How Parquet.Net from Elastacloud Will Empower your Big Data Applications
 By Andy Cross, COO of Elastacloud
By Andy Cross, COO of Elastacloud
You may have heard of Apache Parquet, the columnar file format massively popular with at scale data applications, but as a Windows based .NET developer you've almost certainly never worked with it. That's because until now, the tooling on Windows has been a difficult proposition.
Parquet tooling is mostly available for Java, C++ and Python, which somewhat limits the .NET/C# platform in big data applications. While C# is a great language, we developers lagged behind our peers in other technology spheres in this area.
According to https://parquet.apache.org:
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
Before now, "regardless of the […] programming language" had a subtext of "provided it's not .NET".
What is Parquet.Net?
Changing all of this is the new Elastacloud sponsored project, Parquet.Net. Fully Open, licensed under MIT and managed on Github, Parquet.Net is a library for modern .NET that enables the reading and writings of Parquet files inside the .NET framework. Distributed on NuGet, Parquet.Net is easy to get started with, and is ready to empower your Big Data applications from your enterprise .NET platform.
What Scenarios would I use Parquet.Net?
E-commerce company BuyFashion.com, an up and coming online fashion retailer, have experienced enormous sustained growth over the past five years. They have recently decided to build a team of Data Scientists in order to take advantage of the analytics edge that they have long been following in the tech media.
Their existing platform is a Microsoft .NET Framework ecommerce system and the majority of their existing team are skilled in C# and familiar with building large scale applications in this stack. The company’s new Data Science team have chosen to use Apache Spark on top of Azure HDInsight and are skilled in Scala and related JVM languages.
The Data Science team need to consume feeds that come from the core engineering team so that the system interoperates in a seamless manner. The initial implementation interoperates based on a JSON message format. Whilst this is simple from the point of view of the core engineering team, it places a significant burden on the Data Science team, as they have to wrangle the data. 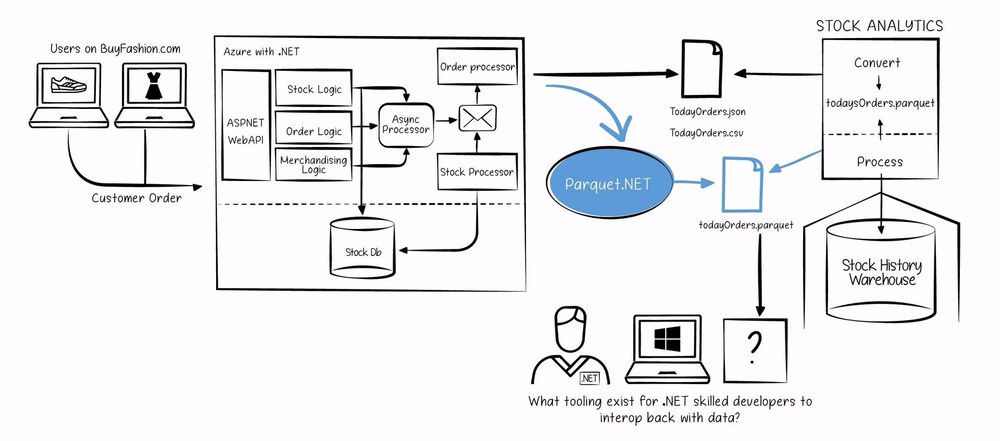
Thankfully, the core engineering team discovered Parquet.Net, meaning that they can eliminate the need for wrangling the Data Science team need to do by natively writing the interop feed in Parquet directly from .NET. As shown above in blue, the new piece of the tooling puzzle solves significant complexities in the Data Science process.
How do I use Parquet.Net?
Reading files
In order to read a parquet file, you'll need to open a stream first. Due to the fact that Parquet utilises file seeking extensively, the input stream must be readable and seekable. This somewhat limits the amount of streaming you can do, for instance you can't read a parquet file from a network stream as we need to jump around it, and therefore you have to download it locally to disk and then open.
For instance, to read a file c:\test.parquet you would normally write the following code
using System.IO;
using Parquet;
using Parquet.Data;
using(Stream fs = File.OpenRead("c:\\test.parquet"))
{
using(var reader = new ParquetReader(fs))
{
DataSet ds = reader.Read();
}
}
this will read entire file in memory as a set of rows inside DataSet class.
Writing files
Parquet.Net operates on streams, therefore you need to create it first. The following example shows how to create a file on disk with two columns - id and city.
using System.IO;
using Parquet;
using Parquet.Data;
var ds = new DataSet(new SchemaElement<int>("id"),new SchemaElement<string>("city"));
ds.Add(1, "London");
ds.Add(2, "Derby");
using(Stream fileStream = File.OpenWrite("c:\\test.parquet"))
{
using(var writer = new ParquetWriter(fileStream))
{
writer.Write(ds);
}
}
What about quick access to data?
Parq is a tool for Windows that allows the inspection of Parquet files. There are precious few tools that fit this category, and so when we were investing into Parquet.Net we thought we'd build a console application that at least begins to address the deficit.
There are three distinct output formats that the parq tool supports:
- Interactive
- Full
- Schema
The Interactive mode transforms the console into a navigation tool over the parquet file you supply. You can use the arrow keys to move around the dataset and look at summarised data.
The Full mode outputs the whole summarised dataset to the console window, with columns truncated at a configurable size but designed to allow tooling interoperability with a formatted output.
The Schema mode outputs the list of columns, which is useful if you're a developer looking to wrap Parquet data sets into strongly typed models.
Next Steps
Visit here to find resources and additional information about the Parquet.Net project.