Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Virtualization
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
application virtualization
aslr
ASR
authorization table
Automation
availability
Azure
Azure Site Recovery
Blogs
calista technologies
Certificates
citrix
Cloud Computing
Cluster
clustering
community
cross platform management
DDA
debugging
DELL
Disaster Recovery
DR
draas
dynamic memory
enhanced session mode
enterprise strategy group
esx
Events
ExpressRoute
failback
failover
failover types
FAQ
guarded fabric
guest blog post
High Availability
hp
hrm
hvr
hyper
hyper v
hypervisor
hyper v linux
hyper v linux novell red hat
hyper v manager
hyper v replica
hyper v replica broker
hyper v ux
ibm websphere
inmage
insiders
integrated virtualization
Intel
INTEROP
interop vendor alliance
iSCSI
kroll
labs
linux
lis hyperv linux
livemeeting
live migration
Management
Management Tools
mark bowker
microsoft advanced group policy management
microsoft application virtualization
microsoft assessment and planning map tool
microsoft asset inventory service
microsoft desktop optimization pack
microsoft hyper v server
microsoft system center desktop error monitoring
mls property information network
mms
mvp summit
NAT
NET
NetApp
network
Networking
Network Virtualization
novell
online memory resize
opalis
optimization
Pages
pass through
pci
pfo
physical
planned failover
PowerShell
powershell direct
power usage effectiveness
Preview
privacy
Private Cloud
protect
Proxy
quick migration
Red Hat
remotefx
replica
riverbed
scvmm 2012 r2
Security
server16
server app v
shieldedvm
shielded vm
small and medium business
SMB
softgrid
sporton international
SQL Server
state of indiana
static memory
Storage
sun
Survey
svvp
swedish medical center
symantec
System Center
system center 2012
system center 2012 releases
system center configuration manager 2012
System Center Virtual Machine Manager
target
teched europe 2010
test failover
twitter
ubuntu
unplanned failover
vagrant
VDI
Veeam
Video
virtual
virtualbox
virtual desktop architecture
Virtualization
virtualization amd
virtualization management
virtuallization solution accelerators
virtual machine
virtual machine connect
virtual pc
virtual server
virturalization
virutal machine manager
Visual Studio
vm
vmconnect
VMM
vmm 2008
VMware
volume snapshot
vss
vtpm
Windows 10
Windows Server
windows server 2008
windows server 2008 r2
windows server 2008 r2 sp1 rtm
windows server 2012
windows server 2012 r2
Windows server 2016
windows server 8
windows virtualization
windows virtual xp mode
wmi
ws2012
xenapp
xendesktop
xendesktop 7
xenserver
- Home
- Windows Server
- Virtualization
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed

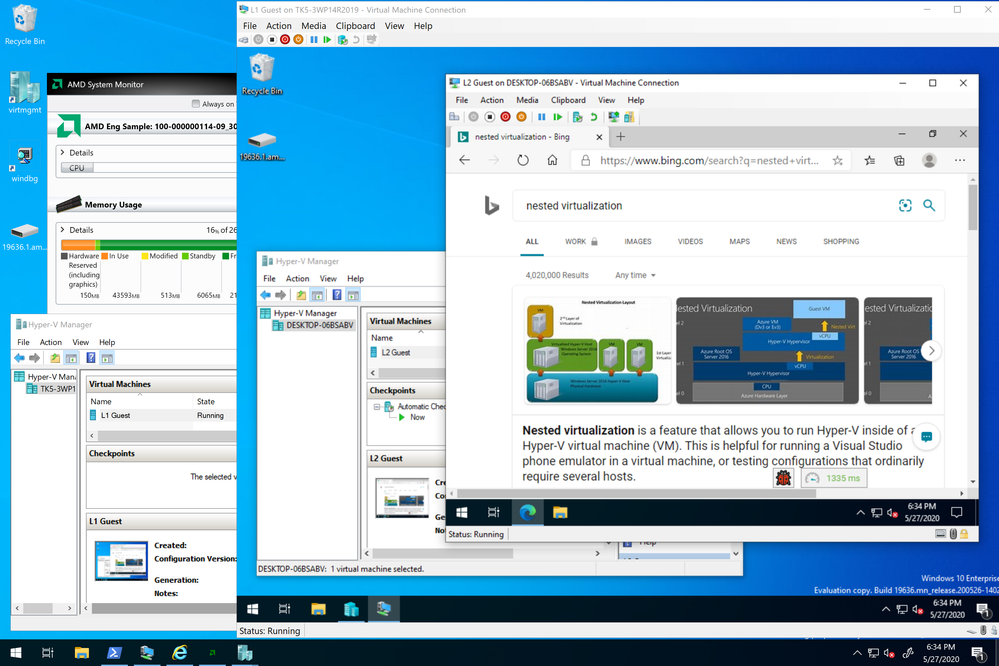


22.1K


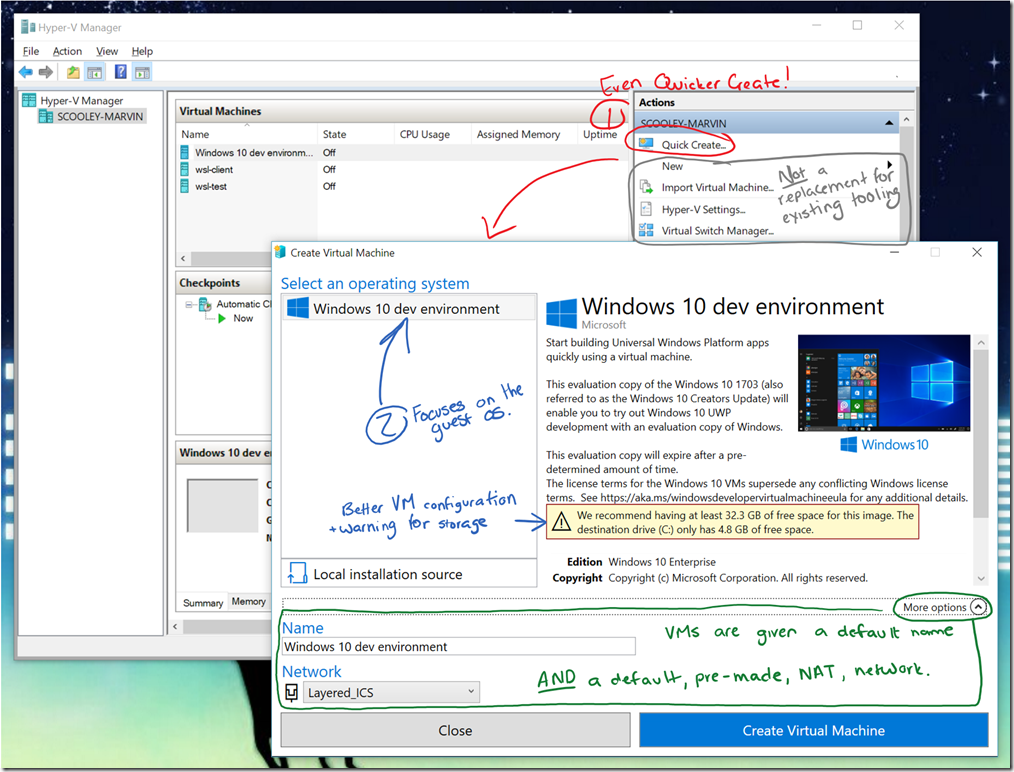
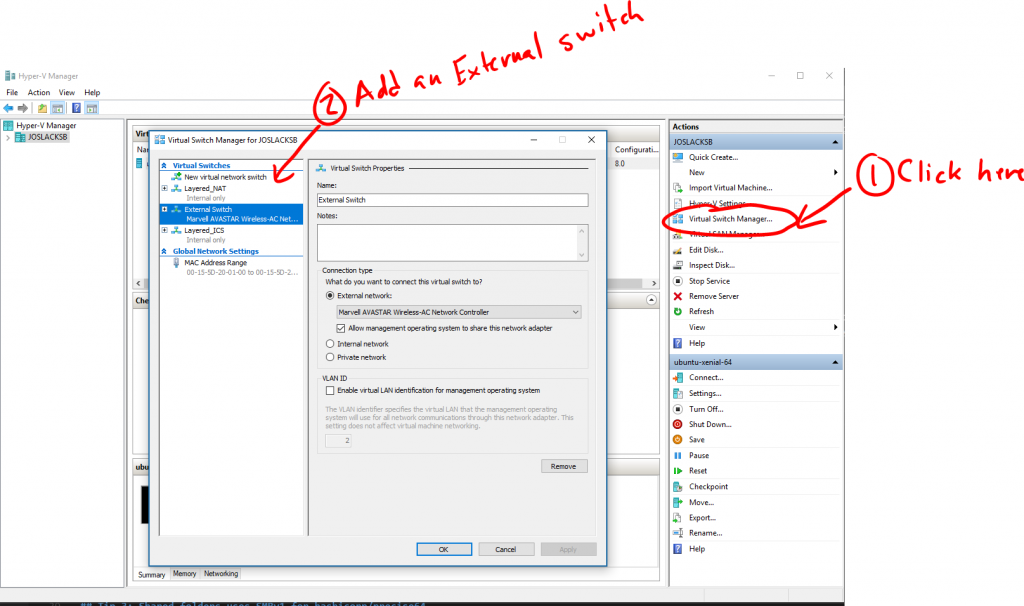


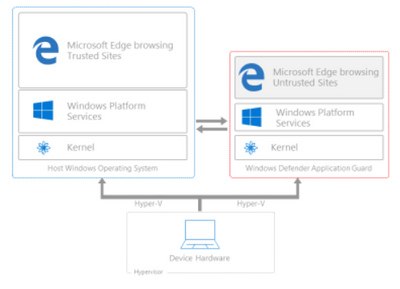
6,927


18.5K
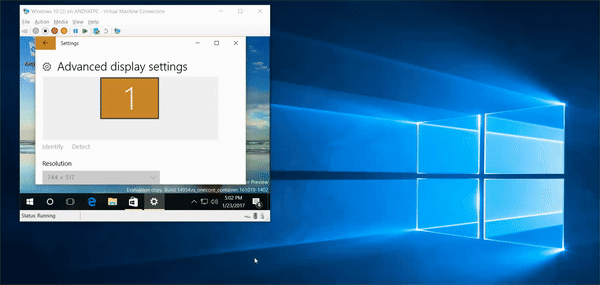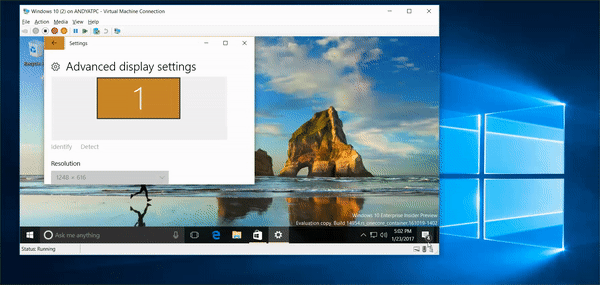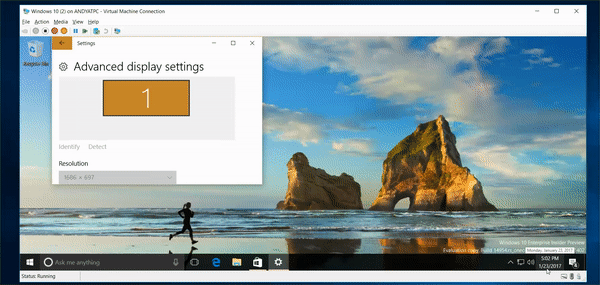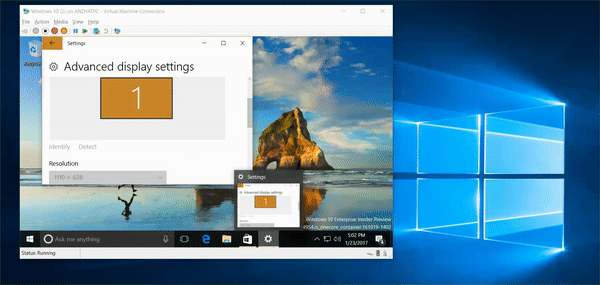

6,518

Latest Comments