Изменения при работе с дисками в кластере Windows 2008
Способ взаимодействия отказоустойчивых кластеров с хранилищами данных ныне радикально отличается от прежнего. Драйвер диска кластера (clusdisk.sys) был полностью переписан и теперь является настоящим драйвером Plug and Play (PnP), а способ его взаимодействия с хранилищем изменен.
Изменены протоколы взаимодействия с дисковыми устройствами, а также включена полная поддержка GPT-разделов.
Вот об этих изменениях и пойдет речь в этом блоге. За пределами изложения находится материал о работе дисковой системы в геораспределенных кластерах, поскольку этот материал зависитот аппаратной реализации и требует отдельного изложения, а также работа с Cluster Shared Volume (CSV).
Изменение конфигурации дискового стека
В Windows Server 2003 драйвер диска кластера (clusdisk.sys) находился между кластерными узлами и хранилищем, но в Windows Server 2008 драйвер диска кластера сообщается с драйвером менеджера раздела (partmgr.sys), являющийся частью ядра системы, что обеспечивает защиту (fencing) дисков от момента старта ОС. Изменения в дисковом стеке, показаны на слайде.
Основной обязанностью менеджера раздела является защита дисковых ресурсов кластера. Все диски на общей шине хранилища автоматически помещаются в Offline состояние при первой установке соответствия с узлом кластера. Это позволяет одновременно установить соответствие хранилища со всеми узлами в кластере, даже до создания самого кластера. Больше не нужно загружать узлы по одному, готовить диски на одном, отключать этот узел, загружать другой, проверять настройку диска и т.д.
Однако всё ещё существуют тесты хранилища, выполняемые как часть процесса проверки кластера и требующие инициализации дисков. Они могут быть проделаны на одном из узлов в кластере перед выполнением процесса проверки. После того, как хранилище добавлено к кластеру, в интерфейсе управления дисками диски будут показаны как зарезервированные и не останутся в незащищенном состоянии.
Принадлежность диска к кластеру определяется на основе цифровой подписи или GUID диска (в зависимости от типа диска MBR или GPT), если цифровая подпись или GUID диска перечислен в базе данных драйвера clusdisk.sys, то диск принадлежит кластеру.
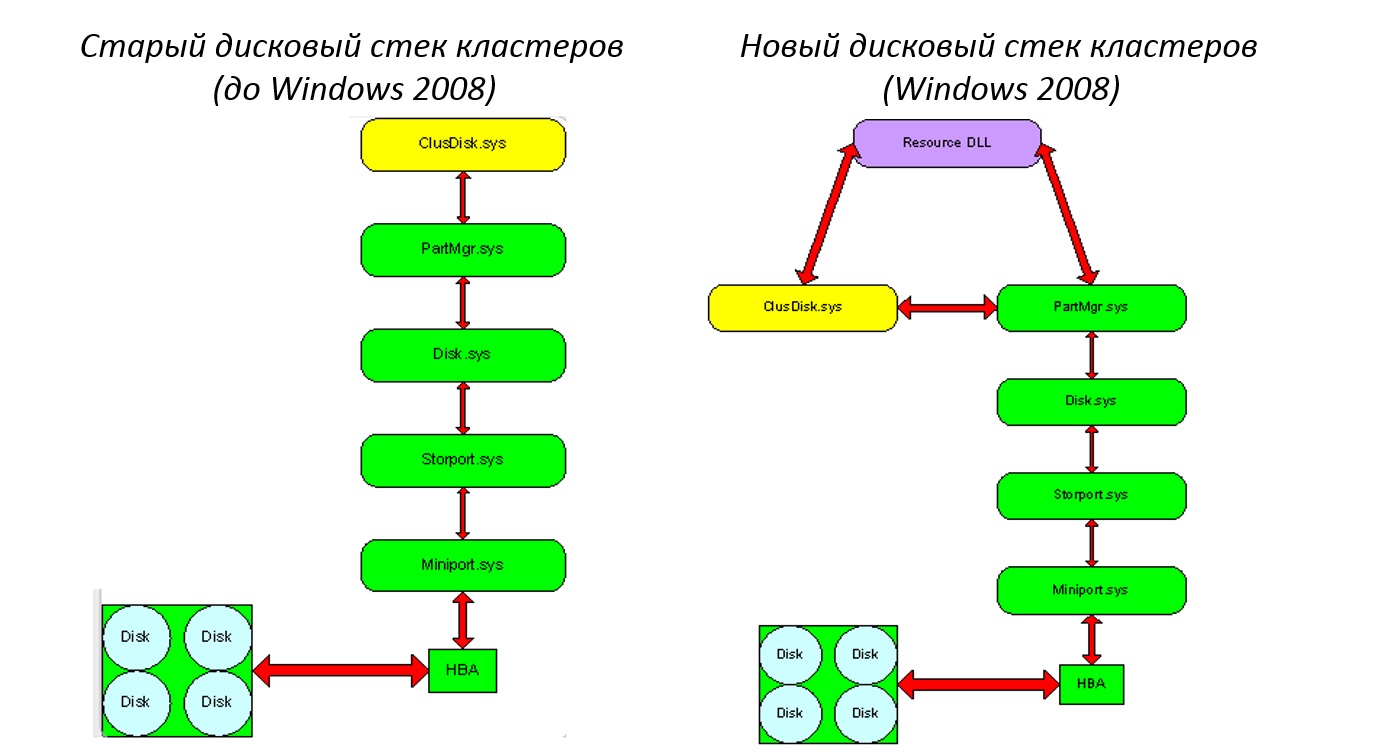
Описанные выше изменения в стеке позволили включить защиту диска на уровне ядра системы.
Как было сказано выше информация о дисках, с которыми работает кластер, помещается в раздел реестра драйвера CLUSDISK. Драйвер partmgr.sys стартуя переводит все диски в положение Offline. Далее ему надо понять кому принадлежит диск. Если он принадлежит локальному узлу, то он монтируется сразу же после загрузки дискового стека узла (сервера). Если диск перечислен в базе clusdisk.sys (один из ключей ветви реестра), то для таких дисков отрабатывается специальная процедура (алгоритм) Persistent Reservation (PR) и только после этого диск помещается в режим Online.
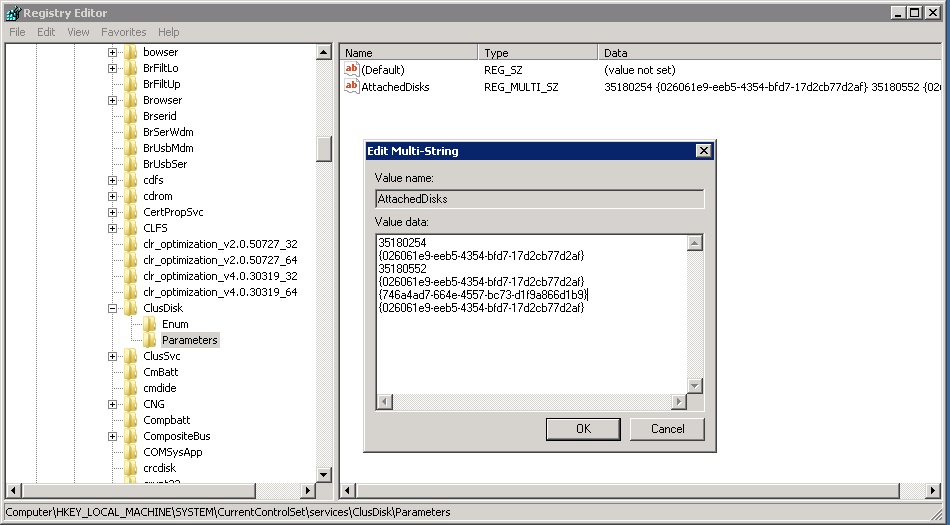
В данном случае к кластеру подсоединены три диска, один GPT ({746a4ad7-664e-4557-bc73-d1f9a866d1b9}) и два MBR (35180254, 35180552). Значение {026061e9-eeb5-4354-bfd7-17d2cb77d2af} одинаково для всех кластеризованных дисков.
С помощью утилиты DISKPART.EXE можно просмотреть цифровые подписи или GUID-ы дисков. Цифровые подписи или GUID-ы должны соответствовать цифровым подписям или GUID-ам перечисленным в реестре CLUSDISK иначе диск считается локально присоединенным и на нем не работает протокол Persistent Reservation (PR).
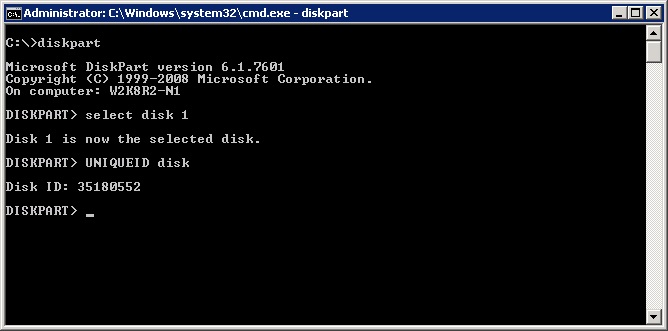
В разделе реестра CLUSDISK перечислены только кластеризованые диски (диски на которых работает алгоритм PR). Протокол PR запускается на диске как только вы поместили его в группу "Available Storage", до этого момента времени диск считается локально присоединенным и информация о нет не присутствует в ветви реестра CLUSDISK.
Использование SCSI-3.
Другое изменение, сделанное в кластере Windows 2008, имеет отношение к командам SCSI.
В Windows Server 2003 команды SCSI-2 «Зарезервировать\Освободить» использовались для драйвера диска кластера и записывались на секторы самого диска (12 и 13 секторы), что иногда приводило к неуправляемой цепочке последствий при работе с дисками, поскольку запись информации арбитрирования дисков на сектора того же диска могла быть задержана при очень высокой нагрузке на диск. Что, в конечном счете, нарушало работу системы арбитрирования дисков.
В Windows Server 2008 используется протокол SCSI-3 и требуются команды постоянного резервирования (Persistent Reservation) ныне записываемые в структуры LUN. Для начала работы узлы кластера должны зарегистрироваться в таблице постоянного резервирования (размещенной на уровне LUN ), прежде чем им будет позволено резервировать свое хранилище. Они (узлы) также периодически защищают свои резервирования, используя протокол защиты регистрации.
Таблица Persistent Reservation имеет структуру схожую со структурой показанной ниже. Почему схожую? А потому, что ныне (начиная с Windows 2008) за хранение и сопровождение этой таблицы отвечают производители SAN, и ОС получает информацию из этой таблицы выполняя запрос к ней на уровне кода ядра и не видя самой таблицы.
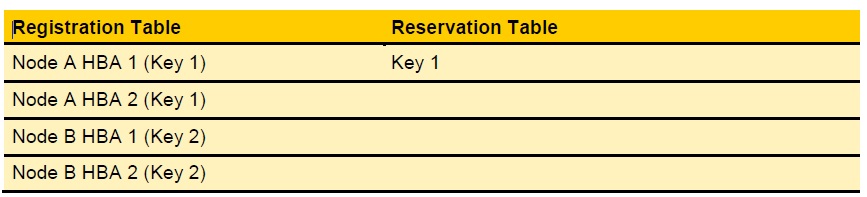
В таблице есть два раздела (столбца), а количество строк в таблице равно произведению количества узлов кластера на количество кластеризованных дисков и на количество путей к каждому диску. Каждый узел кластера помещает информацию регистрации в таблицу, но "победить" в этой операции может только один узел (на начальном этапе это узел, поместивший первым информацию регистрации). Через определенные интервалы времени узел, который первым поместил информацию регистрации помещает информацию о себе в столбце резервации, а остальные записи в таблице вытирает. То есть после победы Node A таблица будет иметь следующий вид.

Если по какой-либо причине Node A не сможет вовремя обновить резервацию, то Node B вытрет ее из таблицы и захватит ресурс.
Время через которое производятся такие попытки называется DiskArbInterval (интервал арбитрирования диска) и может быть изменено через CLUSTER.EXE либо PowerShell.
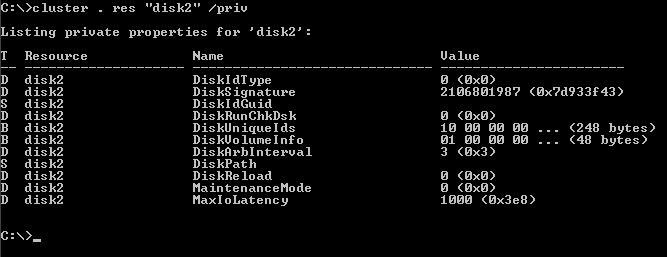
По умолчанию этот параметр равен 3 секундам и менять его надо только в том случае если в этом есть действительно насущная потребность или это рекомендация производителя оборудования.
В некоторых (очень редких) ситуациях происходит сбой в работе системы PR и требуется обнуление таблицы резервирования для одного или нескольких узлов. В этом случае можно воспользоваться либо утилитой CLUSTER.EXE (команда CLEARPR) для узла, либо PowerShell (Clear-ClusterDiskReservation). Если вы произвели обнуление таблицы для всех узлов, то это может привести к перемещению ресурсной группы, содержащей диск, на другой узел кластера.
Один из тестов из процесса валидации кластера проверяет эту функцию. Если хранилище не поддерживает команды постоянного резервирования SCSI-3, оно не поддерживается отказоустойчивыми кластерами Windows 2008 (R2). При проведении валидации такого кластера вы получите сообщение об ошибке протокола PR и сообщение с ошибкой номер 170 в кластерном логе. Ошибки протокола PR это (в превалирующем количестве ситуаций) проблемы дискового устройства или установленного драйвера производителя дисковой стойки.
Изменения Microsoft Multi-Path Input\Output
Многие организации используют (для избыточности и отказоустойчивости) программы с несколькими путями к данным на хранилище. Такое решение поддерживается и даже поощряется как лучший вариант.
Однако, подход, который был реализован в Windows 2000…2003 требовал, что бы MPIO-модуль был реализован корпорацией Microsoft и обновлялся ей же. Что, в свою очередь приводило к трудно-разрешимым ошибками при установке нового firmware на SAN-системы.
Именно поэтому было принято и согласовано решение, что программные модули с несколькими путями (MPIO) от сторонних производителей или модули конкретных устройств должны быть написаны и поддерживаться производителями систем хранения с использованием стандарта Microsoft Multi-Path Input\Output (MS MPIO). Это гарантирует, что все команды постоянного резервирования SCSI-3 одновременно отправляются по всем путям в хранилище независимо от того, активен ли путь или нет. Эта функциональность также проверяется в рамках процесса проверки.
Теперь корпорация Microsoft поставляет MPIO как Framework (оболочку) для встраивания в нее модулей от производителей дисковых SAN-систем. Модули, поставляемые производителями (Device Specific Module или DSM), встраиваются в MPIO Framework. Теперь, при обновлении firmware на дисковых SAN-стойках, необходимо обновление и DSM модулей. Для крайних случаев (отсутствия DSM от производителя или некорректной его работы) в составе ОС поставляется MPIO модуль от Microsoft (mpio.sys), но он не оптимизирован для всех хранилищ и поэтому не может предоставить максимальный уровень производительности и сервиса.
В подавляющем большинстве ситуаций проблемы с кластеризованными дисками связаны с несоответствием DSM и Storport\miniport драйверов версии firmware дискового хранилища. Всегда требуйте соответствующих драйверов у производителей SAN при проведении сервисных работ на системах хранения данных.
Поддержка дисков с GPT разделами.
Кластер теперь поддерживает диски с GPT разделами (GUID Partition Table - GPT) в дополнение к MBR (Master Boot Record) разделам, что позволяет использовать разделы дисков объемом более 2 Тбайт.
MBR содержит таблицу разделов, описывающую их размещение на диске. На MBR поддерживаются тома размером до 2 терабайтов (Тб), и эти разделы в свою очередь подразделяются на:
- основные (primary);
- расширенный (extended).
Каждый MBR-диск может содержать до четырех основных разделов или три основных и один дополнительный. Основные разделы — это части диска, которые непосредственно используются для хранения файлов. После создания файловой системы раздел становится доступным для пользователей. В отличие от основных дополнительные разделы напрямую недоступны. В них нужно сначала создать один или несколько логических дисков, на которых вы сможете хранить файлы.
Разметка дополнительного раздела на логические диски позволяет разделить физический диск более чем на четыре части.
В Windows 2008 также могут использоваться GPT-разделы.
Диски с GPT-разделами содержат два обязательных раздела (required partitions) и минимум один дополнительный (OEM или данные). Кроме того, GPT-диски поддерживают тома размером до 18 эксабайт (ЭБ) и до 128 разделов.
Несмотря на различия между GPT и MBR-разделами, большинство операций, связанных с дисками, выполняется одинаково.
Подключение дисков.
Подключение дисков к кластеру производится ко всем узлам. По умолчанию диски, подключенные к узлам кластера, считаются "cluster eligible" только в том случае, когда они подсоединены ко всем узлам кластера. Исключение составляет ситуация когда установлен специальный пакет (https://support.microsoft.com/kb/976097) обеспечивающий работу кластера при подключении дисков к части узлов, что может быть очень полезно при развертывании геораспределенных Windows кластеров при невозможности иметь общее хранилище данных.
Диски, подключенные к кластеру, попадают в служебную группу кластера "Available Storage" и отображаются на узлах кластера как "Reserved", что указывает на то, что на них работает протокол PR. Перемещение группы "Available Storage" возможно только с использованием команд CLUSTER.EXE либо PowerShell.

На узле, который является собственником кластерной группы, имена логических дисков (томов) отображаются, а на других узлах нет.
Новые возможности по обслуживанию дисков. Maintenance Mode.
Для выполнения работ с диском (ChkDsk, Volume Snapshot и пр.) он может быть переведен в режим сопровождения ("Maintenance mode"). При нахождении в этом режиме по отношению к диску могут выполняться процедуры сопровождения без вывода его из кластерной группы и перевода в режим Offline.
При переключении диска в режим сопровождения:
- приостанавливаются "Basic/Thorough Health Check".
- приостанавливается процесс "Persistent Reservation".
- диск переводится во внутренний Offline, при этом остается видим как доступный для приложений.
Перевод в этот режим возможен через графическую оболочку, CLUSTER.EXE или PowerShell. Для того, чтобы перевести диск в этот режим работы все узлы перечисленные в кластере должны быть доступны.
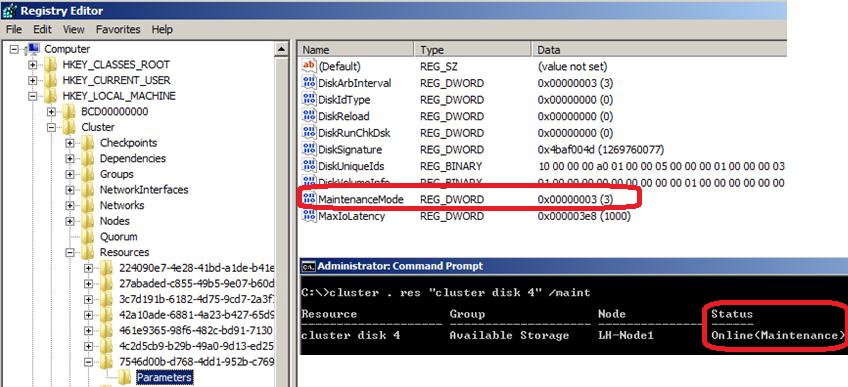
При переводе диска в этот режим необходимо помнить, что диск не защищен от внешнего доступа, поскольку на нем не работает протокол PR, и любой некластеризованный сервер, имеющий доступ к этому диску может выполнить к нему неблокирующий запрос на чтение/запись, что может нарушить целостность диска.
Обратите внимание, что после перевода диска в "Maintenance mode" он отображается как Online на узле кластера, а не как Reserved.

Новые возможности по обслуживанию дисков. ChkDsk.
Всем наверное известна старая проблема с запуском ChkDsk на кластерах под управлением всех ОС до Windows 2008 (https://blogs.technet.com/b/ganand/archive/2009/03/17/how-to-stop-chkdsk-from-running.aspx). При аварийном перекате (failover) ресурса стартовал в работу ChkDsk, диск "подвисал" в состоянии "Online Pending" и мог находиться в нем часами (в зависимости от размера диска). Для управления процессом проверок диска работа утилиты изменена и у вас появилась возможность выбора режима работы утилиты вплоть до ее полного отключения.
С одной стороны диск является стандартным ресурсом кластера, а с другой стороны он имеет свою специфику проверок, таких как Basic/Thorough Check. Ниже приведен перечень проверок проводимых по отношению к диску как кластерному ресурсу.
File System checks |
Проверки проводимые на файловом уровне |
| Basic check | Короткая проверка проводимая каждые 5 секунд, чтобы быть уверенным, что дисковый ресурс доступен. Наличие проблем определяется по флагам устанавливаемым при обнаружении проблем. Например флаг может указывать на наличие проблем с протоколом PR. |
| Thorough check | Комплексная проверка выполняемая каждые 60 секунд и включающая в себя проверку доступности диска и исправность файловой системы. Проверка схожа с той, что выполняется при выполнении команды DIR из командной строки. |
| Device level checks | Проверки выполняемые драйвером clusdisk.sys каждые 3 секунды на PR таблице, что бы убедиться, что узел все еще является собственником данного диска. |
Ниже приведены возможные режимы работы утилиты.
0 |
Default. Запуск в нормальном режиме (Normal Check). Если обнаружена проблема, то исправить ее. Запуск в "Нормальном режиме" (Normal Check) обозначает: открытие файлов в корне диска и проверка "Dirty bit". |
1 |
Запуск в полном режиме (Verbose Check). Если обнаружена проблема, то исправить ее. Запуск в "Полном режиме" (Verbose Check) обозначает: открытие всех файлов диска и проверка "Dirty bit". |
2 |
Запуск в нормальном режиме (Normal Check). Если обнаружена проблема, то исправить ее. Сканирование выполняется в Online режиме на Snapsot-е тома. При этом сохраняется доступ к диску. |
3 |
Не выполнять анализ файловой системы, выполнять только проверки тома. |
4 |
Не выполнять никаких проверок. Отключение ChkDsk. Это режим отключает IsAlive/LooksAlive проверки и отключает проверки файловой системы. |
5 |
Запуск в полном режиме (Verbose Check). Если обнаружена проблема, то остановить проверку и ожидать вмешательства администратора. |
6 |
Работа с диском в Raw режиме. Работа на уроне системы ввода/вывода без файловой системы. |
Переключение режимов работы производится либо через утилиту CLUSTER.EXE (CLUSTER res “cluster disk” /priv DiskRunChkDsk=value), либо через PowerShell (Get-Cluster | Get-ClusterResource "Cluster Disk 2" | Set-ClusterParameter DiskRunChkDsk 1).
Встроенный механизм "Самолечения" дисков.
В отличии от предыдущих версий кластера, где для восстановления работоспособности кластеризованного диска требовалось использовать отдельно поставляемую утилиту ClusterRecovery, механизм восстановления ныне встроен в алгоритм работы кластера.
Как было показано выше принадлежность диска кластеру определяется по соответствию его цифровой подписи, которая хранится на диске и подписи хранящейся в ветви реестра CLUSDISK. Если ваш диск вышел из строя, то вы должны подставить новый диск и переписать в реестр его подпись. А если произошел сбой и цифровая подпись диска нарушилась, то диск "выпадал" из кластера и требовалось ручное вмешательство администратора.
Теперь эта логика изменена и механизм восстановления встроен к кластерные утилиты.
Кроме того кластер может определить принадлежность диска к кластеру не только по цифровой подписи, но и по специальной структуре "SCSI inquiry page 0x83 data" VPD (Vital Product Data), хранящейся на уровне LUN (https://en.wikipedia.org/wiki/SCSI_Inquiry_Command). Если хотя бы один вид данных совпал, то диск считается кластеризованным и система выполняет его подключение и модификацию несоответствия в другой структуре.