Improve navigation through search results using refiners based on custom entities
Audience: Search Admin/ITPro
Pre-requisite: This post assumes the reader has basic Search Administration knowledge.
If you want to ease navigation through your search results and your documents already have metadata, you can enable refiners based on this metadata. But what if the documents don't have this specific metadata that you want to refine on? In that case, you still have a way to quickly narrow down your search results and create refiners based on custom entities that you extract from the document content.
Let's say your organization, Contoso, has a certification program with several certification titles that you want to use to refine your search results on. The following steps show how you can extract these certification titles from the body and the title of your documents and how to create refiners based on these.
1. Create a .csv file containing the list of Contoso certification titles and import this dictionary via the PowerShell cmdlet Import-SPEnterpriseSearchCustomExtractionDictionary.
This is an example dictionary:
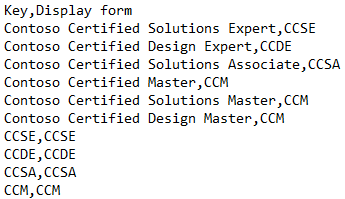
The dictionary allows you to specify not only what to match (Key) but also how to present it in the refiner (Display form). Using the Display form allows you to map different variations to one standard title. In this example, "Contoso Certified Master", "Contoso Certified Solutions Master", etc. are all shown as "CCM".
When you import the dictionary with Windows PowerShell, you have to define the type of custom entity extractor. Which type you choose depends on how you want to match the entities in the content. You can do case-sensitive or case-insensitive matching on words or word parts. For this example, you want to enable case-insensitive matching on complete words, and therefore you would choose custom word extraction by specifying Microsoft.UserDictionaries.EntityExtraction.Custom.Word.1 in the Windows PowerShell cmdlet. If your content is written in a language that is not space-separated (for example, Japanese), you should consider matching on word parts.
2. Enable custom entity extraction on document content.
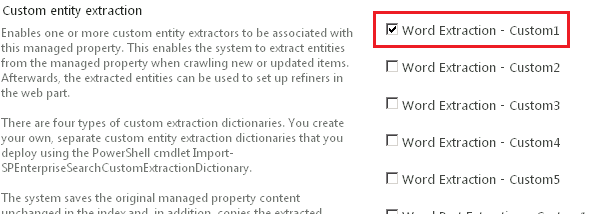
Go to the search schema and configure the managed properties "body" and "title" by enabling the custom entity extractor type that you want to implement. This should be the same type as the type that you specified when you imported the dictionary in step 1.
In this example, you would enable "Word Extraction - Custom1" since you have imported this type of dictionary in step 1:
3. Crawl your document collection.
Once you have imported the dictionary and enabled custom extraction on one or more managed properties, you have to complete a full crawl of your content.
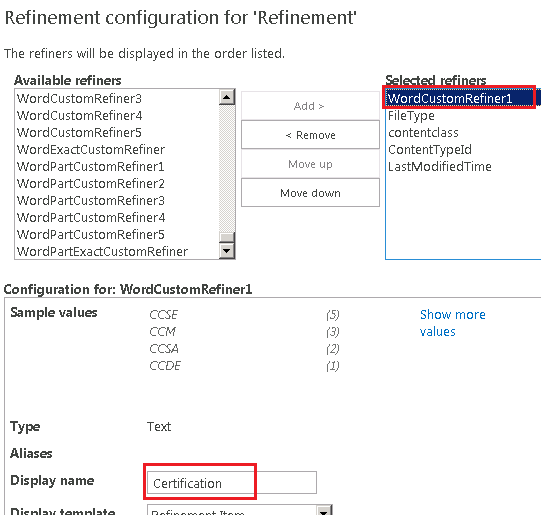
4. Enable your new Contoso certification refiner.
Edit the Refinement Web Part on your search results page to enable your custom refiner.
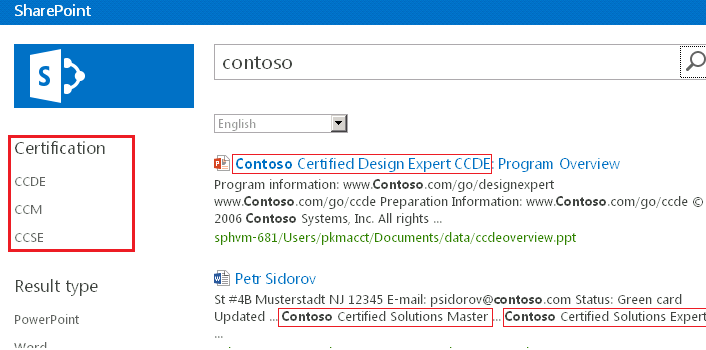
Here you go! The search results page will now contain the refiners based on your custom entity extractors:
For more details, you can check documentation at https://technet.microsoft.com/library/jj219480.