如何寫出高效能 TSQL - 善用提示
本文將分成四大單元,分別帶您了解:
前言
雖然 SQL Server 團隊持續加強自我調校,但這不代表 SQL Server 就不會有效能低落的情況發生,即便您的 SQL Server 是在功能最強大的硬體上執行,效能還是可能因為少數幾個不當 TSQL 受影響,而這也是我們最後要介紹提示 (hint) 的主因,因為大多數情況我們無須強制覆寫執行計畫,主要是查詢最佳化程式品質已越來越高 (查詢最佳化程式可是超過 30 年時間研究開發出來的心血),但有時候您不得不否認使用提示是改善效能的最後手段,但這裡我們必須強調提示要謹慎使用,而有使用提示的那些 TSQL 則必須定期追蹤執行計畫變化,因為隨者時間資料異動或條件改變,提示可能變成導致效能低落的主因。本文會介紹使用提示前須先排除相關問題的前提下來改寫 TSQL,以免發生使用提示還是無法改善效能的情況發生,也會介紹相關提示在什麼情境下使用才能真正改善效能 (水能載舟亦能覆舟),但最後還是要再強調一次,提示必須謹慎使用且定期追蹤。
使用提示前的建議
當您遇到查詢最佳化程式所產生的執行計畫品質不佳時,導致該查詢時間過長,耗用資源過高,建議先確認以下問題不是影響該查詢效能主要因素後,改寫 TSQL 使用提示才能發揮最大效益。
1. 基數估計問題:
上一篇探索統計值一文有提到,雖然 SQL 2014 以前版本的基數估計在大資料表常常不夠準確,當您發現執行計畫中某些運算子基數估計和實際資料筆數差距過大時,請先確認是否因資料採樣率過低、統計值過期或是使用資料表值參數等問題造成,因為透過更新統計值或許就可以解決效能問題而非需要改寫 TSQL 使用提示。
2. 系統問題:
您必須確認效能問題不是因為 CPU、RAM 或 I/O 資源不足所導致,又或是最常見的長時間交易導致長時間封鎖情況,其次就是使用連結的伺服器查詢異質資料庫 (Oracle、mysql 等) 所產生查詢效能低落,這些系統問題就算您使用提示也依然無法解決。
3. 索引設計問題:
正確的索引設計常常是提高效能的關鍵,但誤用索引比不使用索引所造成的效能影響要來的更大,所以您必須確認索引有效性、索引鍵選擇性是否合適,不然就算使用提示也難以大幅提高效能。要了解如何正確使用索引,可參考「如何寫出高效能 TSQL - 關於索引不可不知道的事 」或「SQL Server 索引設計指南」。
4. 大資料表問題:
龐大資料如沒有分散就算使用提示也很難大幅提高效能,分散大資料表建議可使用分割資料表和索引來切割資料並提高基數估計準確率,如要使用分割資料表或許可以參考本文。
提示類型介紹
SQL Server 提示大概可區分以下三類:
1. 資料表提示:用於資料表上並在 From table 後面加上 with 關鍵字。
2. 查詢提示:TSQL 陳述句最後面加上 option 關鍵字,告訴查詢最佳化程式該查詢需要加上某些特別選項。
3. 聯結提示:告訴查詢最佳化程式,該查詢需使用所指定聯結運算子來處理兩個資料表之前的聯結策略。
接下來我們會依序示範幾個案例,讓大家了解如何善用提示覆寫執行計畫並提高效能。
資料表提示
1. FORCESEEK
FORCESEEK 會強制查詢最佳化程式只使用索引搜尋作業,以免因為沒有效率的執行計畫而產生效能問題。尤其當不正確的基數或成本估計造成最佳化程式在計畫編譯時選擇掃描作業 (邏輯讀取過高),這時強制索引搜尋作業可能會有比較理想的效能。
範例參考 - 使用 FORCESEEK 資料表提示
2. FORCESCAN
SQL 2008 R2 SP1 後新增該提示類型,當查詢最佳化程式低估資料筆數又選擇索引搜尋作業時,這時強制索引掃瞄作業可能會產生比較理想的效能。
範例參考 - 使用 FORCESEEK 資料表提示
3.Index
可以強制查詢最佳化程式在處理陳述句時,指定要使用的索引名稱 (一或多個),且每個資料表只能指定一個 index hint,這裡要注意 index(0) 和 index(1) 用法,如有叢集索引存在時,index(0) 會強制執行叢集索引掃描,index(1) 會強制執行叢集索引掃描或搜尋,如果沒有叢集索引時,index(0) 會強制使用叢集索引掃描,index(1)則 會發生錯誤,另外,如有使用該提示,隨者資料異動或條件變更後,必須定期追蹤執行計畫是否有誤用索引情況。
範例
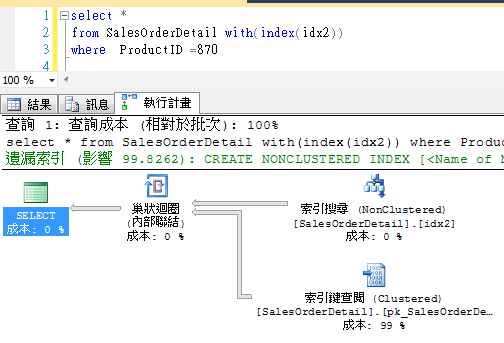
執行計畫中出現索引鍵查閱作業。

查閱作業幾乎都會造成高 I/O 成本。
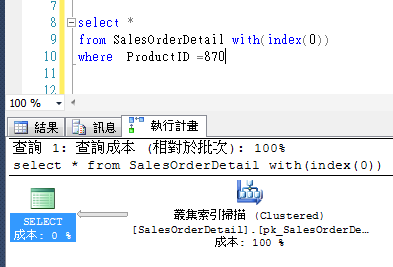

使用正確索引覆寫執行計畫並改善效能。
查詢提示
1. FORCE ORDER
強制保留查詢陳述句所指定的聯結順序。當 TSQL 有 join 和 subquery 一起使用時,透過該提示可能會產生比較理想的效能。
範例參考 - 查詢提示 (Transact-SQL)
2. FAST N
告訴查詢最佳化程式必須快速返回 n 筆資料,剩下資料將會繼續執行直到返回完整結果集,一般長時間查詢 (如報表),透過該提示可能會產生比較理想效能。
範例參考 - [SQL SERVER][Performance] 善用 Fast N Hints
3. EXPAND VIEWS & NOEXPAND
EXPAND VIEWS 提示會虛擬禁止直接在執行計畫中使用索引檢視表和索引,只有在 select 部分直接參考索引檢視表,且已指定 WITH (NOEXPAND) 或 WITH (NOEXPAND, INDEX( index_value [ ,...n ] ) ) 時,才能強制查詢最佳化程式使用索引檢視表。當您很確定透果索引檢視可大幅提高效能且執行計畫又不選擇索引檢視時,那麼透過 noexpand 提示大部分會得到比較理想效能,要注意的是該提示只針對企業版才有效,因為企業版才有支援索引檢視。
範例參考 - 資料表提示 (Transact-SQL)
4. RECOMPILE
強制查詢最佳化程式在下次執行相同的查詢時,重新編譯查詢計畫。在未指定 RECOMPILE 的情況下,Database Engine 會快取執行計畫並重複使用它們,當不必編譯整個預存程序,只需要重新編譯預存程序內的部分查詢時,RECOMPILE 是非常有用的替代方案,同時也可以有效避免參數探測問題。
5. OPTIMIZE FOR
告知查詢最佳化程式在查詢進行編譯和最佳化時,使用特定的本機變數值。 只有在查詢最佳化期間,才使用這個值,在查詢執行期間,不使用這個值,這樣做的好處是可以避免參數探測問題。
範例參考 - [SQL SERVER][Performance]善用 OPTIMIZE FOR 查詢提示
6. OPTIMIZE FOR UNKNOWN
告知查詢最佳化程式在編譯及最佳化查詢時,將統計值 (而非初始值) 用於所有的區域變數(包含以強制參數化所建立的參數)。
範例參考 - 查詢提示 (Transact-SQL) / 將查詢提示附加至計畫指南
7. PARAMETERIZATION { SIMPLE | FORCED }
指定 SQL Server 查詢最佳化程式在查詢完成時套用在查詢的參數化規則。一般來說無需特別使用強制參數化,但不得否認在某些情況下,強制參數化確實會產生比較理想效能。
範例參考 - 淺談執行計畫快取和重用
8. MAXDOP
控制執行計畫中用於執行查詢的處理器 (CPU) 數量。一般 OLTP 環境來說,如果查詢使用平行執行計畫可能都是因為遺漏索引或是不當平行處理造成高 CPU 情況,這時可以透過該提示來控制處理器使用數量等於 1 (該提示會覆寫 sp_configure 和 max degree of parallelism 組態值) 或許是最快最有效的改善方法。
範例參考 - CPU Bottleneck
9. PLAN GUIDE
透過計畫指南可以將特定提示或執行計畫附加至現有查詢。當你有使用第三方軟體且無法改寫查詢效能不佳的 TSQL (有些軟體可能會把相關資料庫語法編譯成一顆 DLL),這時您會感謝 SQL Server 團隊設想週到,在這樣狀況下透過計畫指南來改善效能可能是唯一又最快的方法。SQL Server 計畫指南有 object、sql、template 三種類型,可依照自己需求自行選用,下面會示範透過透過 sp_create_plan_guide 來建立常見的 object 和 sql 計畫指南,以及使用 sp_control_plan_guide 移除、停用或啟用計畫指南。
範例參考 - 計畫指南
10. USE PLAN
強制查詢最佳化程式套用所指定的執行計畫 (xml 格式)。該提示大部分可以強制聯結順序、排序和索引 (掃描或搜尋) 運算子,比較可惜的是無法支援分散式查詢。當您發現有執行計畫優於現在查詢最佳化程式版本所產生執行計畫 (例如不同系統環境或是前一版 SQL Server 執行計畫較好),而且您又不想改寫原本 TSQL 查詢語法時,這時產生較好執行計畫 (xml 格式),並套用較佳品質執行計畫可能會是最快的改善方法。
範例參考 - 使用 USE PLAN 查詢提示
聯結提示
1. LOOP 、 HASH 、MERGE
強制指定查詢中的聯結應該使用迴圈、雜湊或合併。 但無法同時使用 RIGHT 或 FULL,將 LOOP 指定為聯結類型。使用該提示必須要很小心,因為聯結組合變化太多,而要找到一個最佳組合也是查詢優化程式一直在改善的部分,如要使用該提示大部分會透過觀察輸入資料量來決定自己的聯結方法。
範例
select t1.name,t1.CatalogDescription,t2.name as 'ProductName',t4.ModifiedDate
from Production.ProductModel t1
left join Production.Product t2
on t1.ProductModelID=t2.ProductModelID
left join Production.ProductModelIllustration t3
on t1.ProductModelID=t3.ProductModelID
left join Production.Illustration t4
on t3.IllustrationID=t4.IllustrationID
where t1.name like '%o%'
order by t2.name
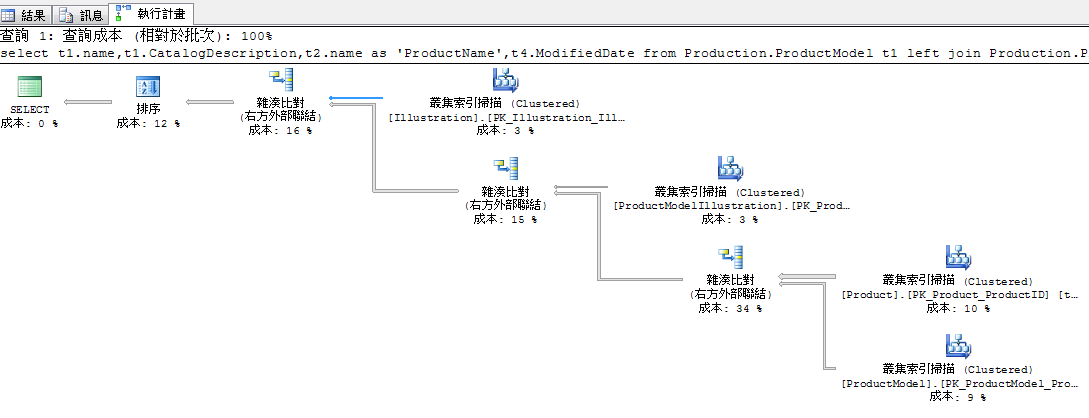
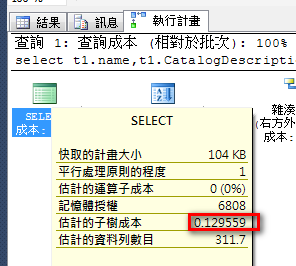
預設使用 hash join,整體成本 0.129559

查詢時間 154 ms
一般看到 hash join 可能是因為沒有正確索引或龐大資料量所導致,而且 hash join 是比較適合無排序定義查詢 (輸入資料量大),但以這案例來說資料需要排序,所以或許透過 merge join (適合輸入資料量大、排序且有叢集索引或涵蓋索引) 可能會產生比較理想效能,下面我們嘗試使用 merge join 改善效能。
Note:Loop join 適用資料量小且輸入資料表都要有正確索引的查詢。
select t1.name,t1.CatalogDescription,t2.name as 'ProductName',t4.ModifiedDate
from Production.ProductModel t1
left join Production.Product t2
on t1.ProductModelID=t2.ProductModelID
left join Production.ProductModelIllustration t3
on t1.ProductModelID=t3.ProductModelID
left join Production.Illustration t4
on t3.IllustrationID=t4.IllustrationID
where t1.name like '%o%'
order by t2.name
option(merge join, recompile)
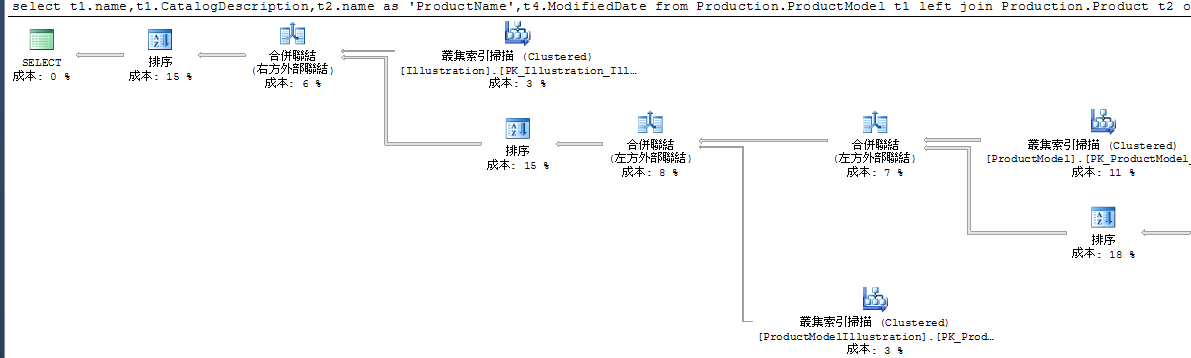
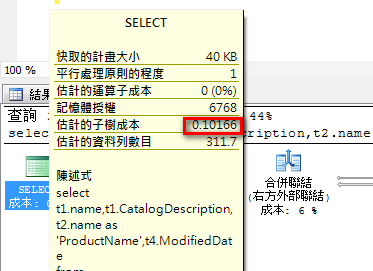
整體執行計畫成本降低為 0.10166

查詢時間 113 ms
進階推薦
若您有興趣進階學習,可參考 MVP James Fu 錄製的資料庫例行管理系列教學之索引維護篇,除了教學影片,亦提供了簡報檔下載,都是完全免費的,歡迎多多運用。

希望以上內容對您的學習有所幫助。