

How Hotpatching on Windows Server is changing the game for Xbox
In this article you’ll learn how Microsoft has been using Hotpatch with Windows Server 2022 Azure Edition to substantially reduce downtime for SQL Server databases running on…



The thing I love most about Microsoft is our focus on customers. Prior to coming to Microsoft, I spent the majority of my career working for companies that competed against Microsoft. Microsoft would release a new product into a market and sometimes they would nail it immediately and other times they didn’t. We brushed aside its strengths, would delight in pointing out any flaws, and congratulated ourselves on how much better we were. But we’d still make plans to sell our stock options before Microsoft got V3 out the door. I underestimated just how good Microsoft was at listening to customers and how courageous they were in doing whatever it took to satisfy those needs. Hyper-V has been a great feature and customers love it but we had some catching up to do. Well, we’ve been listening to customers and making some changes. Windows Server “8” is our V3 for Hyper-V and I think you are going to like it.
The Hyper-V V3 list of features is large and comprehensive so we’ll be discussing them through lots of team blog posts. Today we’ll start a two part blog focused on just one aspect of Hyper-V which is its support for scale up virtual machines. The raw numbers are impressive (32 logical processors; 1TB RAM; 64TB virtual disks) but as Jeff Woolsey shows in this post, increasing performance requires more than just increasing those numbers. Jeff describes our virtual NUMA (Non-Uniform Memory Access) support in Hyper-V V3. NUMA used to be an exotic technology for super high end servers but it is now used in almost all servers so it is important to support this well. Things that seem exotic and high end today are common and critical tomorrow. A number of workloads like SQL Server take advantage of NUMA to increase scalability and performance.
You might look at our V3 scale up numbers and NUMA support and think that they are well beyond anything you need – today. What that really means is that V3 gives you the freedom to stop worrying about which workloads you can virtualize and which ones you can’t. Hyper-V V3 provides the confidence that you can virtualize them all and that they will just work even when they have new resource requirements in the future. I encourage you to download the beta and see for yourself.
Jeff Woolsey, a Principal Program Manager on the Windows Server team, wrote this blog.
Virtualization Nation,
First, a huge thank you from everyone in Windows Server.
Since the release of Windows Server “8” Beta a few weeks ago, the feedback has been pouring in from all over the world and is overwhelmingly positive across all technologies in Windows Server. We’re both thrilled and humbled by your reaction.
Thank You.
Let’s Talk Scale Up
In the development of Windows Server “8,” one overarching goal was to create the Best Platform for Cloud. Whether that deployment is a in a small, medium, enterprise or massive hosted cloud infrastructure, we want to help you cloud optimize your business. One aspect to building the best platform for the cloud is the ability to host a greater percentage of workloads on Windows Server Hyper-V. Today, with Hyper-V in Windows Server 2008 R2, we can easily support virtualizing the majority of your workloads, but at the same time, we also recognize you want to virtualize your larger, scale-up workloads that may require dozens of cores, hundreds of gigabytes of memory, are likely SAN attached and with high network I/O requirements.
These are the workloads we targeted with Hyper-V in Windows Server “8”.
Scale Isn’t Just More Virtual Processors
One common Hyper-V question I hear is, “When will Hyper-V support more than 4 virtual processors? I need this for my scale up workloads.” While this is an understandable question, it’s also a surface level question that doesn’t look at the problem in its entirety. Let’s step back from virtualization and discuss a scenario with a physical server.
Suppose you deploy a brand new physical server with 8 sockets, 10 cores per socket with symmetric multithreading (SMT) for a total of 160 logical processors (8 x 10 x 2), but the server is only populated with 1 gigabyte of memory. With only 1 GB of memory, the number of logical processors is irrelevant because there isn’t enough memory to keep the compute resources busy. So, you add 512 GB of memory to help address the memory bottleneck.
However, there are still only two onboard 1Gb/E network interface cards (NICs) so you’re still going to be network I/O limited. Now, you add four 10Gb/E NICs which helps address the network I/O bottleneck. However, you still only have the system populated with a couple of hard disks so there’s your next bottleneck…
See my point?
The key to good performance and scale is balance. You have to look at the entire system holistically. You have to look at compute, memory, network and storage I/O, and address them all. Adding virtual processors doesn’t necessarily equate to good overall performance or scale.
As we investigated creating large virtual machines, we looked at the overall requirements to providing excellent, scale-up virtual machines. Today, we’re going to focus on the important relationship between CPU and memory. This means we need to discuss non-uniform memory access (NUMA). Before we discuss Hyper-V and scale-up virtual machines, let’s start with NUMA on a physical server.
Non-Uniform Memory Access (NUMA)
What is NUMA? NUMA was designed to address the scalability limits of a traditional symmetric multiprocessing (SMP) architecture. With traditional SMP, all memory accesses are posted to the same shared memory bus and each processor has equal access to memory and I/O. (BTW, about 10 years ago NUMA systems weren’t common, but with the rise of multi-core, multi-processor systems, NUMA is the norm!) Traditional SMP works fine for a relatively small number of CPUs, but quickly becomes an issue when you have more than a few compute resources competing for access to the shared memory bus . It only gets worse when you have dozens or even hundreds of threads…
NUMA was designed to alleviate these bottlenecks by grouping compute resources and memory into nodes. Each node is then connected through a cache-coherent bus. Memory located in the same NUMA node as the CPU currently running the process is referred to as local memory, while any memory that does not belong to the node on which the process is currently running is considered remote. Finally, this is called non-uniform because memory access is faster when a processor accesses its own local memory instead of remote memory. Here’s a simple example of a four NUMA node system.
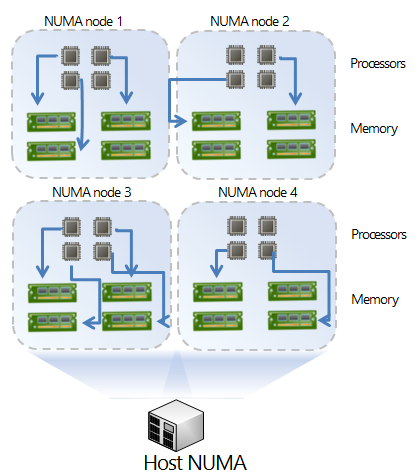
Figure 1: Optimal NUMA Configuration
Figure 1 shows an optimal NUMA configuration. Here’s why:
1. The system is balanced. The same amount of memory is populated in each NUMA node.
2. CPU and memory allocations are occurring within the same NUMA node.
Now let’s contrast this with a non-optimal NUMA configuration.
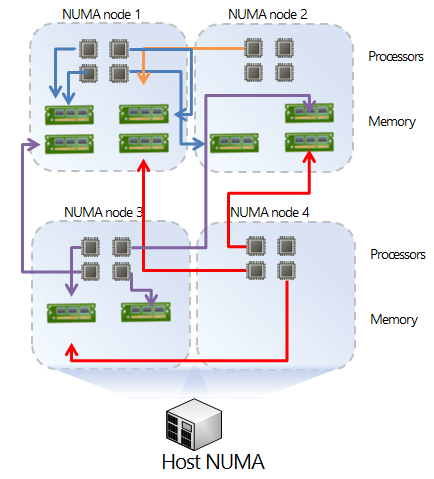
Figure 2: Non-Optimal NUMA Configuration
Figure 2 shows a non-optimal NUMA configuration, and here’s why it’s non-optimal:
1. The system is imbalanced. Each NUMA node has a different number of DIMMs.
2. NUMA Node 2 has an odd number of DIMMs which means that if the system has the ability to use memory interleaving it may be unable to do so because the DIMMs are not installed in pairs. (This also depends on motherboard interleaving requirements: pairs, trios, etc.)
3. NUMA Nodes 2 and 3 don’t have enough local memory, meaning some memory accesses are local to the node while some memory accesses are remote. This leads to inconsistent, non-linear performance.
4. NUMA Node 4 has no local memory, so all memory accesses are remote. This is the worst possible scenario.
How SQL Server Uses NUMA
As you can see in the examples above, as more compute and memory resources are added, it’s a two-edged sword. On the one hand, there are more resources available for the workload to employ, but the operating system and application must manage additional complexity to achieve consistent scale and improved performance. Because of these unique requirements, scale-up workloads are developed to be “NUMA aware.” One great example is Microsoft SQL Server. Starting with SQL Server 2005, SQL Server is NUMA aware and uses NUMA to its advantage. This MSDN article provides insight:
SQL Server groups schedulers to map to the grouping of CPUs, based on the hardware NUMA boundary exposed by Windows. For example, a 16-way box may have 4 NUMA nodes, each node having 4 CPUs. This allows for a greater memory locality for that group of schedulers when tasks are processed on the node. With SQL Server you can further subdivide CPUs associated with a hardware NUMA node into multiple CPU nodes. This is known as soft-NUMA. Typically, you would subdivide CPUs to partition the work across CPU nodes. For more information about soft-NUMA, see Understanding Non-uniform Memory Access.
When a thread running on a specific hardware NUMA node allocates memory, the memory manager of SQL Server tries to allocate memory from the memory associated with the NUMA node for locality of reference. Similarly, buffer pool pages are distributed across hardware NUMA nodes. It is more efficient for a thread to access memory from a buffer page that is allocated on the local memory than to access it from foreign memory. For more information, see Growing and Shrinking the Buffer Pool Under NUMA.
Each NUMA node (hardware NUMA or soft-NUMA) has an associated I/O completion port that is used to handle network I/O. This helps distribute the network I/O handling across multiple ports. When a client connection is made to SQL Server, it is bound to one of the nodes. All batch requests from this client will be processed on that node. Each time the instance of SQL Server is started in a NUMA environment, the SQL error log contains informational messages describing the NUMA configuration.
Traversing NUMA Nodes and Remote Memory
You may be wondering, “How much is performance impacted by traversing NUMA nodes?” There’s no one answer because it depends on a variety of factors. Here are a few:
1. Is the system balanced? No type of software magic can save you if the system is configured poorly and imbalanced in the first place. (I put this at the top of the list for a reason…)
2. Is the workload NUMA aware? For example, SQL Server is NUMA aware, which means it looks at the underlying NUMA topology and tries to perform CPU and memory allocations with best physical locality.
3. Is the physical server a newer server with an integrated memory controller in the processor, or is this an older physical server with a front side bus (FSB)? If it’s the latter, there’s a much greater performance penalty if you have to traverse the front side bus for NUMA hops…
The important thing to remember is that to build an optimal scale-up system, you want to ensure that CPU and memory allocations are made with optimal physical locality. The best way to do this is by building a balanced system. There’s a quick primer on NUMA on a physical machine. Now let’s add Hyper-V to the mix. First, let’s briefly discuss Hyper-V before this release.
NUMA, Windows Server 2008 R2 SP1 Hyper-V & Earlier
In releases prior to Windows Server “8,” Hyper-V is NUMA aware from the host perspective. What this means is that the hypervisor allocates memory and CPU resources with best physical locality. By default, Hyper-V resource placement is based on the model that generally our customers’ workloads are bounded more by memory performance than by raw compute power. Placing a virtual machine entirely on one NUMA node allows that virtual machine’s memory to be 100% local (assuming it can be allocated as such), which achieves the best overall memory performance.
Here’s one simple example. In this example, let’s assume we have an active 4 virtual processor virtual machine with an average CPU utilization above 75%. With Windows Server 2008 R2 or Windows Server 2008 R2 with SP1, if we created a virtual machine with 4 virtual processors, Hyper-V would do this:
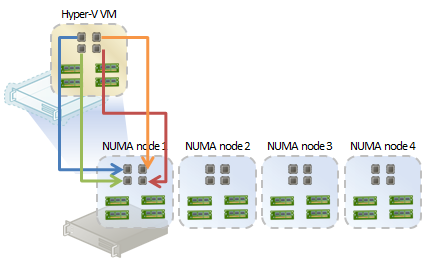
Figure 1: 4 Virtual Processor Virtual Machine on Windows Server 2008/2008 R2
As you can see in figure 1, Hyper-V creates a virtual machine and allocates resources optimally within a NUMA node. All CPU and memory allocations are local. Compare that with this:
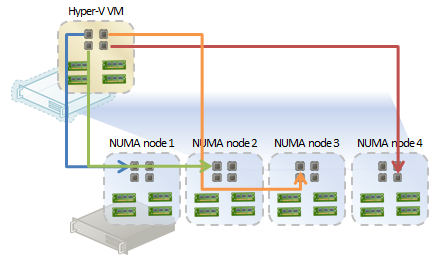
Figure 2: A Non-Optimal Scheduling Example (Hyper-V Doesn’t Do This…)
As you can see in Figure 2, there’s a lot of NUMA node traversal.
From a virtual machine perspective, Hyper-V doesn’t present a NUMA topology within the virtual machine. The topology within the virtual machine appears as a single NUMA node with all local memory, regardless of the physical topology. In reality, the lack of a NUMA topology hasn’t been an issue with Hyper-V in Windows Server 2008 R2 SP1 and earlier because the maximum number of virtual processors you can create within a virtual machine is 4 virtual processors and the maximum amount of memory you can assign a virtual machine is 64 GB. Both of these fit into existing physical NUMA nodes, so providing NUMA to a virtual machine hasn’t really been an issue to date.
Scalability Tenet
Before we dive into what’s changing with this version of Hyper-V, let me first state an overarching scalability tenet:
>> Increasing the number of cores should result in increased performance. <<
I’m sure this sounds obvious and it’s certainly what you expect when you buy a system with more cores; however, there comes a point where increasing the number of cores may plateau or result in performance degradation because the cost of memory synchronization outweighs the benefits of additional cores. Here are two examples (sample data only) to illustrate my point.
Suppose you deployed a workload on a 32-way system ($$$$) only to find out that:
• In example A: workload performance plateaus at 8 processors? Or worse,
• In example B: workload performance peaks at 8 processors and degrades beyond that?
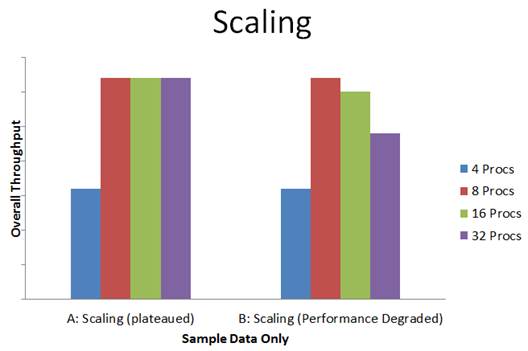
How would you feel about your return on investment on this large scale-up system?
Me too.
What you expect is as close to linear scaling as possible, which looks like this:
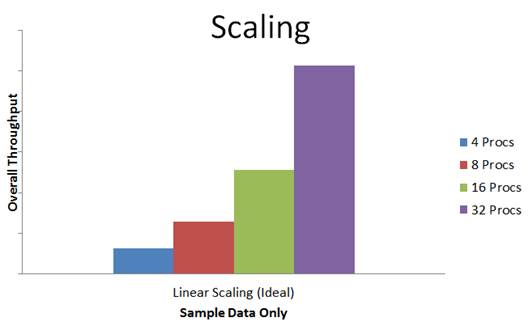
As we looked at scaling up virtual machines for this version of Hyper-V and creating virtual machines with 12, 16, 24, and up to 32 virtual processors per virtual machine, we knew this had to change. As the number of virtual processors per virtual machines exceeded the number of physical processors in a NUMA node, host side NUMA alone wouldn’t allow us to maximize hardware utilization. Most importantly, we wanted to ensure that guest workloads would be presented with the optimal information to work most efficiently and in conjunction with Hyper-V to provide the best scalability. To do that, we needed to enable NUMA within the virtual machine.
Windows 8 Hyper-V: Virtual Machine NUMA
With this version of Hyper-V, we’re introducing NUMA for virtual machines. Virtual processors and guest memory are grouped into virtual NUMA nodes and the virtual machine presents a topology to the guest operating system based on the underlying physical topology of compute and memory resources. Hyper-V uses the ACPI Static Resource Affinity Table (SRAT) as the mechanism to present topology information for all the processors and memory describing the physical locations of the processors and memory in the system. (Side Note: Using the ACPI SRAT for presenting NUMA topology is an industry standard, which means Linux and other operating systems that are NUMA aware can take advantage of Hyper-V virtual NUMA.)
With virtual NUMA, the guest workloads can use their knowledge of NUMA and self-optimize based on this data. It means Hyper-V works in concert with the guest operating system to create the best, most optimal mapping between virtual and physical resources, which in turn means that applications can ensure the most efficient execution, best performance and most linear scale. In addition, Hyper-V also includes fine grained configuration controls for virtual NUMA topologies which must be migrated across systems with dissimilar physical NUMA topologies. To provide portability across various disparate NUMA topologies, one needs to ensure that the virtual topology can be mapped among the physical topologies of all machines to which the virtual machine might be migrated.
At a high level, with two virtual machines under moderate to high load (75%+), it looks like this:
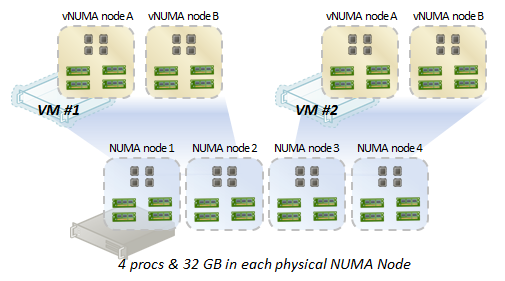
As you can see:
• Virtual machine 1 NUMA nodes A & B correspond with physical NUMA nodes 1 and 2
• Virtual machine 2 NUMA nodes A & B correspond with physical NUMA nodes 3 and 4
Let’s take a deeper look.
Virtual NUMA Example
In this example, the physical system is configured as: 1 socket with 8 cores and 16 GB of memory. When I create a new virtual machine, Hyper-V looks at the underlying topology and creates a virtual machine configured with NUMA as follows:
• Maximum number of processors per NUMA node = 8
• Maximum amount of memory per NUMA node= 13730 (this number is calculated using the total and subtracting a reserve for the root)
• Maximum number of NUMA nodes allowed on a socket = 1
Here’s what the configuration looks like:
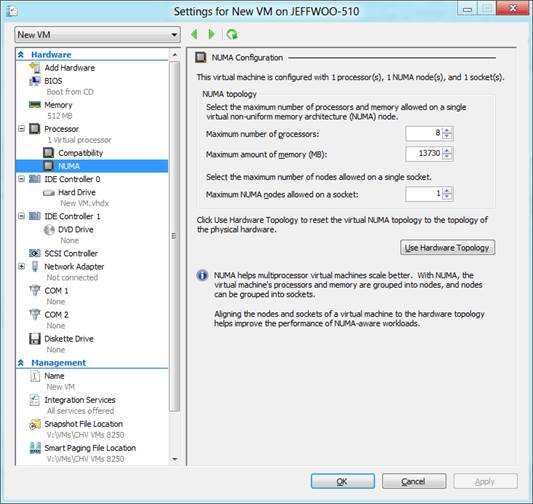
This is the optimal virtual NUMA topology for this physical system. At this point, you may be thinking, does this mean that we’ve added a whole bunch of complexity? Do I need to start counting cores, DIMM sockets, in all my servers?
No. Here’s a very important point:
>> By default, Hyper-V automatically does the right thing. <<
When a virtual machine is created, Hyper-V looks at the underlying physical topology and automatically configures the virtual NUMA topology based on a variety of factors including:
• The number of logical processors per physical socket (a logical processor equals a core or thread)
• The amount of memory per node
In addition, we’ve also provided advanced configuration options in those infrequent cases where it’s needed. We’ve included these advanced settings in case you’re moving virtual machines between hardware with disparate NUMA topologies. While this isn’t likely to happen often, we wanted to provide our customers the advanced capabilities to give them the flexibility they require. In the next blog post, we’ll discuss changes made between the Windows Server 8 Developer Preview and the Windows Server “8” Beta based on your feedback.
In this article you’ll learn how Microsoft has been using Hotpatch with Windows Server 2022 Azure Edition to substantially reduce downtime for SQL Server databases running on…

This year, Microsoft Ignite 2023 took place in Seattle, Washington from November 12 to 15, 2023 and it was such a wonderful experience to meet and interact…

October 10th, 2023 marks the end of support date for Windows Server 2012/R2 and we want to outline options for customers to stay protected and compliant.