如何寫出高效能 TSQL - 探索統計值
本文將分成四大單元,分別帶您了解:
前言
統計值和撰寫 TSQL 兩者關係非淺,由於統計值直接影響執行計畫品質,所以我們寫的查詢需要能有效使用統計值,但由於統計值艱深複雜,所以我們將用案例問題方式來介紹統計值,一來看得比較有感覺,二來內容也比較淺顯易懂,希望透過本文能讓您了解統計值在資料庫中的重要地位。
統計值概念
統計值是什麼?
統計值是描述索引鍵值分布訊息,SQL Server 可以針對索引或是資料表某欄位來建立,而查詢最佳化程式透過統計值資訊才知道要使用那些運算子較為合理,同時也會估計基數並建立最佳執行計畫,例如透過所估計基數選擇索引搜尋運算子,而非需要大量資源的索引掃描運算子。
資料表上的統計值和索引上一樣嗎?
基本上都是一樣的,不一樣的地方在於手動或是自動建立,手動建立可以強制 full scan,但自動建立只進行資料採樣,採樣率越高執行計畫品質越好,但相對花費時間越久,如果資料表資料龐大,那建立或更新統計值將會影響查詢時間,所以 SQL Server 預設不會執行 100% (full scan) 採樣建立統計值,而實務上通常會依照使用者異動程度和 AP 特性來建立自動排程工作 (半年或一年) 更新統計值,下面我們透過 DBCC show_statistics 讓您更清楚手動和自動建立統計值差異。
Note:建議開啟資料庫自動建立和更新統計值選項。

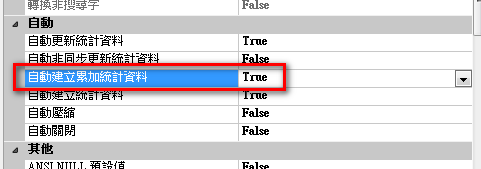
SQL 2014 建議多開啟自動建立累加統計資料。
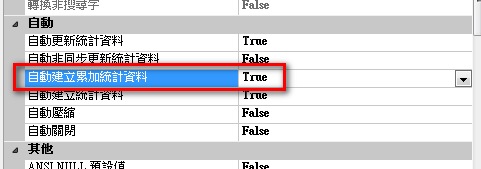
1. 自動建立統計值
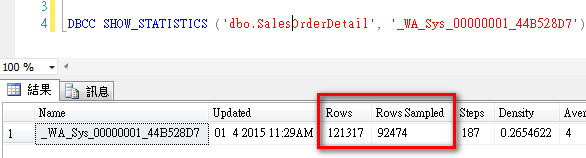
可以看到該資料表總筆數 (rows) 121,317,但該統計值只採樣 (rows sampled) 92,474。
2.手動建立統計值
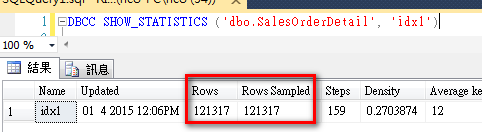
完整採樣 (full scan)。
閱讀統計資料
DBCC show_statistics 會顯示標頭、密度和長條圖,透過 DBCC show_statistics 我們可以馬上掌握統計值是否過期、資料分布情況和索引鍵是否合適,下面會介紹一些常用欄位,如您要了解所有欄位意義可參考 DBCC SHOW_STATISTICS (Transact-SQL)
1.標頭

這裡主要看以下欄位:
Updated - 顯示上次更新統計值時間,該欄位可以來判斷統計值是否需要手動更新。
Rows 和 Rows Sampled - 一般會比對這兩個欄位筆數是否差距太大,通常會抓資料採樣不可低於 資料表總筆數 * 70%。
2.密度

統計值透過密度比率來判斷索引欄位選擇性高低,一般來說低密度索引欄位表示高選擇性 (密度越低越適合 nonclustered index key),高選擇性可以幫助查詢優化程式在大資料量中快速搜尋小結果集。
All Density - 查詢最佳化程式會利用該欄位值來估算基數。
Average Length - 透過該欄位可用來判斷索引鍵資料型別是否合適,建立正確資料型別和選擇正確索引鍵才能有效發揮索引效益。
3.長條圖

(資料採樣上限為 200,該值對一些大資料表來說其實不太足夠)
RANGE_HI_KEY - 長條圖步驟的上限資料行值。 此資料行值也稱為索引鍵值。
RANGE_ROWS - 資料行值在長條圖步驟內的預估資料列數,不包括上限。
EQ_ROWS - 資料行值等於長條圖步驟之上限的預估資料列數。
DISTINCT_RANGE_ROWS - 在長條圖步驟內具有相異資料行值的預估資料列數,不包括上限。
AVG_RANGE_ROWS - 在長條圖步驟內具有重複資料行值的平均資料列數,上限不包括在內 (RANGE_ROWS / DISTINCT_RANGE_ROWS for DISTINCT_RANGE_ROWS > 0)。
透過長條圖可以得知資料分布情況,一般會使用密度並搭配資料分布長條圖來確認索引有效性,同時透過 range_rows 和 avg_range_rows 欄位推估基數是否夠準確,下面將示範一個因為統計值常見效能問題並透過統計值來改善效能。
drop table t1
create table t1
(
c1 int,c2 char(100) default('test')
)
set nocount on
insert into t1(c1) select 50
go 100000
insert into t1(c1) select 100
create index idx1 on t1(c1)
select * from t1 where c1=100
select * from t1 where c1=50
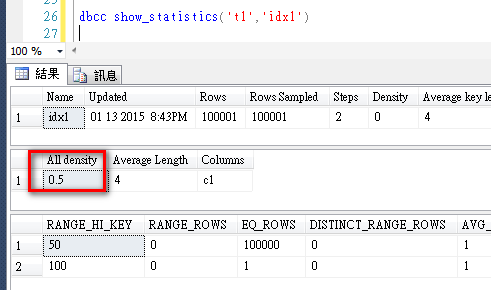
密度 0.5
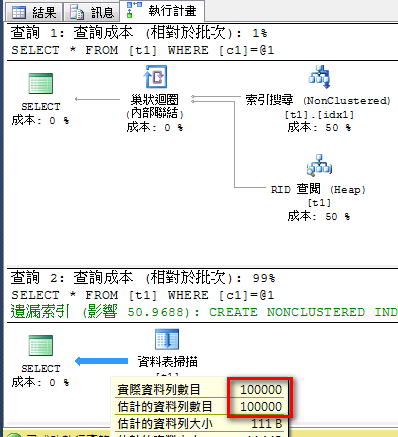
查詢 1 因為建立了索引,且 100的 資料只有一筆,該筆數和 avg_range_rows 相同,所以查詢優化程式可以準確估計基數 (實際筆數 = 估計筆數)。
查詢 2 雖然建立了索引,但 50 的資料筆數幾乎快等於整個資料表,所以查詢優化程式選擇資料表掃描運算子處理較佳,而非索引搜尋運算子。
接下來我們新增一筆資料,並執行不同條件查詢再來看看執行計畫是否有變化
insert into t1(c1,c2) select 100,'test'
select * from t1 where c2='test'
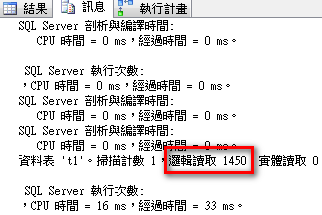
查詢一筆資料卻使用資料表掃描運算子,主要是因為該欄位 (c2) 沒有建立索引所造成,但由於資料庫有開啟自動建立統計值選項,該選項可讓查詢優化程式估計基數。
SQL Server 自動建立統計值。
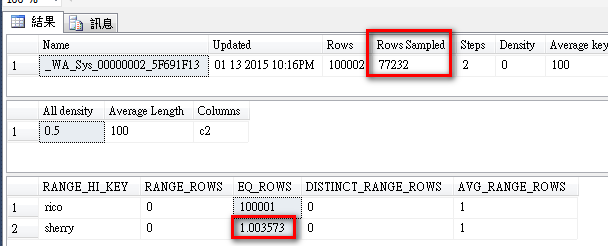
自動建立統計值預設不會進行 100% 資料採樣。
我們繼續新增資料,並執行不同條件查詢再來看看執行計畫是否有變化
insert into t1(c1,c2) select 100,'test'
go 10
select * from t1 where c1=100 and c2='test'
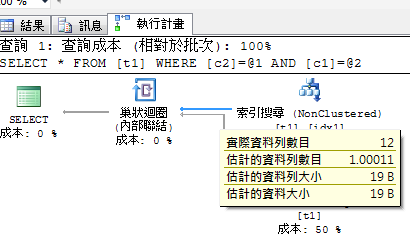
這時估計值和實際值已經相差10倍以上了,遇到這種情況我們大部分都會先往統計值方向處理,這裡我們手動建立統計值來改善基數。
create statistics s1 on t1(c1,c2)
with fullscan
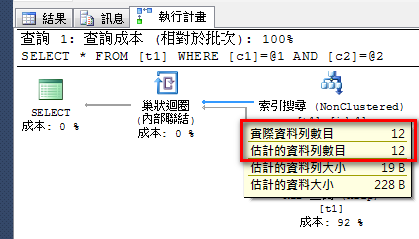
可以看到實際和估計資料列數目相同了。
統計值對效能影響
如何讓查詢有效使用統計資料
1. SQL 2014 以前請盡量使用暫存資料表而非資料表值參數來處理中繼資料,這兩者最大差異就是查詢最佳化程式不會針對資料表值參數建立統計值,但如果在 SP 中使用暫存資料表又會提高SP重新編譯次數,所以還是要根據特性選用。雖然 SQL 2014 資料表值參數可以建立索引來提高效能,但實際測試過查詢優化程式還是不會建立統計值,但如您使用 SQL 2014 的話,我還是建議使用資料表值參 數(取代暫存資料表) 並建立索引對效能會比較好,而且也可以降低 tempdb I/O 資源競爭。
2. 查詢符合 SARG
要讓查詢最佳化程式透過索引快速找到資料,那麼 where 子句最好符合 SARG 格式,且欄位請依照選擇性高低排序 (由高到低)。
3. 避免區域變數
如果查詢使用區域變數將造成查詢最佳化程式無法得知區域變數值,導致執行計畫品質變差,最好將區域變數改成參數,否則請額外加上 recompile 來取得較佳執行計畫。
declare @c1 int
set @c1 = 100
select * from t1
where c1 = @c1
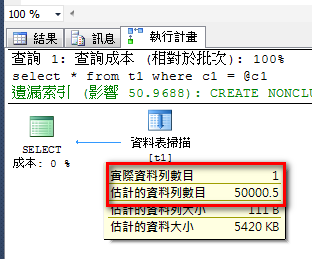
實際資料只有 1 筆,但估計的資料列數目卻高達 50000.5,導致查詢優化程式誤選資料表掃描運算子,所以該執行計畫品質相當差,也讓索引無法發揮效益。
50000.5 是怎麼來的呢?前面有提到查詢優化程式會利用 All Density 欄位來估算基數,由於 SQL 2014 新基數演算法相當複雜,隨者欄位數量、順序和資料內容不同所得運算式也會有所不同,以這案例可以簡單得到下面運算式:
基數估計 = 資料表總筆數 * 密度
50000.5 = 100001 * 0.5
解決方法
*加上 recompile
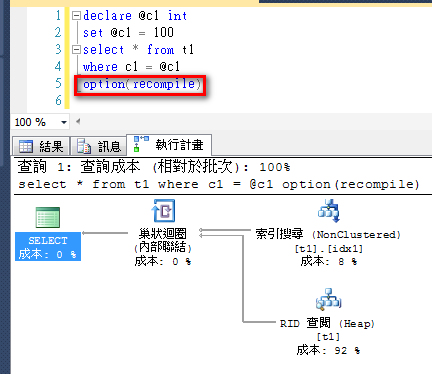
加上 recompile 就失去快取優點。
*改成參數
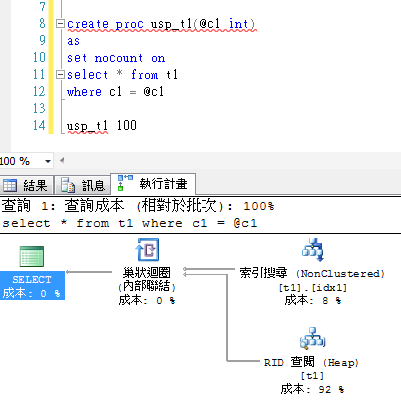
SP 要注意參數探測效能問題。
統計值何時建立、更新
查詢最佳化程式自動建立統計值觸發點有建立索引以及查詢期間針對述詞中單一資料行 (資料庫需開啟 AUTO_CREATE_STATISTICS)。一般來說這兩個時機點可以確保建立較好執行計畫,但有以下情況發生時,透過手動建立統計值將可以改善效能
1. 查詢述詞多個資料行
2. 針對資料子集的查詢
3. 統計值遺失
當查詢期間,查詢最佳化程式也會自動判斷統計值是否過期 (資料庫需開啟 AUTO_UPDATE_STATISTICS),如果過期將自動更新並重新編譯執行計畫,但也不建議頻繁手動更新統計值,但有以下情況發生時,手動更新統計值將可以改善效能。
1. 維護作業之後
2. 查詢時間很慢
檢視表上可否建立統計值
一般檢視表不可以建立統計值,但索引檢視例外,基本上透過索引檢視可以大幅提高查詢校能,這裡不詳細討論索引檢視如何提高效能,您可以參考本系列的前一篇文章「如何寫出高效能 TSQL - 關於索引不可不知道的事」。
暫存資料表可否建立統計值
可以。這個特性是暫存資料表和資料表值參數最大差異,當資料量大時,一般使用暫存資料表查詢校能會優於資料表值參數,但在 SQL 2014 因為資料表值參數已經可以建立索引,如您是使用 SQL 2014 以後版本,還是建議使用資料表值參數取代暫存資料表。
使用分散式查詢可否建立統計值
一般只要使用分散式查詢 (使用連結伺服器) 就無法取得較佳執行計畫,主要是無法取得分散式統計值所造成,在實務上為了想要取得較佳執行計畫,大多還是會把遠端資料載入到本地 SQL Server 伺服器後建立索引來處理,但如果您覺得這樣太麻煩的話,也可以透過提高使用者連結伺服器權限 (都為 SQL Server 才可行),如系統管理員 (sysadmin)、 db_owner 或 db_ddladmin 角色成員,這時才可以取得所有可用的統計資料,但現實世界中,遠端資料庫管理者不太可能給予如此高的權限 (除非兩個資料庫管理者都是同一人),所以提高權限這方法可說相當不實用,另一方法則是加上 top(n) 讓查詢優化程式有所依據來估計較準確基數,該案例可參考[SQL SERVER]提高分散式查詢效能。
篩選統計值
SQL 2008 所推出的新功能,由於長條圖先天性有 200 上限,這對一些大資料表來說是不夠的 (所以基數估計就越不準確),現在您可以透過篩選統計值來改善基數估計準確度。
SQL 2014 新基數演算法
SQL Server 會根據資料庫中的統計值去計算每次查詢應該會有多少資料,這一個處理動作就稱為基數 (cardinality estimation CE) 估計,查詢最佳化程式會基於這個計算來選擇合適的運算子,並判斷相關資源成本,最後返回一個合適的執行計畫。以前版本的基數估計有 2 個重大缺點,一是大資料表自動更新統計值的門檻太高,二是重建統計值需要重新掃描整個資料表過於耗時,所以 SQL 2014 新基數演算法針對這 2 點作出了重大改善,如此一來更可讓開發人員專心於商業邏輯處理上,並減少效能調校時間。
Note:自動累加統計值須開啟自動建立累加統計資料選項
進階推薦
若您有興趣進階學習,可參考許致學老師的「開啟效能魔力窗 TSQL 視窗函數的實務技巧」,除了教學影片,亦提供了簡報檔下載,都是完全免費的,歡迎多多運用。

希望以上內容對您的學習有所幫助。