Будущее виртуализации в Windows Server 2008 R2 и далее. Часть 5
Продолжая разговор о следующих версиях Hyper-V, хочется затронуть не только Windows Server 2008 R2, но и более отдалённое будущее. Благо, после WinHEC материла в избытке. Поэтому сегодня речь пойдёт таких радикальных изменениях, как смене стратегии ввода-вывода. Необходимо сразу пояснить, что пока ещё нет ясности на счёт того, в какой мере описанные концепции найдут воплощение именно во второй версии Hyper-V. Отстсутствие необходимых технологий на сегодняшнем рынке аппаратного обеспечения тоже не добавляет ясности. Поэтому всё сказанное ниже стоит воспринимать ни в коем случае не как обещания на ближайшее время, а скорее как разъяснение долгосрочных планов и инициатив.
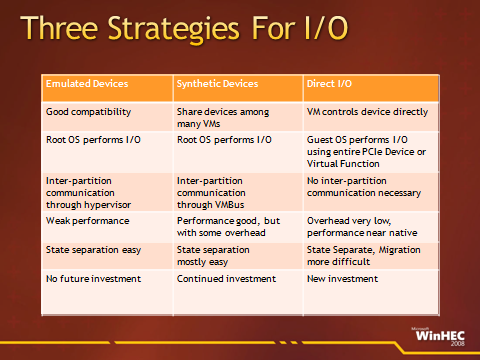
Итак, вся совокупность изменений в рассматриваемой области сводится к концепции прямого ввода-вывода (Direct I/O) . Напомню, что до сих пор существовали две основных стратегии — это эмулируемый ввод-вывод и синтетический. Первая была характерна для мониторов виртуальных машин (они же гипервизоры второго типа или размещаемые, Hosted) и сейчас поддерживается на правах унаследованной (Legacy) технологии. Реализация этой стратегии вообще не требует пересмотра принципов работы гостевой операционной системы. За счёт этого достигается максимальная совместимость с широким набором гостевых ОС, в том числе — и не поддерживаемых официально. Появление второй стратегии исторически совпало с выходом гипервизоров первого типа, они же «собственно гипервизоры» — именно таких, как Hyper-V. Её реализация предусматривает написание особых драйверов для гостевых систем, которые напрямую работают со внутренними структурами гипервизора (в Hyper-V это виртуальная шина данных VMbus). И вот, следующий виток эволюции — прямой ввод-вывод. Реализация этой стратегии предполагает ещё более глубокие изменения в гостевых ОС — не только на уровне драйверов, но и вообще всей подсистемы ввода-вывода.
Помимо этого, потребуется глубокая поддержка со стороны аппаратного обеспечения. Очевидно, что должно пройти некоторое время, пока она будет реализована полностью. Сегодняшние устройства разрабатывались с расчётом на то, что в каждый момент времени одно устройство будет работать только с одной системой, которая будет использовать один драйвер. А значит, во-первых, адресация на шине совпадает с адресацией драйвера, а во-вторых — не существует никакой границы безопасности между оборудованием и драйвером. Следовательно, любое устройство может контролировать всю систему.
Перечислю несколько перспективных технологий — как уже существующих, так и только разрабатываемых, — которые помогут обойти эти ограничения и реализовать концепцию прямого ввода-вывода. Приходится учитывать, что каждая из них должна получить поддержку множества сторон — от производителей компонентов оборудования и сборщиков систем до производителей процессоров и чипсетов, не говоря уже о поставщиках программных решений.
- Intel Extended Page Table (EPT) и AMD Nested Page Table (NPT) . Это две реализации одного и того же механизма, который встраивается в центральный процессор и выполняет те функции, которые ранее реализовывались только программно в гипервизоре. Речь идёт о буфере быстрого преобразования адресов (Translation Lookaside Buffer, TLB).
- Single-Root I/O Virtualization (SR-IOV) — дополнение к стандарту PCI Express, которое позволяет одновременное использование устройства несколькими независимыми программными структурами, выполняющимися в пределах одной системы.
- Multi-Root I/O Virtualization (MR-IOV) — следующее дополнение к стандарту PCI Express, расширяющее SR-IOV. Позволит одновременное использование устройства несколькими независимыми системами (что может быть полезно например, в серверах-лезвиях).
- I/O MMU — Input/Output Memory Management Unit. Это механизм трансляции в контроллере памяти, который позволяет устройству или группе устройств использовать при обращении к основной памяти преобразованные адреса. Для достижения прямого ввода-вывода требуется, чтобы I/O MMU выполнял перенаправление или перераспределение как прямого доступа к памяти (Direct Memory Access Remapping/Redirection, DMAr), так и прерываний (Interrupt Redirection). Это послужит усилению защиты гипервизора. Во-первых, устройства смогут обращаться напрямую к областям памяти готевых систем. А во-вторых, не-привелигированные устройства не смогут ни изменять память гипервизора, ни вызывать произвольные прерывания.
На сегодня существует только одна реализация I/O MMU — это технология Intel VT-d (Virtualization Technology for Directed I/O). Причём она выполняет только первое требование, то есть перенаправление прямого доступа к памяти (DMAr). Следующая реализация этой технологии, VT-d2, — так же, как и аналогичная технология AMD IOMMU, — будет выполнять и второе требование — то есть перенаправление прерываний.
И всё это — только вершина айсберга. Помимо реализации перечисленных технологий, для достижения прямого ввода-вывода потребуется выполнение ещё ряда весьма специфических условий на уровне оборудования. Список этих требований известен как перечень «дыр в виртуализации» (Virtualization Holes), от которых следует избавляться по мере проектирования новых компонентов. А кроме того, сама идея передачи некоторых задач от гипервизора к оборудованию влечёт за собой и ряд совершенно новых проблем. Взять хотя бы крайне популярную сегодня тему «живой миграции» — переноса виртуальной машины между физическими узлами без приостановки. Сегодня она выполняется за счёт того, что вся виртуализация выполняется программно, а оборудование не имеет никакого отношения к состоянию ВМ. Что же будет, когда значительная часть нагрузки виртуальной машины будет выполняться оборудованием напрямую? Я не буду останавливаться на подобных вопросах — хотя бы потому, что этот рассказ ведётся техником для аудитории таких же техников, а не разработчиков. Если вы непосредственно связаны с проектированием оборудования или написанием драйверов, то советую вам не ограничиваться моим сумбурным перессказом, а обратиться к первоисточнику — презентации, которая озаглавлена Directions In Virtualized I/O и была прочитана Джейком Ошинсом (Jake Oshins) на конференции WinHEC 2008.
Очевидно, что концепция прямого ввода-вывода сулит многоичисленные выгоды для виртуализации. Причём это касается как виртуализации рабочих мест, так и серверов. Только представьте себе, что рабочие места множества сотрудников в системе VDI используют одну и ту же видеокарту на сервере — со всеми функциями вроде аппаратного ускорения. Или множество виртуальных серверов используют общий дисковый контроллер — с такой же производительностью, как и физические машины. Однако когда же это станет возможно на практике?
К сожалению, простого ответа на этот вопрос сейчас ещё нет — о чём я честно предупредил в начале заметки. В краткосрочной перспективе Microsoft продолжит делать ставку на синтетический ввод-вывод, максимально доводя его производительность до возможностей прямого. В то же время, в ближайшей версии Hyper-V уже запланирована поддержка некоторых перспективных технологий по переносу нагрузки от центрального процессора к оборудованию. Правда, речь идёт пока что не о вводе-выводе в общих случаях, а лишь об оптимизации сетевой подсистемы в частности. Опять же, сейчас ещё слишком рано говорить о том, будет ли эта поддержка действительно включена в окончательной версии, но сейчас уже идёт тестирование этих функций на бета-версиях Windows Server 2008 R2 (но не pre-beta, она же M3).
Сетевая подсистема второй версии Hyper-V станет поддерживать, во-первых, частичную обработку протокола TCP на уровене сетевого адаптера — то есть технологии TCP Chimney Partial Offload и Large Segment Offload (TCP segmentation offload). А во-вторых, сверхдлинные кадры Ethernet — Jumbo frames. Все три этих технологии, как известно, сегодня поддерживаются самой ОС Windows Server 2008, но не виртуальными коммутаторами Hyper-V. Именно поэтому для достижения максимальной пропускной способности iSCSI сейчас рекомендуется использовать либо аппаратные контроллеры iSCSI, либо создавать подключения к хранилищам из родительской системы, а не гостевых ОС. Впрочем, это актуально только на скоростях не менее 10 Gb/S.