The world of security defenders verses attackers, hackers and lions
 By Lesley Kipling, Forensic Security expert, Microsoft Global Business Support.
By Lesley Kipling, Forensic Security expert, Microsoft Global Business Support.
I’m back this month with another installment from the world of security defenders verses attackers, hackers, lions (ok perhaps not the lions)!
Organisations are continuing to fall to attackers. There’s another spate of news headlines this month with yet another organisation suffering major damage to its reputation.There are two approaches to risk and impact, quantifying the loss or qualifying the loss and it’s hard to do either with something as intangible as loss of reputation. Consequently, this month I thought I would talk about security incident response (IR) and its role in protecting companies from undue harm.
Assume Breach is a tenet of the Microsoft PtH whitepaper and actually has been echoing around the industry for a while now. The Assume Breach mindset doesn’t necessarily mean that the organisation is in fact compromised, but the phrase is intended to urge organisations to take action to check if they have been the focus of an attacker. Further, it is intended to encourage organisations to look at their critical systems and data and the controls implemented to protect them from the viewpoint of the attacker. Many industry defenses are focused around preventative measures, but as no preventative measure can ever be completely successful at protecting against human adversaries, the industry is also focusing on improving detection capabilities.
In the light of recent high impact, high cost and highly visible attacks, and given that we now live in a world of targeted threats focused on specific organisations, success in today’s cyber world is measured by an organisation’s end to end strategy alongside the ability to rapidly detect and appropriately respond. From an experience perspective, personally I do not hold with the view that detection is the new prevention; rather it’s about an organisation’s end-to-end strategy. Of course, without detection there can be no response and in the case of many of the customers we work with the detection capability is startlingly low.
Often times, event logs are overwritten or not removed from machines in real-time, so the trail of evidence is either incomplete or missing in its entirety. This means the incident response team may not be able to find root cause or may miss indicators of compromise that will allow the attacker to persist inside the organisation on remediation. A predefined incident response process and an effective and efficient computer security incident response (CSIRT) team capable of protecting, detecting and responding to security-related incidents in a proactive manner is vital to minimizing loss and destruction to organisational assets and services.
Security incident response is the one of the key components in today’s information technology (IT) security programs when dealing with cybersecurity-related attacks. The industry uses a diverse set of terminology when referring to the various stages of an incident response lifecycle, but Microsoft uses Protect, Detect, Respond as the main phases, with the response phase broken down further as necessary as per the graphic below.
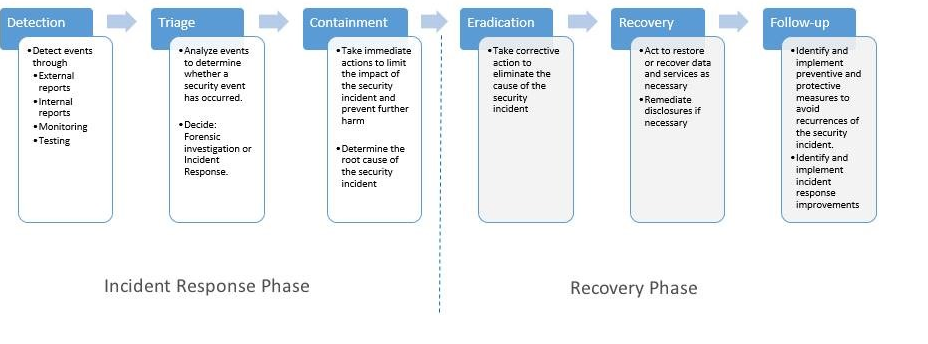
The Protect phase reflects the existing people, process and tools put in place to counter the threats of concern to the organisation, the determination of which is done as part of regular risk and business impact assessments. Depending on whose statistic you read, an attacker’s meantime to compromise (MTTC) is in the range of 24 to 48 hours. This is the average time it takes for a hacker to decide to compromise the organisation and to be successful in his objective. Increasing the time it takes for a hacker to penetrate a company is the result of a well-planned defense in depth strategy. For example: A simple mitigation against compromised domain administrators? Don’t have any. Our best practice recommendations include using just in time administration (JITA) to keep the groups empty and add the administrator accounts only when needed to admin the domain and only for time required to perform the task. Audit for the attempted use of these accounts outside of change control and you have yourself a super detection mechanism for unauthorized use of highly privileged accounts.
The Detect phase has its own industry statistic in that, on average, the time it takes to detect the attacker in the organisation is anywhere from 100 to 280 days. From the data we have at Microsoft, we see that the average time for this detection is currently 229 days, which obviously gives the attacker the clear advantage. The detect phase needs to be focused on decreasing the mean-time to detection (MTTD) while an emphasis is placed on increasing the detection capability of the organisation and hence it’s detection maturity.
The Respond phase contains the stages: Triage, Containment, Eradication, Recovery and Follow-up, but the CSS Security team group them into two broad categories of Incident Response and Recovery. Why do we divide out the Respond phase into IR and recovery? Simply because moving into the recovery phase impacts the incident response phase. Containment is a part of the IR phase because this limits the ability of the attacker to have unfettered access to the organisation whilst a triage is performed. An extreme example of this might be to disconnect the organisation from any remote access until the investigation is done. The point being though that no changes are made. As soon as an organisation updates AV signatures to detect malware or initiates system rebuilds, for example, the ability to find root cause or patient zero (the first machine compromised by the attacker) will be impacted. Consequently the CSS Security team use a mantra of: Stay Calm, Do No Harm and engage the right people. Of course, it really helps to have planned your response, pre-determined the data to gather in a forensically sound way and ensured that your IR team is fully trained to respond suitably to every category of incident, prior to an incident happening.
As the alert and awake bunch you are, you may have noticed that the Triage stage contains a decision to do a forensic investigation or an IR investigation. Why? Glad you asked! The term forensic has come to mean the application of science to help solve a legal problem. Given the fragility of digital data, there are certain restrictions in the processes used to examine this data to ensure the evidence is “admissible” – legal rules which determine whether potential evidence can even be considered by a court. Over the years this has comes to mean examination of the hard drive of the computer following certain court approved procedures. Obviously then, investigations of disks takes skill, training and most importantly time and time is something organisations do not have in an incident.
So how do we balance the need for speed in an incident with ensuring the evidence is collected correctly? With foresight and aforethought and setting up proactively for what I call forensic incident response. For example, ensure that all your sensitive machines have the system drive mirrored, where mirroring is an automated process of writing data to two drives simultaneously. Using a hardware mirror with true hot-swappable capability means you can pull one of the drives, set this aside for a full forensic investigation and continue with incident response data collection for the triage stage on the running system, with minimal impact to the business. At the very minimum though, audit logs and other event logs such as firewall logs are essential data required to investigate a security incident. It is hard to overstate the importance of correctly configured auditing and logging. Treat logs with the respect they deserve and get them off the machines in real-time to a backend SQL database behind a firewall, ensuring that domain administrators have Read-Only access and audit for access to the database.
Before this turns into a whitepaper, I’ll sign off now.
Watch out for those lions! Best wishes for 2015.