Scale testing the world’s largest PKI… all running on WS08R2 and Hyper-V
This week, we've been in the Enterprise Engineering Center (EEC) doing our scale testing on a project to help build the world's largest PKI. When fully implemented over the next couple of years, this PKI will be the world's largest, issuing 100s of millions of certificates from 100s of CAs to devices around the world. The entire design is built on WS08R2 Hyper-V and WS08/WS08R2 CAs. Management is done using SCVMM.
In the EEC, we were able to simulate a portion of the hosting environment and drive load against it to find bottlenecks and optimize around them. To simulate one of the Hyper-V hosts, we used a similar machine to the ones being used the hosting facilities: a 2.4GHz, 4 socket, quad core machine with 64GB. We took a sysprep'd copy of the actual CA VM image used in the customer environment and loaded our host with 10 VMs, each assigned a single VCPU and 6GB. All 10 of these VMs were connected to an nCipher netHSM 2000. To generate load, each CA VM was paired with a single DC and 5 client machines, each assigned a single VCPU and 2GB and separated from the CA by a WAN simulator that added latency and throughput constraints based on the customer's actual network topology. We used an internal PKI test tool to have each client machine open 4 request sessions and requests 1000000 2K key certs per session.
After <24 hours, we'd issued >20 million certificates from this single physical chassis. During these tests, we found that:
Per VM CPU load was ~25%, total host CPU load was ~20%
Relatively little memory was required by the CA VMs, even at this high stress; thus we're optimizing the design to increase the density of CA VMs per chassis, to 30:1 (2GB per VM)
The performance bottleneck in this design is the HSM; as we increased the number of CA VMs being stressed, our requests per second per CA fell significantly, from >100 to ~18-20, giving a net issuance rate for the entire chassis of ~200 per second
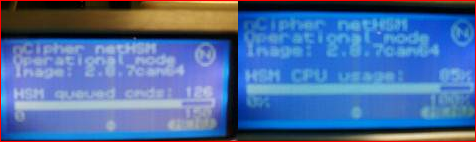
When investigating the HSM, it became clear that it was the gating component (note that its 150 request queue on the left is persistently nearly saturated and CPU on the right is pegged at consistently at 85%)
Overall, this testing was a great validation of the performance of ADCS. Our software ran as fast as the HSM would allow and we gracefully handled response delays introduced by it. Also, the fact that we're able to run this configuration entirely on Hyper-V and get ~30 CAs per physical host provides an efficient scale story for even the very largest and most complex environments around.