Rethinking Enterprise Storage – Taming the Capacity Monster
Recently, Microsoft published a book titled Rethinking Enterprise Storage – A Hybrid Cloud Model – the book takes a close look at an innovative infrastructure storage architecture called hybrid cloud storage.
Last week we published experts from Chapter 3. This week we provide an excerpt from Chapter 4, Taming the Capacity Monster. Over the next several weeks on this blog, we will continue to publish excerpts from each chapter of this book via a series of posts. We think this is valuable information for all IT professionals, from executives responsible for determining IT strategies to administrators who manage systems and storage. We would love to hear from you and we encourage your comments, questions and suggestions.
As you read this material, we also want to remind you that the Microsoft StorSimple 8000 series provides to customers innovative and game-changing hybrid cloud storage architecture and it is quickly becoming a standard for many global corporations who are deploying hybrid cloud storage. You can learn more about the StorSimple 8000 series here: https://www.microsoft.com/storsimple
Here are the chapters we will excerpt in this blog series:
Chapter 1 Rethinking enterprise storage
Chapter 2 Leapfrogging backup with cloud snapshots
Chapter 3 Accelerating and broadening disaster recovery protection
Chapter 4 Taming the capacity monster
Chapter 5 Archiving data with the hybrid cloud
Chapter 6 Putting all the pieces together
Chapter 7 Imagining the possibilities with hybrid cloud storage
That’s a Wrap! Summary and glossary of terms for hybrid cloud storage
So, without further ado, here is an excerpt from Chapter 4 of Rethinking Enterprise Storage – A Hybrid Cloud Model
Chapter 4 Taming the Capacity Monster
Data growth appears to be an unstoppable force in our digital world. The challenge for IT teams is finding solutions that mitigate the storage and management costs of all this growing data and give them a way to accommodate data growth more flexibly in a more orderly, measured fashion. This chapter discusses some of the existing technologies IT teams use to manage their storage capacity and how the hybrid data management architecture of the Microsoft hybrid cloud storage (HCS) solution gives them powerful, new automated tools for managing data growth.
The need for flexible storage
File systems and databases depend on having static, fixed-size volumes to place data in so they can meet performance expectations and identify when storage capacity is running low. From the perspective of the IT team, the combination of static, fixed-sized storage volumes and high data growth rates is an unfortunate mismatch. When an application’s data grows unexpectedly, storage volumes can run out of available capacity and the application may not be able to write data, causing systems to grind to a halt and crash.
The IT team does what it can to prevent this from happening by monitoring capacity levels and setting alerts for capacity thresholds. Despite these warnings, the IT team still has limited time to make difficult decisions about how to best respond, including emergency capacity purchases that are not in the budget, archiving and removing data that might be needed by users, and rebalancing application storage and workloads. Frustrated by chronic interruptions to their work, IT teams seek solutions that allow them to manage storage capacity with more flexibly and less stress and expense.
Migrating data with server virtualization technology
Server virtualization technology enables flexible storage capacity management through storage migration technology, such as the Storage VMotion (SVMotion) feature of VMware’s ESX hypervisors and the Storage Live Migration feature of Windows Server 2012 and Hyper-V.
When a storage system approaches a capacity-full condition, some of the VMs storing their data there can have their data migrated transparently to another storage system.
Here’s how it works. VM data is formatted and stored as a portable storage object called a virtual machine disk (VMDK) in VMware ESX environments or a virtual hard disk (VHD) in Windows Server 2012 Hyper-V environments. A VMDK/VHD on a source storage system can be synchronized with a copy running on a destination storage system. When all the data on the source is synchronized at the destination, the VM switches to using the destination VMDK/VHD. Figure 4-1 illustrates the process of storage migration.
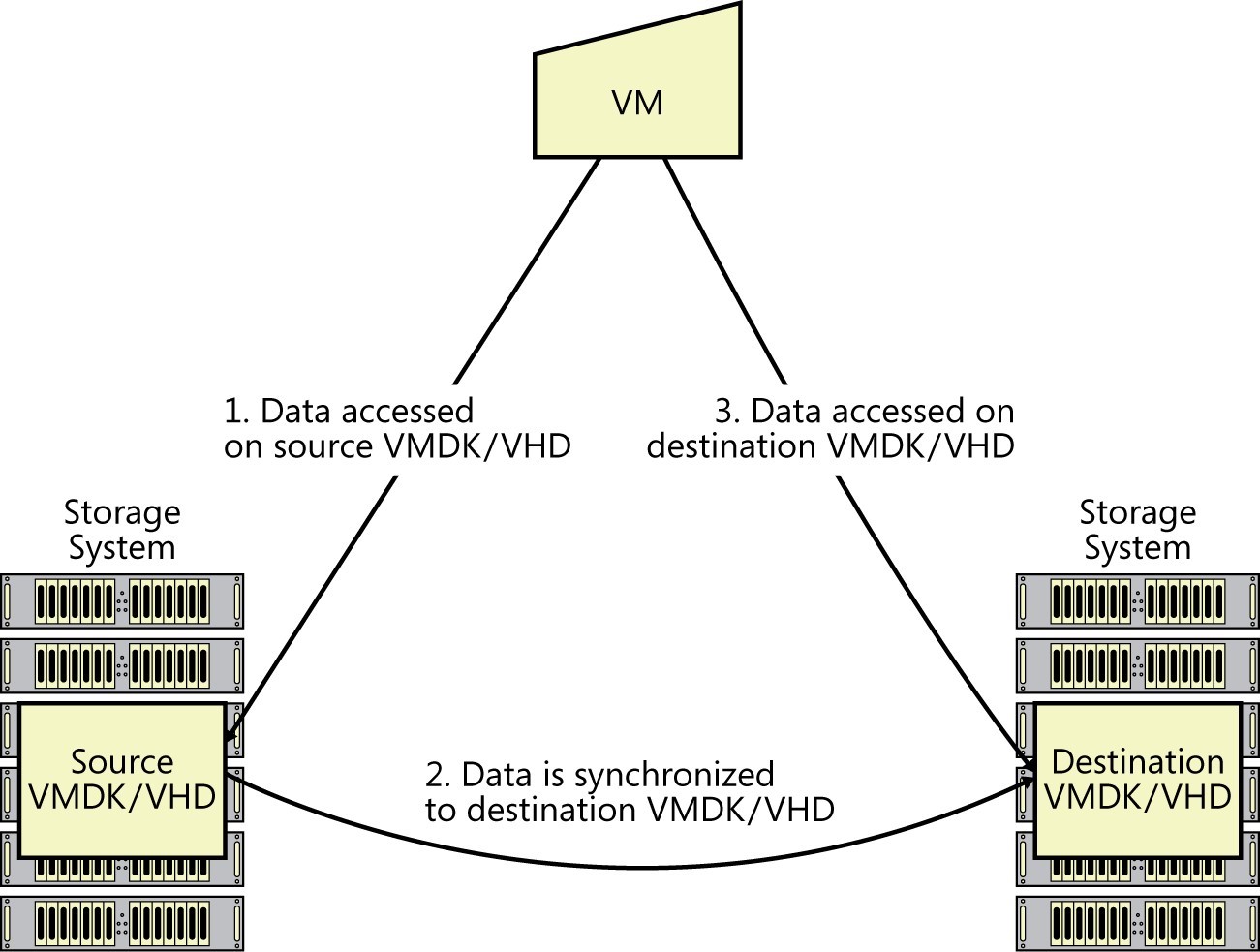
FIGURE 4-1 In storage migration, a VM moves its VHD from one storage system to another.
After the synchronization process has completed and the VM is accessing data from the destination VMDK/VHD, the source VMDK/VHD and all its data can be deleted and its capacity reclaimed and used for other purposes.
Storage migration is a powerful tool for managing data on a storage system that is approaching its capacity limits. Without it, the IT team would have to stop all the applications on the source volume, copy them to the destination volume, redirect the VM to access the volume on the destination, and then bring up the applications. This is a lot of work that involves application downtime and planning.
Storage migration depends on having a suitable destination storage system with sufficient capacity and performance capabilities to accommodate the new workload. Finding a suitable destination storage system becomes more difficult as utilization levels increase across available storage resources.
Thin provisioning brings relief
Thin provisioning technology was briefly discussed in Chapter 1, “Rethinking enterprise storage,” as a means to provide capacity to applications on a first-come, first-served basis. Instead of pre-allocating storage capacity as multiple, fixed-size volumes, thin provisioning aggregates storage capacity into a large, shareable resource and then parcels it out incrementally to elastic, virtual volumes as they need it.
With static provisioning, storage volumes are discrete resources, each with its own bounded address range. As new data is written, the capacity of the specific volume is consumed. With thin provisioning, each volume is expandable, using the shared free space as new data is written. Figure 4-2 compares how capacity is consumed using static provisioning, as opposed to thin provisioning.
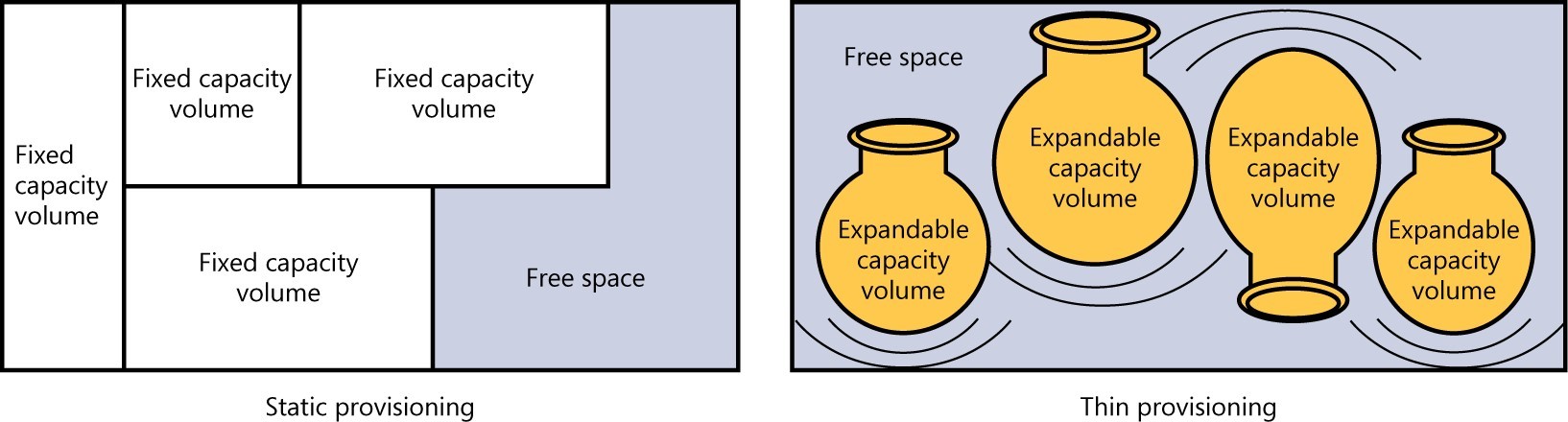
FIGURE 4-2 Acomparison of static provisioning with thin provisioning .
Thin provisioning is widely appreciated by IT teams as a way to flexibly manage storage capacity in response to data growth. As a result, most enterprise storage systems today have thin provisioning as a feature. The Cloud-integrated Storage (CiS) system in the Microsoft HCS solution uses thin provisioning to allocate its internal storage resources to volumes. Some enterprise server software products, such as VMware vSphere and Windows Server 2012, also provide thin provisioning features.
The problem with thin provisioning is that most storage systems have fixed maximum capacities that can become exhausted. As the shared capacity becomes full, applications will start slowing and eventually crash if the IT team does not take action to resolve the situation. Thin provisioning is not a particularly dangerous tool, but it needs to be understood and managed according to best practices. There can be significant differences in how it is implemented. For example, the Microsoft HCS solution does not have a fixed maximum capacity by virtue of its ability to use Microsoft Azure Storage as a tier for data. The expandable free-space resources of Microsoft Azure Storage are used by the Microsoft HCS solution to change the dynamics of thin provisioning, as illustrated in Figure 4-3.
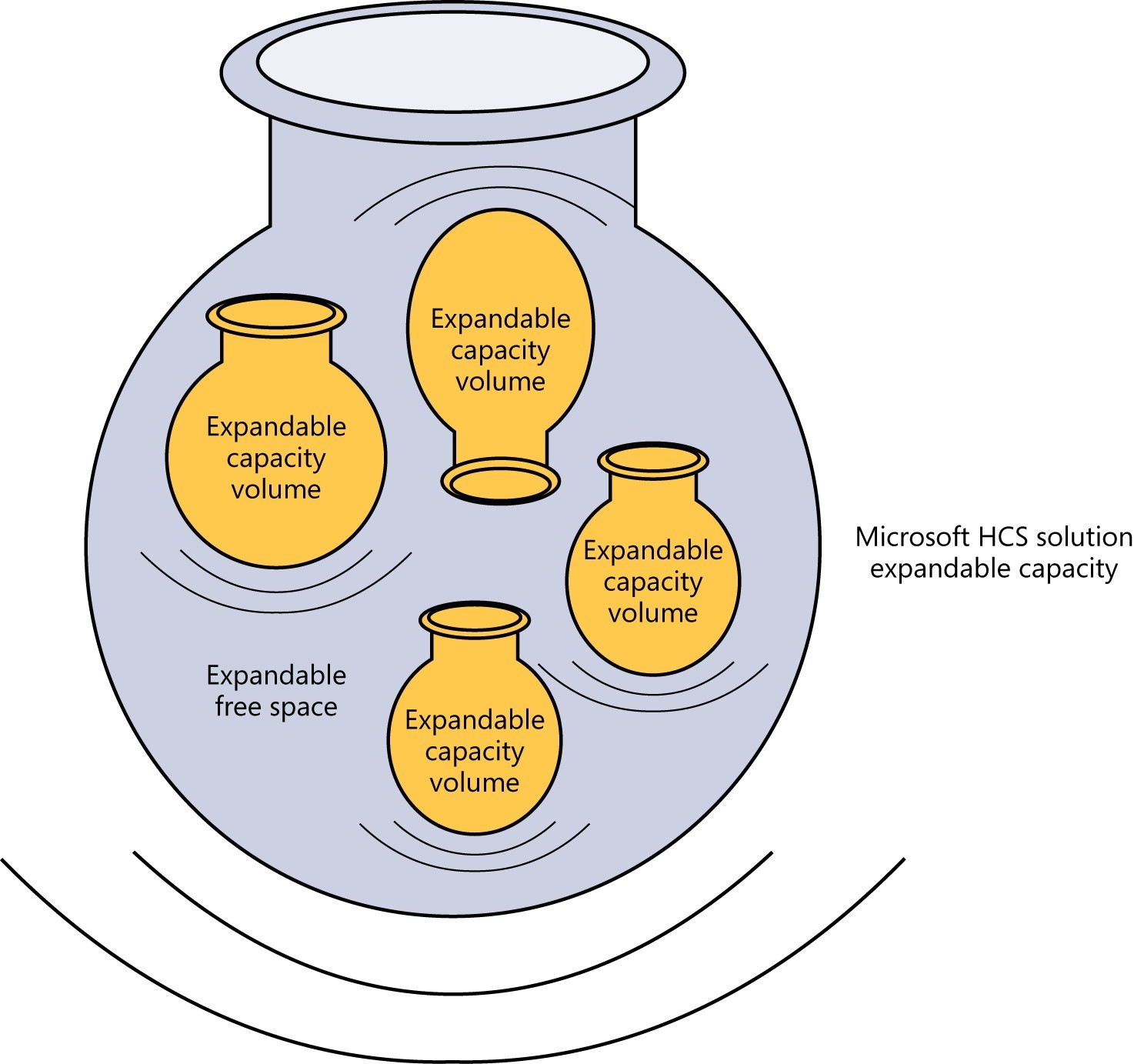
FIGURE 4-3 The Microsoft HCS solution offers expandable capacity for thin provisioning.
Storage architectures: Scale-up, scale-out, and scale-across with cloud storage
Storage systems are typically designed so that customers can purchase some amount of capacity initially with the option of adding more as the existing capacity fills up with data. Obviously, increasing storage capacity is an important task for keeping up with data growth. Scaling architectures determine how much capacity can be added, how quickly it can be added, the impact on application availability, and how much work and planning is involved.
Scale-up and scale-out storage
Storage systems that are not integrated with cloud storage increase their capacity in one of two ways: by adding storage components to an existing system, or by adding storage systems to an existing group of systems. An architecture that adds capacity by adding storage components to an existing system is called a scale-up architecture, and products designed with it are generally classified as monolithic storage.
Storage architectures: Scale-up, scale-out, and scale-across with cloud storage as a tier
Scale-up storage systems tend to be the least flexible and involve the most planning and longest service interruptions when adding capacity. The cost of the added capacity depends on the price of the devices, which can be relatively high with some storage systems. High availability with scale-up storage is achieved through component redundancy that eliminates single points of failure, and by software upgrade processes that take several steps to complete, allowing system updates to be rolled back, if necessary.
An architecture that adds capacity by adding individual storage systems, or nodes, to a group of systems is called a scale-out architecture. Products designed with this architecture are often classified as distributed storage or clustered storage. The multiple nodes are typically connected by a network of some sort and work together to provide storage resources to applications.
In general, adding network storage nodes requires less planning and work than adding devices to scale-up storage, and it allows capacity to be added without suffering service interruptions. The cost of the added capacity depends on the price of an individual storage node—something that includes power and packaging costs, in addition to the cost of the storage devices in the node.
Scale-up and scale-out storage architectures have hardware, facilities, and maintenance costs. In addition, the lifespan of storage products built on these architectures is typically four years or less. This is the reason IT organizations tend to spend such a high percentage of their budget on storage every year.
Scale-across storage
The Microsoft HCS solution uses a different method to increase capacity—by adding storage from Microsoft Azure Storage in a design that scales across the hybrid cloud boundary .
Scale-across storage adds capacity by incrementally allocating it from a Microsoft Azure Storage bucket. This allocation is an automated process that needs no planning and requires no work from the IT team. The cost of additional capacity with this solution is the going rate for cloud storage and does not include facilities and maintenance costs. However, using cloud storage this way involves much higher latencies than on-premises storage, which means it should be used for application data that can be separated by latency requirements—in other words, data that is active and data that is dormant.
Figure 4-4 compares the three scaling architectures.
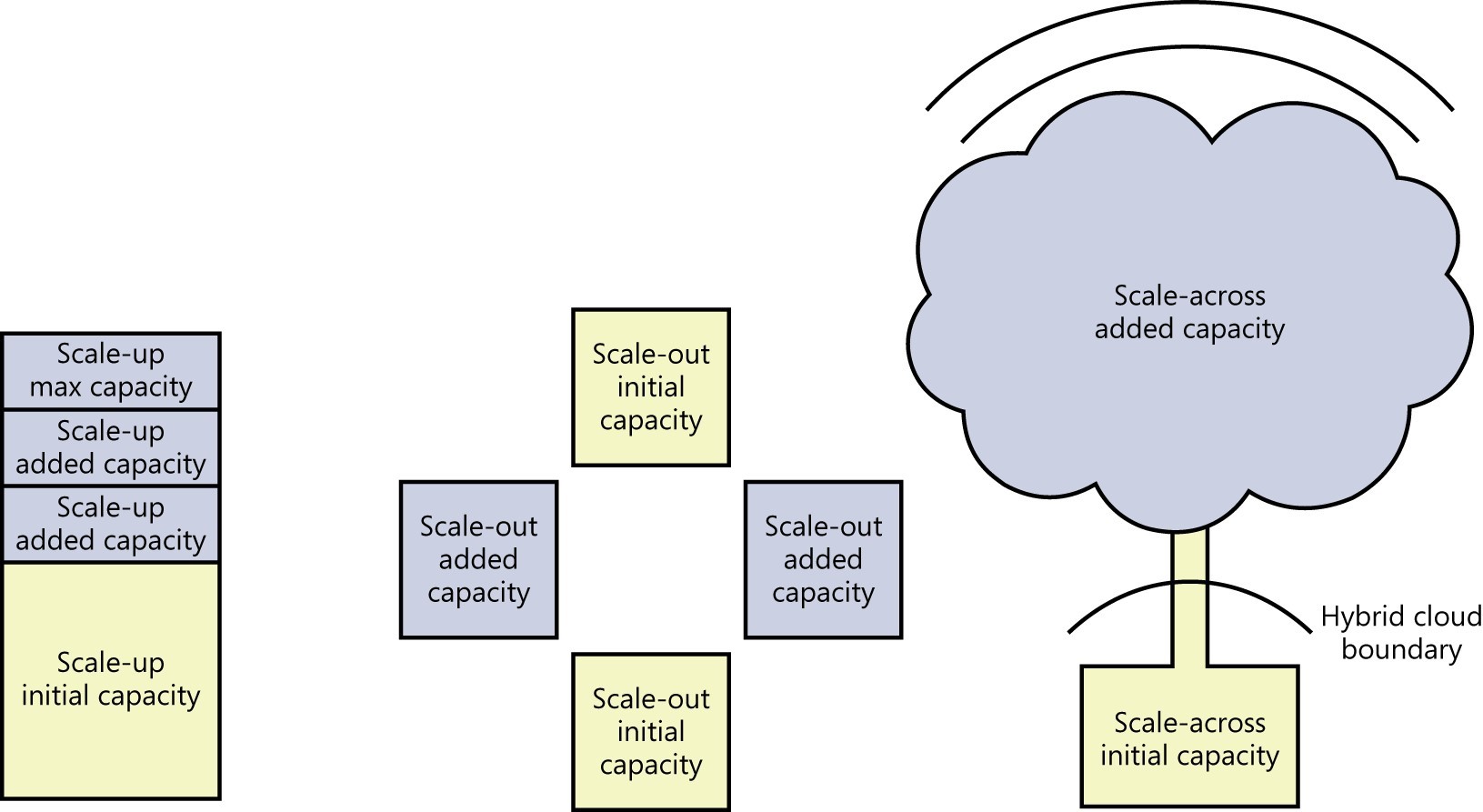
FIGURE 4-4 A comparison of storage scaling architectures .
Separating dormant data from active data with cloud-as-a-tier
Storage tiering is a feature of many storage systems. It is most commonly implemented as a way to place latency-sensitive data on high-performance, low-latency storage such as solid state disks (SSDs) and to place the rest of the data on disk drives. Storage tiering is also often described as a way to generate a high number of I/O operations per second (IOPs) from the optimal number of storage devices—SSDs generate most of the IOPs, while disk drives are responsible for most of the capacity requirements. Cloud-as-a-tier takes this idea one step further, by placing the data that has few to no IOPs on cloud storage.
Chapter 3, “Accelerating and broadening disaster recovery protection,” explains how deterministic, thin recoveries download only the working set and leaving the rest of the data in the cloud. The data that is left in the cloud stays there until it is accessed later, if ever. Viewed from the perspective of storage tiering, this dormant data has no IOPs requirement.
However, CiS systems do not start their existence as recovery targets, but as storage systems that servers use to store their application’s data. In these cases the working set is determined by the frequency that data is accessed—and not by deterministic, thin recoveries. To get a better understanding of how this works, it is important to understand data life cycles.
To learn more about data life cycles, and read the balance of this chapter, be sure to download “Rethinking Enterprise Storage: A Hybrid Cloud Model”