Cluster Shared Volumes (CSV) — установка, использование, отключение
Многое уже было сказано о виртуализации в Windows Server 2008 R2, о новой технологии Cluster Shared Volumes (CSV), позволяющей всем узлам кластера одновременно работать с общим диском, о Live Migration, отчасти ставшей возможной как раз с появлением CSV.
Технология Cluster Shared Volumes позволяет вам размещать на общем кластерном диске виртуальные машины, запускаемые на разных узлах кластера. Это очень удобно, так как позволяет вам переносить виртуальные машины с узла на узел, не смотря на то, какие еще виртуальные машины на данном диске расположены.
Сегодня я не буду рассказывать теорию работы Cluster Shared Volumes — если интерес будет проявлен, опишу её в отдельной статье. Сейчас же мы рассмотрим практическую сторону — как задействовать функционал Cluster Shared Volumes, как включить его для общих дисков, как отключить данный функционал, если потребуется и такой шаг.
Я исхожу из того, что вы уже установили Windows Server 2008 R2 или Hyper-V Server 2008 R2 на один или несколько серверов и создали кластер. Сразу после создания кластера вы не видите в консоли Failover Cluster Manager раздела Cluster Shared Volumes, так как данных функционал отключен по умолчанию.
Как задействовать Cluster Shared Volumes?
Ответ на вопрос будет таким же простым, как его формулировка, — в консоли Failover Cluster Manager выберите корневой элемент созданного кластера. В списке действий увидите команду Enable Cluster Shared Volumes.
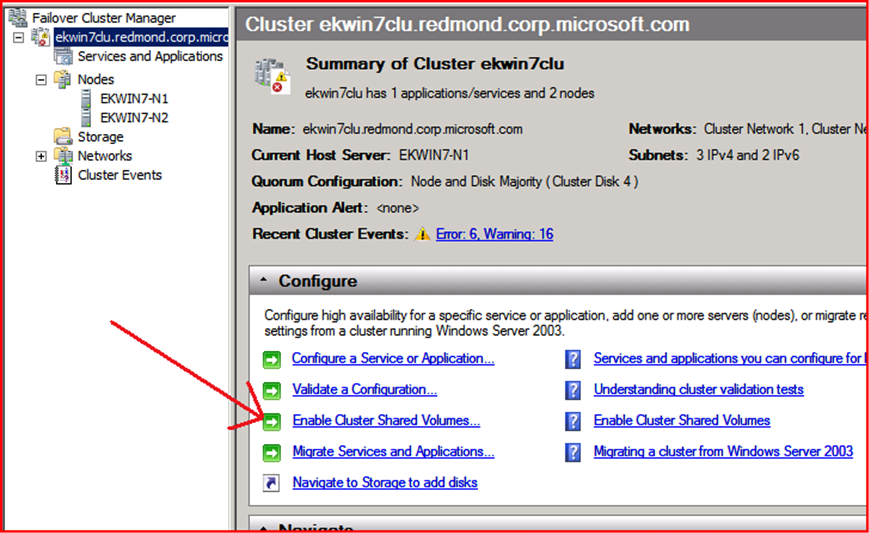
Выбрав эту команду, согласитесь с предупреждением системы о том, что CSV поддерживается лишь для отказоустойчивых виртуальных машин, — и вы заметите, что в консоли Failover Cluster Manager появился новый раздел.
Как задействовать Cluster Shared Volumes из PowerShell?
Вы можете включить поддержку CSV на вашем кластере и из PowerShell. Делается это при помощи следующей команды: Get-Cluster | %{$_.EnableSharedVolumes = "Enabled"}
Обратите внимание на то, что по умолчанию в PowerShell не загружаются все возможные модули — и поэтому при обычном запуске Windows PowerShell коммандлет Get-Cluster недоступен. Чтобы воспользоваться специализированным набором коммандлетов, вам потребуется импортировать модуль поддержки технологий кластеризации. Для этого выполните команду import-module failoverclusters или же запустите «Windows PowerShell Modules» из меню «Administrative Tools», что загрузит разом все модули, входящие в стандартный пакет администрирования.
Как отключить поддержку Cluster Shared Volumes?
Интересный момент — включение поддержки CSV возможно из консоли Failover Cluster Manager, а вот возможность отключения там отсутствует. Единственный способ отключить поддержку CSV в кластере — выполнить команду Get-Cluster | %{$_.EnableSharedVolumes = "Disabled"}
Помните о том, что следует импортировать модуль failoverclusters или запускать «Windows PowerShell Modules» из «Administrative Tools».
Включение Cluster Shared Volumes для общих дисков
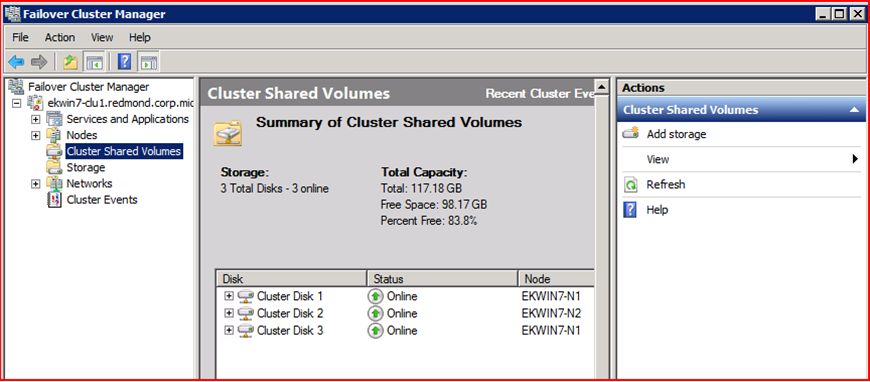
Задействовав поддержку CSV на кластере, вы еще не сделали ваши общие диски доступными на всех узлах сразу. Это потребуется выолнить для каждого из дисков отдельно. В консоли Failover Cluster Manager в графе Cluster Shared Volumes вы видите, какие диски в данный момент используют технологию CSV.
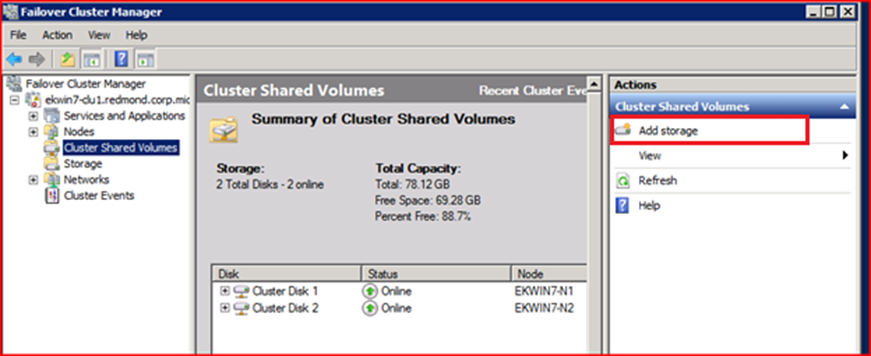
Если вы хотите включить Cluster Shared Volumes для нового диска, выполните действие «Add Storage» и выберите этот диск.
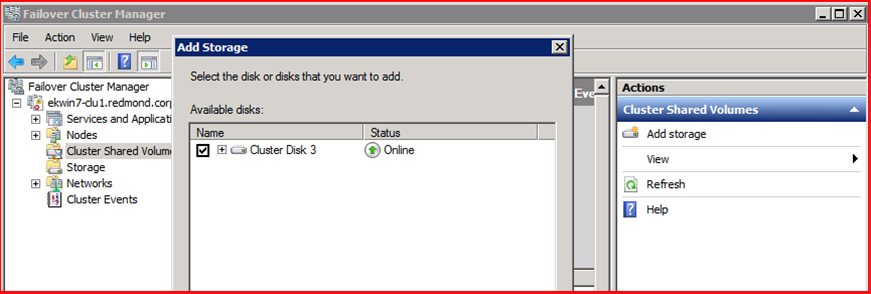
Добавленный диск также отобразится в списке дисков, использующих CSV.
Создание виртуальных машин на Cluster Shared Volumes
Каждый диск, для которого вы задействовали CSV, будет доступен на всех узлах в виде каталога «C:\ClusterStorage\VolumeX» , где X — номер диска в очерёдности включения CSV (что вовсе не обязательно может совпадать с нумерацией дисков в представлении оснасток Failover Cluster Manager и/или Disk Management).
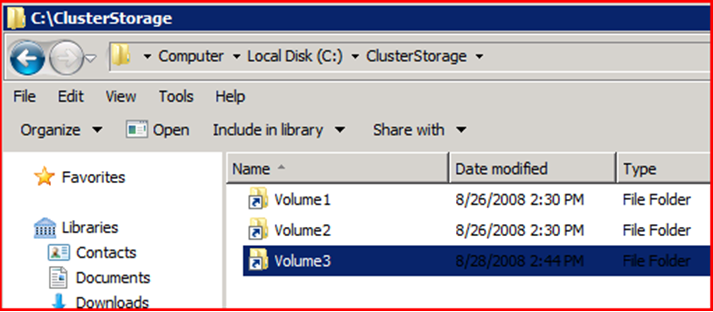
Теперь создавая виртуальные машины, размещайте их конфигурацию и диски внутри данных каталогов.
Дополнительные соображения
Помните о том, что диски CSV не поддерживают технологию Pass-Through. То есть у вас не получится подключить общий диск кластера напрямую к виртуальной машине. Вместо этого на общих дисках следует создавать виртуальные диски (VHD) и уже их подключать к виртуальным машинам. Впрочем, любая виртуальная машина может одновременно сочетать в себе виртуальные диски (расположенные на CSV) и диски, подключенные как Pass-Though (не задействованные в кластере каким-либо другим способом).
Если вы копируете файлы (например, виртуальные диски) на диск CSV — запускайте процесс копирования на узле-координаторе. Подробнее об этом я расскажу в следующей заметке.