PPTP PPTP: Control Message , Echo Reply
At exactly 8:20 we have the following event on the RASMAN.LOG:
[1992] 02-20 08:20:43:284: d:\nt\net\rras\ras\rasman\rasman\util.c 1997: Disconnected Port 252, reason 1. rc=0x0
Right after that we have the following event on the RASTAPI.LOG:
[1992] 02-20 08:20:43:284: PortTestSignalState: DisconnectReason = 2
On the file RASMANI.LOG we have the reason why the connection was dropped, in this case reason 1 (HARDWAREFAILURE) and in the RASTAPI.LOG the reason was 2 (LINKDROPPED). With that we can conclude that something on the link layer happened that leads to the disconnection. It could be a problem on the ISP, on the channel where this connection passes through, the active component that is in front of the RRAS Server, in another words: something in link layer area. On the netmon trace we can see that we stay more than one second without connectivity and then, at 8:21 we re-connect:
- We initiate the ARP Request:
8:21 192.168.3.1 192.168.3.1 ARP ARP: Request, 192.168.3.1 asks for 192.168.3.1
8:21 192.168.3.1 192.168.3.2 ARP ARP: Request, 192.168.3.1 asks for 192.168.3.2
8:21 192.168.3.2 192.168.3.1 ARP ARP: Response, 192.168.3.2 at 00-03-FF-0F-2B-29
- Then we have the TCP 3 Way Handshake for PPTP (TCP 1723):
8:21 192.168.3.1 192.168.3.2 TCP TCP: Flags=.S......, SrcPort=1149, DstPort=1723, Len=0, Seq=3777429460, Ack=0, Win=65535 (scale factor 0) = 65535
8:21 192.168.3.2 192.168.3.1 TCP TCP: Flags=.S..A..., SrcPort=1723, DstPort=1149, Len=0, Seq=1936732946, Ack=3777429461, Win=16384 (scale factor 0) = 16384
8:21 192.168.3.2 192.168.3.1 TCP TCP: Flags=....A..., SrcPort=1723, DstPort=1149, Len=0, Seq=1936733135, Ack=3777429809, Win=65187 (scale factor 0) = 65187
- Finally we have the PPTP connection being established:
8:21 192.168.3.1 192.168.3.2 PPTP PPTP: Control Message , Start Control Connection Request
8:21 192.168.3.2 192.168.3.1 PPTP PPTP: Control Message , Start Control Connection Reply
8:21 192.168.3.1 192.168.3.2 PPTP PPTP: Control Message , Outgoing Call Request
8:21 192.168.3.2 192.168.3.1 PPTP PPTP: Control Message , Outgoing Call Reply
8:21 192.168.3.1 192.168.3.2 PPTP PPTP: Control Message , Set Link Info
5. Conclusion
As I mentioned before, the KB262990 explains the timers involved here. It is possible to adjust the time that the RRAS will check if the link is idle, this is called InactivityIdleSeconds and can be changed on the registry key below:
HKEY_LOCAL_MACHINE\SYSTEM\CCS\Control\Class\{4d36E972-....}\instanceid
The default value is 60 seconds, if you reduce this value to 1 the RRAS service can take between 30 to 45 seconds to detect that the PPP link is down.
There is another parameter called DefaultIdleTimeout that you also can use to control the idle time. Here the registry location:
HKLM\SYSTEM\CurrentControlSet\Services\RasMan\PPP
This is a global parameter that will affect all PPP connections, so you need to be careful when you change that.