How to fully use GPU resources to run GPGPU jobs in Microsoft HPC Pack?
With the advent of the Graphical Processing Unit (GPU) as a general-purpose computing unit, more and more customers are moving towards GPU-based clusters to run their scientific and engineering applications. Compared to a traditional CPU, a GPU has a massively parallel architecture consisting of thousands of smaller, more efficient cores designed for handling multiple tasks simultaneously.
Before the HPC Pack 2012 R2 Update 3 released, it’s quite difficult to use HPC Pack to fully utilize the GPU resources in HPC Pack. It’s also hard to manage the nodes with GPU and monitor their GPU performance count easily. I would like to show some details of Update 3 that resolve these issues.
Deployment
First things first, we need to deploy the compute nodes with GPU resources in HPC Pack cluster. Are there any extra steps we need to do? What if I install a new GPU card to an existing HPC compute node, are there any other steps we need to follow?
HPC Pack provides a quite straightforward and easy way to deploy GPU nodes WITHOUT any extra steps. As long as your compute nodes installs a supported GPU card, we will recognize and handle it automatically. The only one requirement here is the GPU card should be in our supported module list. In update 3, we only support NVIDIA CUDA GPUs.
Management and Monitoring
Before the Update 3 of HPC Pack 2012 R2, HPC admins have to manually identify and mark which nodes are GPU capable. It’s also hard for them to easily monitor some key GPU performance counters, like GPU time, to show which GPUs are in use and how they are used. Here are some key features we introduced to resolve these management and monitor problems.
In Update 3, as long as HPC Pack recognizes the GPU node, it will automatically create new node group “GpuNodes”. All the recognized GPU capable nodes will be listed there.
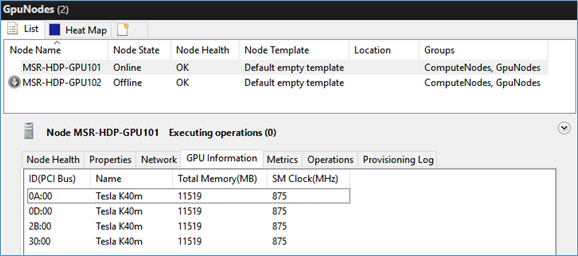
It’s also straight forward to find out more GPU specific details in the node properties under the “GPU Information” tab.
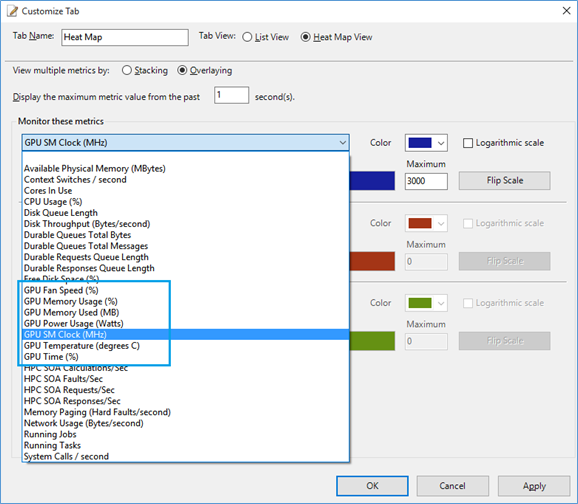
Head maps provide an easy way to find out how the nodes and system run. We are going to leverage this to show the GPUs’ performance counters as well. You can customize your own view of the heat maps to monitor GPU usage:
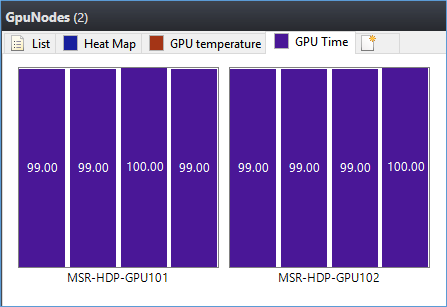
And if there are multiple GPUs in one compute node, multiple metrics value will be shown as well. For example, the following screenshot shows that 8 GPUs in 2 nodes are fully used when a GPU job runs.
GPU Job Scheduling
For GPU jobs, it’s natural to schedule based on GPU resources. Before Update 3 of HPC Pack 2012 R2, we cannot see any GPUs in compute nodes and it’s also hard to monitor the overall GPU resources and dispatch to each node for execution. This has been improved dramatically in Update 3.
When you create a new job, you will find out that there is a new schedule unit of “GPU”. This is the choice for HPC jobs that want to be scheduled based on GPU resources.
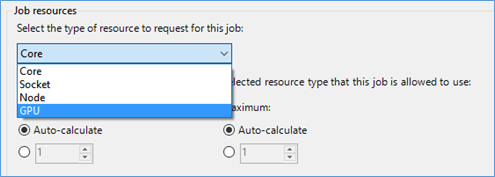
Once you choose the GPU for the job scheduling, you need to make sure the job resources you choose have GPUs deployed. If HPC job scheduler failed to find any GPU available in the job resources selection results, the job will fail with corresponding error messages.
We also support scheduling GPU jobs via HPC PowerShell and APIs. There are also more information and suggestions about how to schedule GPU jobs easily and CUDA coding sample. Please find more detailed info at the end of this blog.
Roadmaps
Microsoft Azure announced the plan to support N-Series VMs in the near future. HPC Pack is also planning to support the new type of VMs with GPU once they’re available.
This is the first step that HPC Pack is taking to introduce GPU support introduced the GPU supports. We are looking forward to hearing your feedbacks when you use it and see how we can improve it in future. You can reach out to us via email hpcpack@microsoft.com
For more detailed information about the GPU supports in HPC Pack 2012 R2 Update 3, please visit the TechNet article here.