Getting system topology information on Windows
On Windows Server 2008 and later, applications can programmatically get information about how the underlying hardware components relate to one another. Examples include spatial locality and memory latency. This article describes how developers can get the system topology information and use it to build scalable solutions on multi-processor and NUMA (Non-Uniform Memory Architecture) systems.
To start things off, the following is a refresher of some definitions that will be used throughout the article:
Term |
Definition |
Affinity Mask |
A bitmask specifying a set of up to 64 processors. |
Core |
A single physical processing unit. It can be represented to software as one or more logical processors if simultaneous hardware multithreading (SMT) is enabled. |
Hyper-threading |
Hyper-Threading Technology (HT) is Intel's trademark for their implementation of the simultaneous multithreading technology. |
Logical Processor (LP) |
A single processing unit as it is represented to the operating system. This may represent a single physical processor or a portion of one. |
Node |
A set of up to 64 processors that are likely in close proximity and share some common resources (i.e., memory). It is usually faster to access resources from a processor within the node than from a processor outside of the node. |
Proximity Domain |
A representation of hardware groupings, each with a membership ID. Associations are only made to processors, I/O devices, and memory. The HAL provides information about processors and memory proximity domains through its interface. |
From an application’s perspective, a physical system is composed of three components, Processors, Memory, and I/O devices. These components will be arranged into one or more nodes interconnected by an unknown mechanism. The following figure is one type of configuration:
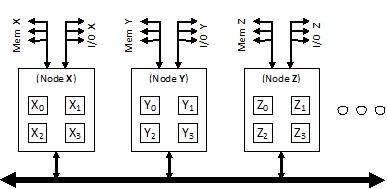
In this example, each node contains four processors shown by squares: Node X contains processors X0, X1, X2, and X3. Other systems may have a different number of processors per node, which may be multiple packages or multiple cores on the same physical package. Attached to each node is a certain amount of memory and I/O devices. An application can programmatically identify where the different pieces of hardware are, how they relate to one another, and then partition its I/O processing and storage to achieve optimum scalability and performance.
Application Knowledge of Processors
Applications can determine the physical relations of processors in a system by calling GetLogicalProcessorInformation with a sufficiently large buffer that will return the requested information in an array of SYSTEM_LOGICAL_PROCESSOR_INFORMATION structures. Each entry in the array describes a collection of processors denoted by the affinity mask and the type of relation this collection holds to each other. The following table outlines the type of possible relations:
Value |
Meaning |
RelationProcessorCore (0) |
The specified logical processors share a single processor core, for example Intel’s Hyper-Threading™ technology. |
RelationNumaNode (1) |
The specified logical processors are part of the same NUMA node. (Also available from GetNumaNodeProcessorMask). |
RelationCache (2) |
The specified logical processors share a cache. |
RelationProcessorPackage (3) |
The specified logical processors share a physical package, for example multi-core processors share the same package. |
An application may be only interested in which processors belong to a specific NUMA node so it can schedule work on these processors and improve performance by keeping state in that NUMA node’s memory. The application may also want to avoid scheduling work on processors that belong on the same core (e.g. Hyper-Threading) to avoid resource contention..
Application Knowledge of Memory
An application may also be interested in knowing how much memory is available on a specific NUMA node before deciding to make allocations. Making a call to GetNumaAvailableMemoryNode will provide this kind of information. An example might be an application interested in keeping data its threads are working on (e.g. some sort of a software cache) in memory that belongs to the same node hosting the processors to which the threads have their affinities set. This way, when the data is not resident in the processor’s cache, the cost of reading and writing to the data in local memory is less expensive than accessing remote memory from another node. When it is time to make the allocation, Windows provides the VirtualAllocExNuma API that takes in a preferred node number as parameter for determining in which node the application would like the memory to reside. This is an example of an application choosing to allocate memory from a specific node.
Application Knowledge of Devices
Every driver loaded on the system has an associated interface that it supports and registers when the driver starts. Storage and networking drivers are common examples.
By calling SetupDiGetClassDevs, an application sets up a list of devices supporting a particular interface and calls SetupDiEnumDeviceInfo to enumerate through the list and get a specific device entry. Once an application knows which devices it is interested in, it can then use the device properties to identify how a particular device relates to other components in the system like processors and memory.
1) Call SetupDiGetDeviceRegistryProperty requesting DEVPKEY_Numa_Proximity_Domain.
2) If a device does not have this property, then move to that device’s parent. Repeat until either a proximity domain is found or the root device has been reached.
3) If no proximity domain information is found , then it is possible the device locality information is not exposed.
4) Given a proximity domain, applications can figure out which NUMA node a device belongs to by calling GetNumaProximityNode
Brian Railing
Windows Server Performance Team