如何寫出高效能 TSQL - 關於索引不可不知道的事
本文將分成四大單元,分別帶您了解:
簡介
TSQL 是查詢 SQL Server 的核心,而索引則是提高查詢效能的主角,如要寫出高效能 TSQL 則無可避免需搭配正確索引,因為 SQL Server 需透過正確索引才可以快速有效地找到與索引鍵值相關資料,有了正確索引 SQL Server 就不需要掃描資料頁 (data page) 上每一筆資料,而在眾多查詢效能調校技術中,透過建立並設計正確索引算是最基本的手法 (通常來說也是最有效、最快能看到效果的),所以了解索引觀念和特性,可以幫助我們在開發階段設計規劃正確索引,而且我們認為不管是開發人員或 DBA 都應該了解索引該如何設計,因為都有可能接收使用者最直接的感受,說白話一點,每一句查詢 TSQL 都要以最短時間回應給使用者。但由於索引主題範圍龐大,所以一開始我們會介紹索引基本知識、B-tree 結構等,後面介紹索引類型、案例分享及設計須注意的方向,主要是希望透過本文可以讓大家快速建立正確索引。
索引基本知識
SQL Server 如何使用索引
我們都知道索引可以提高查詢效能,但相對也增加新增 (Insert)、刪除 (Delete) 和更新 (Update) 資料處理成本,所以對整體效能來說找一個合適平衡點相當重要。
當一個資料表沒有索引時,資料存放的順序絕不是依照資料新增順序,這是因為 SQL Server Database Engine 會自我處理資料儲存位置,所以基本上,我們無法事先預測資料儲存在資料頁上是否都連續且都在同一區段中,而當一句 Select 送給 SQL Server 時,因為沒有索引,這時 SQL Server 必須掃描整個資料表,以及該資料表的所有資料頁和資料頁上的每一筆資料,最後才返回使用者最終所需要的資料結果集,這樣的操作就稱為資料表掃描 (Full Table Scan)。
當資料表上有索引時 (假設索引設計正確),這時資料表上的資料一定會經過排序,所以 SQL Server 將基於該索引鍵值和結構來定位 (透過指標) 資料位置,簡單來說只搜尋必要的資料頁,而這些資料頁已經包含使用者最終所需要的資料結果集,這樣的操作就稱為索引搜尋 (Index Seek)。
B-tree 索引結構
SQL Server 所有索引基本上都採用 B-tree 結構,除了 xml 索引、全文檢索索引 (full-text)、資料行存放區索引 (columnstore index) 和記憶體最佳化索引 (Memory-optimized indexes) 不用B-tree。xml 索引是存放在 SQL Server 底層資料表,全文檢索索引是利用自己引擎來處理查詢和管理全文檢索目錄 (full-text catalogs),資料行存放區索引則是使用 in-memory 技術,記憶體最佳化索引則是使用 BW-tree 結構。
一個標準的 B-tree結構 (圖1) 是由根結點 (root) 開始的頁面,下面有一或多個中繼層節點及一或多個分葉 (Leaf) 節點構成。
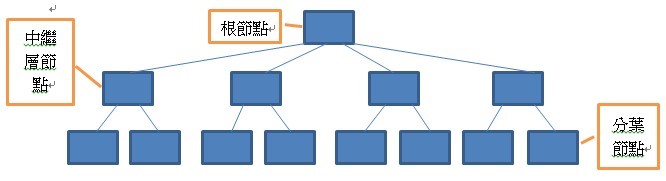
圖 1 B-tree結構。
一個 B-tree結 構一定是平衡的,這代表每一層左右頁面數量一定相等,最末的分葉頁面包含了排序後的索引資料,每頁索引資料列數量視索引所含資料行的儲存空間而定。
根節點及中繼層節點包含其下層節點的第一項資料,即表示指向下層資料儲存位置的指標 (圖2),SQL Server 執行查詢時會先掃描每一個根節點所在頁面,搜尋是否含有查詢的值,找到後再以指標指向下一層繼續搜尋,如此不斷反覆處理,直到在最末層的分葉節點中找到資料為止。
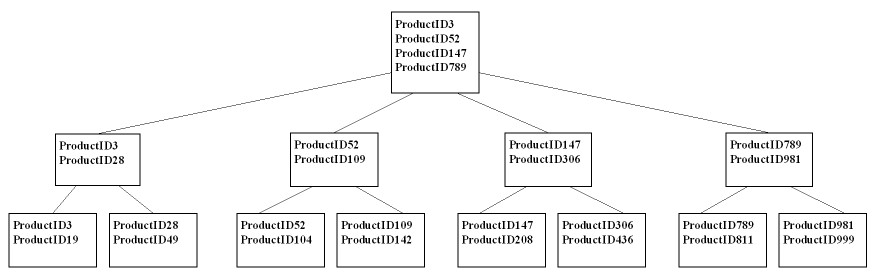
圖 2 索引頁面中的根、中繼層和分葉節點。
假設今天我們要在圖 2 中搜尋 ProductID199,查詢會從根節點開始搜尋,因為 ProductID199 介於 147~789 之間,所以 SQL Server 會從 ProductID147 開始搜尋並計算 Product199 可能位置,指向下層 (中繼層) 由 ProductID147 開始搜尋至 ProductID306 節點後,再指向下層 (分葉層) 搜尋 ProductID199 所在位置 (147~208),由於此時已在最末層,故可以在該層找到資料,且 SQL Server 也不需要去搜尋其他節點或頁面找 ProductID199。如果 ProductID199 不在資料表中,查詢就會回傳找不到的結果,而 B-tree 的平衡效果,使得 SQL Server 每次在索引內搜尋資料動作時都只會在相同數量的各層索引頁內處理,以利精準地找到所需資料。
更優 的 Bw (Buzz Word) - tree
Bw-tree 為記憶體最佳化索引和資料表帶來重大改善,簡單來說 Bw-tree 結構可以更省儲存空間(記憶體)、更有效利用多核心且針對範圍 (range) 和指標 (point) 搜尋有很高效率。
Bw-tree 結構 (圖3) 和 B-tree 類似,所有分葉節點依然還是資料頁 (data page),其他 index node 只存放 key (有順序) 和下一頁指標,且每頁都透過一個邏輯指標 (PID) 串聯一起,透過該 PID 對應 Mapping Table 即可找到資料存放的物理位置。
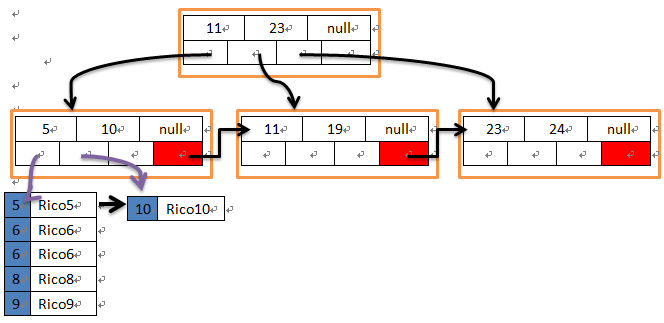
圖 3 Bw-tree 結構。
頁面分割
SQL Server 每頁可儲存 8060 bytes 資料 (大小為8092 bytes),如果以 INT 類型的資料行建立索引,資料表每一列資料就需要 4 bytes 的索引儲存空間,假設資料表有 2016 筆資料 (需 8064 bytes 儲存空間),因為索引詞條已無法容納於一頁內,則必須進行頁面分割,所以會加入兩個新索引頁面,在現有的根節點頁面下移成為分葉層頁面,並將原索引頁面的一半資料,移至新產生的分葉層頁面上,而在上層的頁面則成為新的根節點頁面,最後則是將每一個分葉層頁面的詞條寫入至新的根節點頁面。所以總共使用三個索引頁面,一個根節點頁面和兩個分葉層頁面 (這時不需要中繼層頁面,因為根節點頁面可包含全部分葉層頁面的詞條),所以在搜尋資料時,最多會在兩個頁面執行,但如果頁面分割發生頻率過高將嚴重影響效能,所以設計索引上一定要考慮減少頁面分割發生頻率。
Note: 頁面分割不僅影響效能,同時也會影響交易紀錄檔案大小,該案例可參考[SQL SERVER][Memo]頁面分割影響交易記錄檔大小。
索引類型介紹
叢集索引
資料表存在叢集索引,那麼資料就會依照叢集索引鍵值順序存放,該索引分葉層包含資料頁 (data page),所以當透過叢集索引搜尋資料即會返回資料真實存放位置,這樣的特性即表示一個資料表只能有一個叢集索引,雖然並非每個資料表都一定要有叢集索引,但如有符合以下條件時,建議最好建立:
1. 大資料表且沒有任何非叢集索引 (nonclustered indexes)
當你要查詢相關資料時,如果沒有叢集索引,那麼就會進行資料表掃描,將從資料表第一筆掃描到最後一筆資料才能返回相關所需資料。
2. 針對某些欄位常使用範圍搜尋
有了叢集索引就可以避免整個資料表的物理資料排序處理,因為資料已經預先依照叢集索引鍵值排序過了。
3. 針對某些欄位常使用 group by
資料要 group by 需先經過排序處理,而叢集索引將可省下排序處理。
4. 針對某些欄位常使用排序
因為叢集索引已經排序了相關資料,所以查詢一開始就可以避免排序處理。
建立叢集索引鍵值前需決定叢集索引鍵值 (相當重要的事),因為資料存放順序會依照所選擇欄位來排序(降或升冪),雖然選擇叢集索引鍵值沒有一定的標準,但大致上還是方向可循,下面是我自己用來選擇叢集索引鍵值準則:
1. 排序、群組
2. 唯一性
3. 不可 null
4. 避免寬索引
5. 資料異動少
6. 考慮 insert 資料排序 (最小碎片)
Note:當你定義資料表 PK (Primary key) 時,SQL Server 預設會自動建立叢集索引。
非叢集索引
非叢集索引不排序或存放任何資料,索引頁 (index page) 上所有分葉節點只存放指標,如果資料表已存在叢集索引,那麼該指標將會指向叢集索引,如不存在將指向資料真實存放位置,所以建立叢集和非叢集索引順序相當重要。
綜合索引
該索引可以有兩個以上欄位,欄位順序請依照選擇性高低擺放 (選擇性高越前面),如果查詢有需要多欄位時即可建立提高效能。
範例:
select FirstName,LastName
from Person.Person
where FirstName like 'r%' and LastName like '%z'
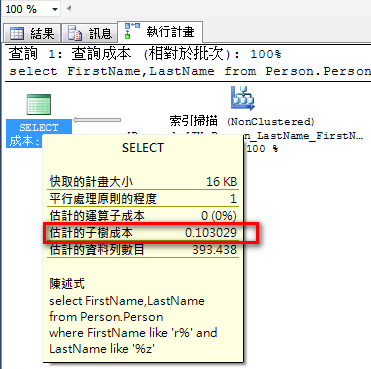
使用索引掃描、執行計畫成本:0.103029。
依照該 TSQL 建立複合索引:
create index idx1 on Person.Person(FirstName,LastName)
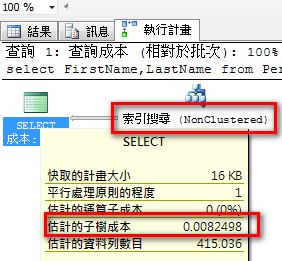
改用索引搜尋,執行計畫成本降低為 0.0082498
Note:密度和選擇性可參考 [SQL SERVER][Performance]密度和選擇性 一文。
單一索引
該索引只有一個欄位,針對單一欄位搜尋資料很有用。
範例:
create index idx2 on Person.Person(FirstName)
涵蓋索引
涵蓋索引算是使用率最高的索引類型,建立索引時透過 include 子句來擴充非索引鍵欄位,SQL Server 會將非索引鍵欄位存放在索引上的分葉階層 (不會每一筆索引列都存在),該層級幾乎可說是索引葉上的最末層,且 include 只支援非叢集索引類型,涵蓋欄位有以下特性:
1. 索引鍵不受限 900 byte 限制,因為不會存放在 root 或中繼層。
2. 可包含計算資料行,但數值必須有一定性。
3. 不能涵蓋 text、ntext 和 image 資料類型。
4. 不能涵蓋索引鍵值。
範例:
select FirstName,LastName,Title,PersonType
from Person.Person
where MiddleName='A' and EmailPromotion>=1
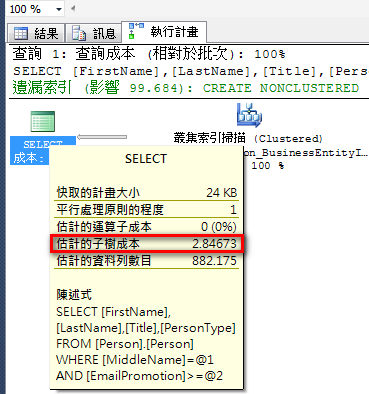
使用叢集索引掃描、執行計畫成本:2.84673。
建立涵蓋索引
create index idx3 on Person.Person(MiddleName,EmailPromotion)
include(FirstName,LastName,Title,PersonType)
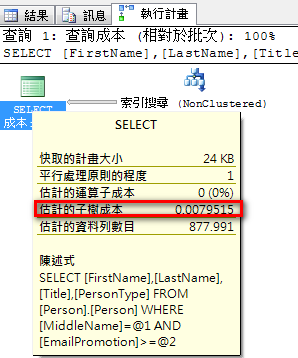
改用索引搜尋、執行計畫成本:0.0079515。
唯一索引
該索引可以強制索引鍵欄位具有唯一性,當你定義唯一約束預設會建立唯一非叢集索引,或資料表沒有叢集索引且定義 PK 預設也會會建立唯一叢集索引,該索引一般來說會大幅提高效能 (可以產生很有效的執行計畫),如果你確定相關欄位具有唯一值,且查詢也需要這些欄位,那麼建立唯一索引絕對不會錯,唯一索引特性如下
1. 可以使用單一或多個欄位
2. 可以為叢集或非叢集 (包含 include)
3. 索引建立 (或重建) 期間,會確認索引鍵欄位是否有重複值
4. 資料新增或更新期間,會確認索引鍵欄位是否有重複值
篩選索引
篩選索引是最佳化的非叢集索引,但索引彈性相對低,所以實務上實用性較低的,但針對已知且固定的資料子集,建立篩選索引確實可以大大提高查詢效能並減少索引使用空間,案例參考 [SQL SERVER][Memo]篩選索引一文。
分割索引
建立分割資料表並在該資料表上建立索引 (建議包含 (include) 分割資料行),SQL Server 預設會使用相同的分割結構 (partition scheme) 和分割資料行 (partition column) 自動對索引進行分割,主要是希望索引和資料表對齊 (aligned),索引和資料表對齊對效能來說相當重要,分割索引不只可以提高詢效能,也可減少索引管理成本,因為你可以針對某區索引碎片執行重建操作,進而減少某種程度的SQL Server停機時間。
資料行存放區索引
SQL 2012 新增的資料行存放區索引主要是提高 OLAP 效能,儲存方式不像以往採取 row,而是改成 column 方式儲存,這會大大提高緩衝命中率並減少 I/O,同時對於完整掃描作業可以帶來極大效能效益,但建立該索引後,資料表會變成唯獨,這個限制導致不太適用在 OLTP 環境中,但開心的事在 SQL 2014 移除了這項限制,這改善真是大快人心。
範例:SQL 2014 資料行存放區索引資料更新測試
create table mycolumnstore
(
c1 int identity(1,1),
c2 varchar(30),
c3 date
)
--建立columnstore index
create clustered columnstore index cidx_cs
on mycolumnstore
新增操作
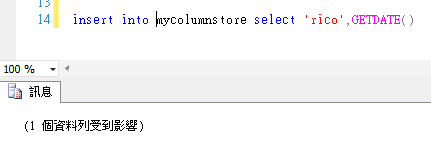
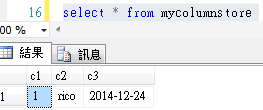
更新操作
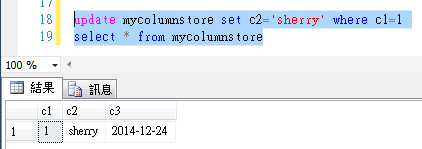
刪除操作
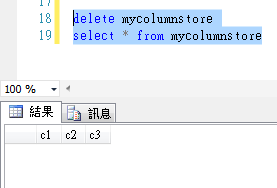
記憶體最佳化索引
SQL 2014 記憶體最佳化索引使用 Bw-tree 結構,所有邏輯指標都存在記憶體中,總共有兩種非叢集索引類型。
1. 非叢集哈希 (hash)索引:
該索引適用指標查閱,大小固定且沒有任何頁面(page),查詢返回的值都是沒有排序。
2. 非叢集非哈希 (hash) 索引:
該索引適用範圍或排序掃描,也適用任何符合 SARG 查詢參數,查詢返回的值都會排序。
範例:
--建立記憶體最佳化資料表
CREATE TABLE [TransactionHistoryArchive] (
[TransactionID] [int] NOT NULL
CONSTRAINT PK_TransactionHistoryArchive primary key NONCLUSTERED HASH WITH (BUCKET_COUNT = 100000),
[ProductID] [int] NOT NULL,
[ReferenceOrderID] [int] NOT NULL,
[ReferenceOrderLineID] [int] NOT NULL,
[TransactionDate] [datetime] NOT NULL,
[TransactionType] [nchar](1) NOT NULL,
[Quantity] [int] NOT NULL,
[ActualCost] [money] NOT NULL,
[ModifiedDate] [datetime] NOT NULL index idx1,
index idx2(TransactionID),
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
--新增資料:記憶體資料表的交易無法跨資料庫
SELECT * INTO mytemp
FROM AdventureWorks2012.Production.TransactionHistoryArchive
INSERT INTO TransactionHistoryArchive
SELECT * FROM mytemp
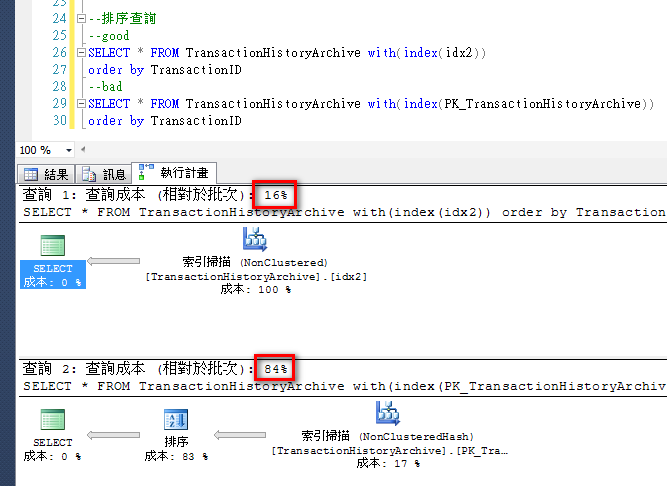
--排序查詢
--good
SELECT * FROM TransactionHistoryArchive with(index(idx2))
order by TransactionID
--bad
SELECT * FROM TransactionHistoryArchive with(index(PK_TransactionHistoryArchive))
order by TransactionID
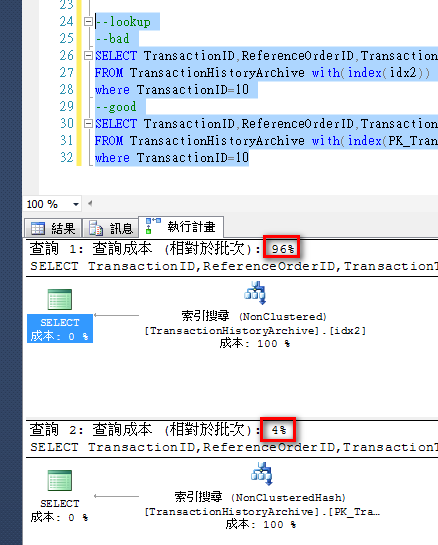
--lookup
--bad
SELECT TransactionID,ReferenceOrderID,TransactionType,ActualCost
FROM TransactionHistoryArchive with(index(idx2))
where TransactionID=10
--good
SELECT TransactionID,ReferenceOrderID,TransactionType,ActualCost
FROM TransactionHistoryArchive with(index(PK_TransactionHistoryArchive))
where TransactionID=10
索引設計注意事項
索引設計基本上需對應資料存取 TSQL 才能到位,這裡提出一些索引設計須注意相關事項讓大家參考:
1. 先建立非叢集索引後建立叢集索引
前面索引類型內容有提到,當一個資料表沒有叢集索引時,先建立非叢集索引的分葉層頁面指標將指向真實資料位置,如叢集索引已經存在時將指向叢集索引,先建立非叢集索引可以避免當你重建叢集索引時,連帶影響非叢集索引一起重建 (須注意索引兩次重建問題),這不僅拉長重建索引時間,也增加交易紀錄檔大小且浪費硬碟空間。
2. 使用索引壓縮
使用索引壓縮可以提高緩衝區命中率 (緩衝區可存放更多詞條) 並減少 I/O 和硬碟空間,建立索引時可以善加利用,但由於壓縮操作需要使用較多 CPU 資源,所以須注意 CPU 資源競爭情況。
索引壓縮測試:
--建立資料表
create table test1
(c1 int null,
c2 varchar(10) null)
--新增資料
declare @i int
set @i=1
while @i<2016
begin
insert into test1 values(@i,null);
set @i=@i+1;
end
--建立非叢集索引不使用壓縮
create nonclustered index nidx_1 on test1
(c1)
--查看索引頁面數(page_count)和其他相關資訊,確認壓縮所帶來的優勢
SELECT o.name,
ips.index_id,
ips.partition_number,
ips.index_type_desc,
ips.record_count, ips.avg_record_size_in_bytes,
ips.min_record_size_in_bytes,
ips.max_record_size_in_bytes,
ips.page_count, ips.compressed_page_count
FROM sys.dm_db_index_physical_stats (DB_ID(N'AdventureWorks2012'), OBJECT_ID(N'AdventureWorks2012.dbo.test1'), NULL, NULL, 'DETAILED') ips
JOIN sys.objects o on o.object_id = ips.object_id
ORDER BY index_id asc,record_count DESC ;

頁面總數量 5,每筆資料平均大小 16 (bytes)
--建立非叢集索引並使用頁面壓縮
create nonclustered index nidx_2 on test1
(c1)
WITH ( DATA_COMPRESSION = PAGE ) ;
使用頁面壓縮可以看到每筆資料平均大小從 16 降低為 9.434,頁面數量從 5 降低為 3。
3. 設定填滿因子 (Fill Factor)
透過設定填滿因子可以微調索引效能和儲存空間,該因子會決定分葉層頁面填滿資料的空間百分比 (保留每個頁面可用空間),以利未來資料成長使用,主要目的是要減少頁面分割發生頻率,如設定 90 (預設 0) 表示只預留 10% 空間比例,實務上我建議該值依資料表讀寫特性設定比較有效益,因為設定過低將增加頁面分割頻率,也造成索引碎片過多增加 I/O,進而影響查詢效能且容易發生長時間 Lock 資源情形,但設定過高也會影響資料異動效能,所以建議必須依資料表讀寫特性設定取得一個平衡值,下面是填滿因子建議值:
a. 唯讀或靜態資料表: 設定 100%
b. 異動頻率很低的資料表: 設定 95%
c. 異動頻率一般的資料表: 設定 85%~90%
d. 異動頻率很高的資料表: 設定 50%-80%
4. 索引鍵欄位最好用於 join 操作
Join 多個資料表是常見的情況,當建立非叢集索引時最好第一優先考慮這些 join 欄位,或是設定 Foreign key 約束,這樣才能讓索引發揮效益並大大改善查詢效能。
5. 善用涵蓋索引
涵蓋索引 include 欄位不受 900 bytes 限制,且又可滿足查詢所需資料欄位,即不須額外浪費時間搜尋 data page,該索引效益永遠比單一欄位索引來的高,而且更有彈性。
案例可以參考 [SQL SERVER]提高動態查詢效能
6. 優先考慮選擇性高欄位
Distinct、where 、order by、group by 和 like 子句相關欄位最好選擇性高,高選擇性欄位可以讓索引更有效益,主要可以讓統計值估計更準確。
7. 適時重建索引
當在資料表中刪除一筆資料時,SQL Server 必須由索引頁中移除該筆資料的索引資料,而這就會導致在索引頁中留下空白,由於填補新值的成本太大,所以 SQL Server 也不會去填補該空白,若在資料表中更新一筆資料時,則 SQL Server 必須在索引頁中搜尋適當的位置並加入,而這也有可能會造成另一段空白。當索引頁已滿且必須進行分割時,就會產生更多的索引碎片,當碎片過多就會影響查詢的效能 (因為跨多個索引頁,所以增加 IO 讀取),所以當資料表資料異動頻繁時,時間一久,就會造成索引不斷破碎 (空白太多),這時候建立要執行重建索引操作。
索引碎片又分兩種類型,內部碎片和外部碎片。
外部碎片:
由於索引資料都是經過排序的,如果你的分葉層頁面 (index leaf page) 實體排序和查詢所要求的邏輯排序不相同時,就會導致 SQL Server 有額外的工作來返回正確的排序結果,但在大多數的查詢情況下,內部碎片並不會太大,但在設計索引上還是得注意排序的需求。
內部碎片:
一般來說索引頁都會預留一定的空間來存放新增 (insert) 的資料,因為這可以減少頁面分割發生的頻率,所以當你在建立或重建索引時,你可以指定填滿因數 (Fill Factor) 來決定一張索引頁面可存放多少百分比資料,如果索引頁面過於分散,將會拉長查詢時間 (跨多索引頁面,並增加額外的 IO 讀取),而且也會造成你的索引過於肥大 (浪費硬碟空間),請務必減少頁面分割發生的頻率,因為頁面分割這樣的動作相當耗費系統資源。
進階推薦
若您有興趣進階學習,可參考 MVP James Fu 錄製的資料庫例行管理系列教學之索引維護篇,除了教學影片,亦提供了簡報檔下載,都是完全免費的,歡迎多多運用。

希望以上內容對您的學習有所幫助。