Динамический кворум кластера в Windows Server 2012
Не сомневаюсь, что всем читающим данный блог, знакомо понятие "кворум" применительно к кластерной инфраструктуре. Более года назад Алекс в своей заметке срывал покровы о возможностях высокодоступных решений с ассиметричными хранилищами и конфигурации узлов в качестве неголосующих в сценариях геораспределенного кластера на платформе Windows Server 2008 R2. В Windows Server 2012 эта возможность, помимо выноса в графическую оболочку, еще и несколько автоматизирована. Об этом сегодня и пойдет речь - функционирование динамического кворума в кластерах на базе Windows Server 2012.
В отличие от Windows Server 2008 R2, требующего установки обновления 2494036, в Windows Server 2012 выбор голосующих узлов есть в графическом мастере конфигурации кворума
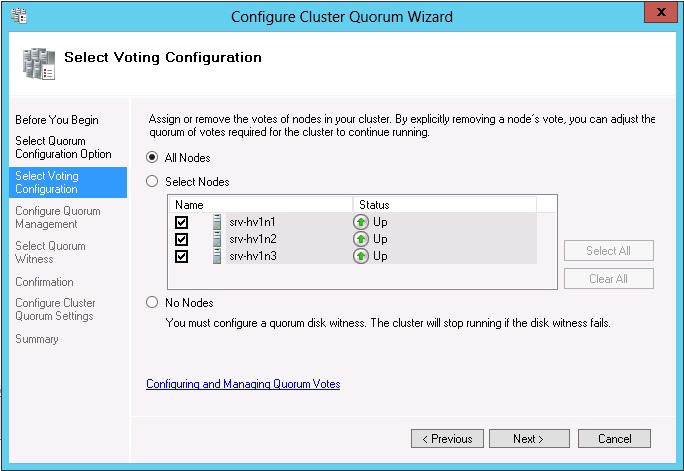
Динамический кворум кластера
Эта функция пересчитывает голосующих узлов в случае даже в случае выхода более 50% ресурсов кластера. Такие образом, концепция динамического кворума позволяет оставаться кластеру жизнеспособным при наличии хотя бы одного узла. Однако стоить отметить, что эта функция будет работать только в случае последовтельного выхода из строя узлов кластера, уже имеющего кворум, т.е. до момента аварии следующего узла служба кластера должна успеть пересчитать голосующие узлы.
Рассмотрим, как это работает на примере трехузлового кластера с моделью "Большинство узлов" и включенным динамическим кворумом
В полностью рабочем состоянии всех трех узлов с помощью командлета PowerShell Get-ClusterNode можно увидеть состояние и динамический вес серверов
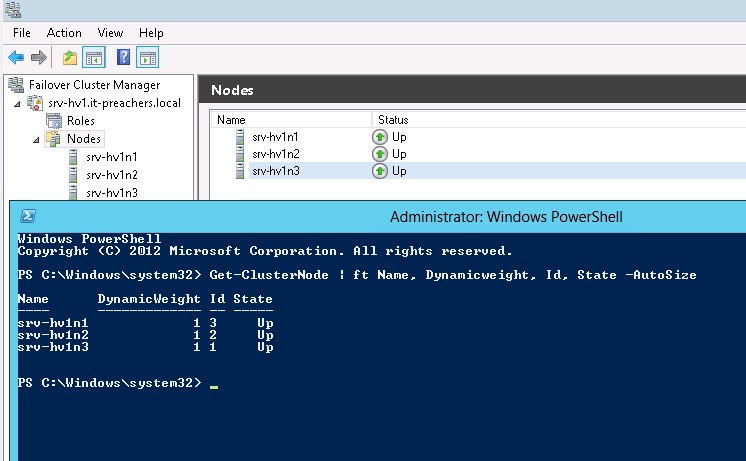
Для демонстрации рекалькуляции голосов на узле srv-hv1n3 отключена служба кластера. Используя все тот же командлет, можно заметить, что у srv-hv1n2 значение DynamicWeight изменилось с 1 на 0.
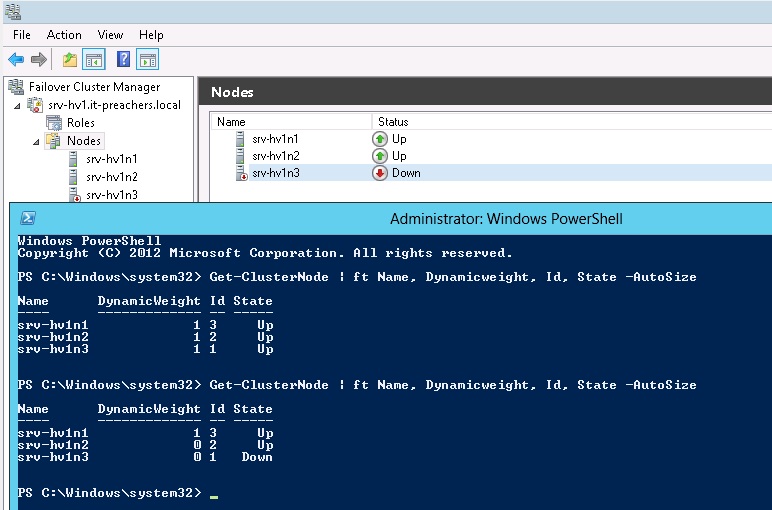
Динамическим кворумом, при понимании ситуации с выходом из строя одного из узлов, принято решение о лишении права голоса сервера с наименьшим ID. В качестве продолжения "опасного" эксперимента был выключен и второй сервер
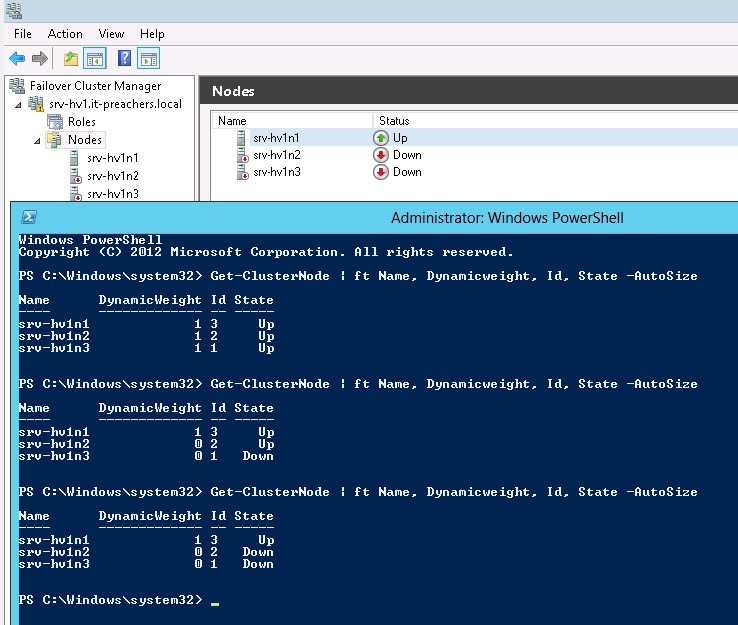
Кластер с кворумом в один голосующий узел продолжает работать. Стоить заметить еще раз, что для функционирования динамического кворума необходимо, что бы соблюдались два условия:
- Кластер должен иметь набранный кворум
- Узлы кластера выходят из строя последовательно для возможности перерасчета голосов