How can I achieve the best freshness of search results? Introducing Continuous Crawls for SharePoint
Audience: Search Admin/ITPro
Pre-requisite: This blog assumes the reader has basic Search Administration knowledge around SharePoint Search topology, crawl mechanism, and the principles of crawl scheduling.
Note: This feature is new for SharePoint 2013.
What is freshness of search results?
After a user uploads a document to his SharePoint Site, the period of time before that document is available to be ‘searched’ through the SharePoint Search portal indicates the latency of freshness.
What does freshness depend on?
Multiple factors – size of repository, change rate, request response time from repository, crawl schedule, types of changes. This is because, to make a document available to ‘search’, a crawl needs to be triggered (either manually or automatically-by-schedule), the change needs to be identified, requested and processed.
So, what’s the problem?
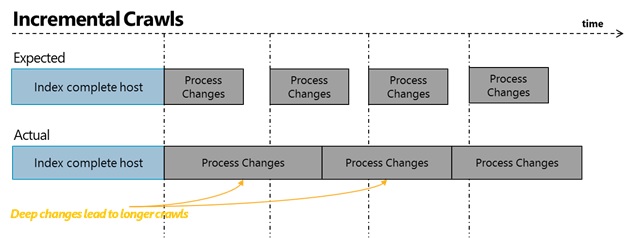
Traditionally, we’ve had two schedule options in SharePoint Search – Full or Incremental Crawl. A full crawl kicks-off discovery of the entire host, while an incremental crawl only processes those items in the host that have changed since the last time a crawl happened, either using time stamp comparison of each document or leveraging a pre-existing change log for that repository that tracks documents that are modified. In order to achieve higher freshness, the recommended approach has been to make the incremental crawl more aggressive (i.e. every 30mins vis-à-vis every day).
One of the limitations of Full and Incremental Crawls is that they cannot run in parallel, i.e. if a full or incremental crawl is in progress, the admin cannot kick-off another crawl on that content source. This forces a first-in-first-out approach to how items are indexed. Moreover, some types of changes result in extended run times (e.g. a policy change at the root level of a host means the entire host needs to be re-indexed to update the
security descriptor of each item indexed). These two factors combined result in fluctuating freshness even when a frequent incremental crawl schedule is set. To illustrate this, below is the expected mental model of incremental crawl compared with real-world, followed by the freshness of that system.
So what’s the fix? Introducing Continuous Crawl
I recommend a crawl option for SharePoint-type content sources that provides a schedule free alternative to managing a content source. The underlying architecture is designed to ensure consistent freshness by
overcoming the two fundamental limitations of Full/Incremental Crawls:
- they can run in parallel
- one deep change will not result in degraded freshness on all following changes
Tell me more…
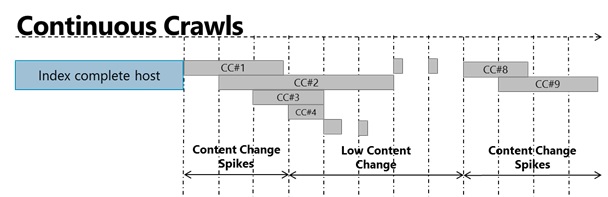
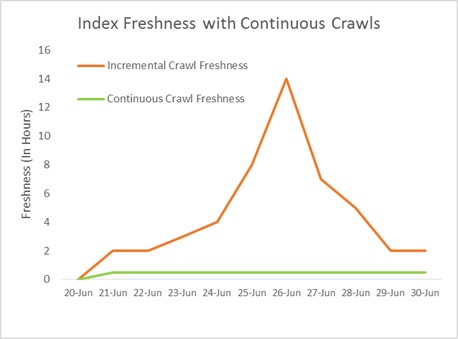
Behind the scene, continuous crawl selection results in the kick-off of a crawl every 15minutes regardless of whether the prior session has completed or not. This means a change that is made immediately after a deep change doesn’t need to ‘wait’ behind. New changes will continue to be processed in parallel as a deep policy change is being worked on by another continuous crawl session. Here’s an illustration of how continuous crawls are spun-up every 15minutes in parallel that helps manage sudden content spike without affecting overall freshness. The following graph illustrates the impact on freshness achieved by using continuous crawl over incremental crawl.
So, what else do I need to know?
In subsequent blogs, we will review in greater detail how continuous crawl handles different types of scenarios (errors, security etc.) and how you can use the crawl log and crawl history to get a better understanding of what’s happening underneath the covers.
FAQ:
Can I use continuous crawl for all types of content sources.
No. Continuous Crawls are available only for SharePoint-type content source. All other types of content sources will continue to have incremental and full crawl as options.
Will using continuous crawl add additional load on the repository?
Continuous crawl foot print is similar to incremental crawl. While the frequency at which requests are made have increased, the maximum number of simultaneous requests on one repository/host will still be controlled by *Crawl Impact Rules* (which define the maximum number of simultaneous threads that can make requests, which by default is set to 12threads, but can be modified per business requirement and/or capacity plan).
Do I need to set an incremental crawl or full crawl when using a continuous crawl?
Incremental crawl does not need to be configured with continuous crawl.
Will continuous crawl add additional load on the host/repository?
Continuous crawl will increase load marginally on the host since it inherently can run parallel multiple sessions simultaneously. However, it should be noted that it will conform with ‘Crawl Impact Rule’ setting which controls the maximum number of simultaneous requests that can be made to a host (which OOB is set to 12 threads, but can be changed)
Can I use continuous crawl to crawl previous versions of SharePoint content?
Yes -- while the Search Application needs to be of 2013, content farms running older versions of SharePoint can be configured to be crawled continuously.