Exchange 2013 High Availability
Iki bölümlük bu makale dizisinde Exchange 2013’le gelen yüksek erisilebilirlik çözümlerinden bahsediyor olacagiz.Ayrintilarini bulacaginiz konu basliklari ise su sekilde:
* Multiple Databases Per Volume
* Automatic Reseed
* Safety Net
* Lagged Copy’deki gelismeler
* Site Resilience
Multiple Databases Per Volume
Her bir volume’da birden fazla database tutabilme özelligi.
Günümüzde tasinabilir disk’lerin bile birkaç TB boyutuna ulastigini düsünürsek, disk kapasitesinde son yillarda yasanan ivmeli artisi görmüs oluruz. Bunun yaninda Exchange tarafindan baktigimizda
önerilen maksimum database boyutu 2 TB ile sinirlidir ve hatta bu boyutlara pek yaklasmadan ikinci bir database ile devam etmeniz yönetimsel açidan faydali olacaktir. Ne kadar büyük database’e sahip olursak o kadar backup – restore
islemleri uzayacak, database recovery islemleri daha uzun zamaninizi alacaktir. Kopyalardan birinde bir sorun oldugunda reseed islemi bir kabus haline gelip birkaç gününüzü bile alabilir.
Diger taraftan 8TB’lik bir disk alip en fazla 2TB’ini kullanmak pek mantikli görünmüyor! Exchange 2013 bu duruma karsi “Multiple Databases Per Volume” kavrami ile karsimiza çikiyor. Bu özellik sayesinde:
- Database size’larini daha küçük boyutlu tutarak, sorun oldugunda daha hizli recovery imkani sunuyor.
- Reseed islemleri daha güvenilir ve hizli yapilabiliyor.
- Disklerinizi daha verimli kullanmanizi sagliyor.
Yalniz bir volume’da birden fazla database tutabilmek için simetrik bir kopya database dagilimi gerekli. Örnegin bir volume’da 4 database tutacaksaniz, her bir database’in 4 kopyasi bulunmali.
Yani 4 mailbox sunucunuz olmali. Asagidaki diagramda örnek bir konfigürasyon bulunmakta:
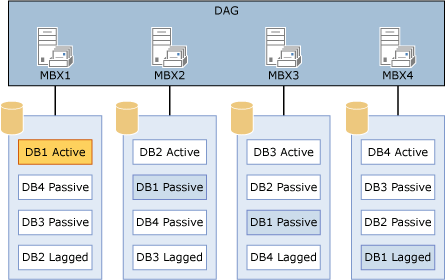
CheckpointDepth: Bu deger Exchange 2010’da aktif kopya için 100 MB, pasif kopya için 5 MB iken; Exchange 2013’de pasif kopya için de 100 MB’a çikarildi. Bu sayede disk IOPS degerlerinde düsme saglanirken, diger bir avantaj olarak failover gerçeklesme zamanlarinin 2 kat hizli oldugu gözlemlendi.
Automatic Reseed
Disk’de yasanabilecek bozulma gibi Reseed’i gerektirecek durumlarda islemlerin manual degil de otomatik yapilmasini saglayan bir özelliktir. Bunun için yedek bir diskin olmasi ve gerekli konfigürasyon ayarlarinin yapilmasi sart. Disk failure durumunda sistem bu yedek diski sorunlu diskle replace ederek, otomatik reseed islemini baslatir. Failure durumunu farkedebilmek için sistem, database’lerin saglikliligini düzenli olarak kontrol eder. Sorun görüldügünde de sorunlu disk’te yer alan database’ler, automatic reseed devreye alinarak yeniden olusturulur. Öncesinde yapilan simetrik kopya dagilimi sayesinde database kopyalari farkli sunucularda aktif
oldugundan reseed için kullanilan kaynak sunucu da farkli sunucular olacak ve islem paralel olarak yapildigindan bu da reseed süresini kisaltacaktir.
Auto reseed ile gelen DAG parametreleri ise sunlardir:
AutoDagVolumesRootFolderPath – Tüm volume’larin, spare volume’lar da dahil, yer aldigi mount point’i isaret eder
AutoDagDatabasesRootFolderPath – Database’lerin yer aldigi mount point’i isaret eder
AutoDagDatabaseCopiesPerVolume – Volume basina kaç database tutulacagini gösterir
Safety Net
Exchange 2010’da mail akisinda yasanabilecek bir soruna karsi kullandigimiz teknolojiler olarak Shadow Redundancy, Transport Dumpster, Delayed Acknowledgement ve mesajin belli süre ilgili queue’da beklemesini gösterebiliriz.
Exchange 2013’de yeni bir terim karsiliyor bizi, Safety Net. Transport Dumpster’in yerini alan Safety Net, Transport Dumpster’dan farkli olarak feedback mekanizmasiyla çalismiyor. Her aktif database kopyasinin kendine özel bir Safety
Net queue’su bulunur. Sunucu tarafindan basari ile islenen maillerin bir kopyasi bu queue’da toplanir ve varsayilan olarak 2 gün boyunca bu queue’da kalir, istenirse bu süre degistirilebilir. Örnegin 3 güne çikarmak için asagidaki gibi bir komut çalistirmaliyiz:
Set-TransportService MBXServerName -MessageExpirationTimeout 3.00:00:00
Transport Dumpster sadece DAG ortaminda geçerli idi. Safety Net için ise böyle bir sart gerekmiyor. DAG olmayan bir ortamda islenen maillerin bir kopyasi ayni site’daki diger mailbox sunucuda tutulur.
Transport Dumpster’da mesajin kopyasi bir sunucuda tutulurken, Safety Net için single point of failure durumu yoktur. Primary Safety Net ve Shadow Safety Net adiyla iki farkli Safety Net’den bahsedebiliriz. Eger Primary Safety Net 12 saatten fazla erisilemez durumda kalirsa, resubmit istekleri shadow resubmit isteklerine dönüsür ve mesajlar Shadow Safety Net’den geri alinir.
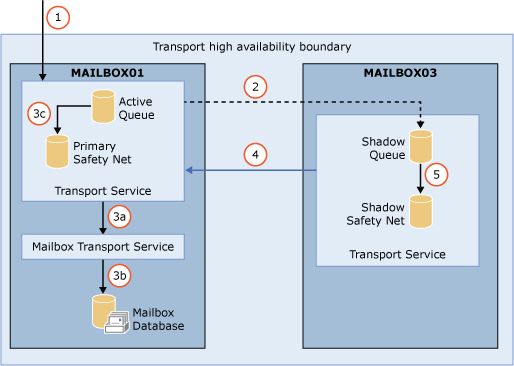
Bu sebeplerle Exchange 2013’de “Guaranteed delivery” diye bir kavramdan bahsedebiliriz. Son bir bilgi, Safety Net için belirli bir boyut belirlemezsiniz, sadece mesajin Safety Net’den ne kadar süre sonra silinecegini belirlersiniz.
Kalan konularimiz Lagged Copy’deki gelismeler ve Site Resilience için “Exchange 2013 High Availability – Bölüm 2” makalesini inceleyebilirsiniz.
Sevgi Sifyan