SQL Server chez les clients – Un référentiel de données fiable et maitrisé avec MDS et DQS

La gestion des données de référence, ou Master Data Management (MDM) est une discipline permettant aux organisations de travailler sur un socle consolidé et fiable pour les informations référentes. SQL Server Master Data Services (MDS) est une plateforme de gestion des données de référence, qui peut être combinée avec Data Quality Services (DQS) , pour la gestion de la qualité de donnée.
Cet article est le troisième d’une série consacrée à l’EIM, et fait suite aux articles « Solution EIM pour Dynamics CRM » et « Une gestion flexible de la qualité des données avec DQS et SSIS ».
Dans ce billet, nous allons montrer comment injecter de la qualité dans un référentiel de donnée grâce à l’utilisation combinée des outils MDS et DQS.
Problématique
Avec l’explosion de la production des donnée et les besoins croissants d’analyse qui en découlent, les entreprises sont de plus en plus souvent confrontées aux problématiques suivantes :
- Garantir la cohérence des données au travers de l’ensemble du SI
- Permettre le croisement des données entre les différents Systèmesafin de répondre aux besoinsde Reporting
- Assurer une gestion de la qualité des données
- Définir des processus de gouvernance des données qui soit à la fois simples et efficaces
Bénéfices
- Centralisation : La rationalisation entraine une simplification et une baisse des coûts de gestion
- Unification : Les référentiels uniques permettent aux systèmes de consommer des références consolidées
- Alignement : Le rapprochement rend possible le croisement des données entre les systèmes
- Ajustement : Les données corrigées, formatées et enrichies répondent aux besoins métiers
- Partage : L’ensemble des Systèmes y accèdent de manière autonome et sécurisée
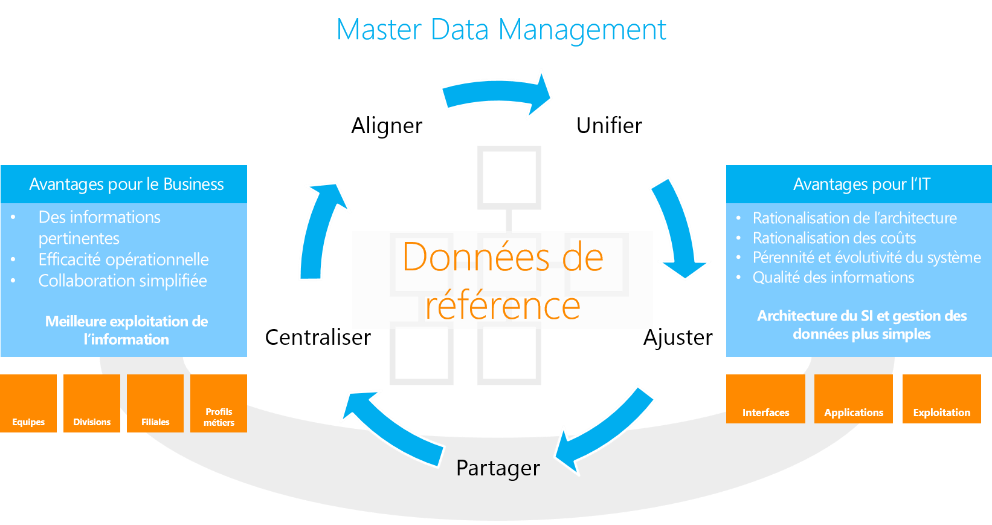
Master Data Services
Master Data Services, est spécifiquement conçu pour gérer les données de référence. Ses fonctionnalités principales sont reprises dans le schéma ci-dessous:
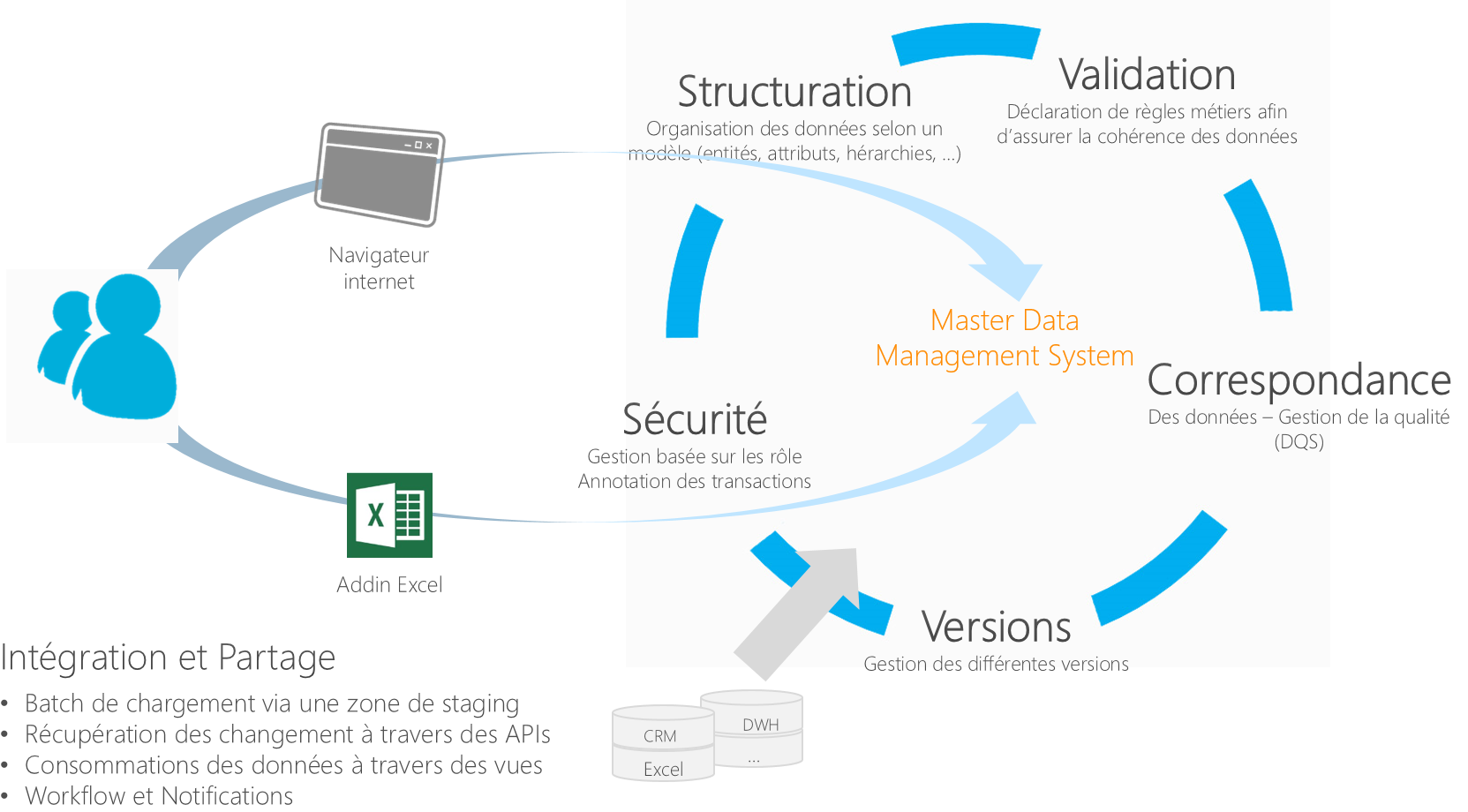
Correspondance et Gestion de la qualité :
Nous allons nous pencher sur cette brique de Master Data Services et voir en détail comment l’interfacer avec DQS pour répondre aux problématiques de gestion de la qualité dans un référentiel de donnée.
Cette interface entre les deux produits va être réalisée par le biais de SSIS (SQL Server Integration Services), afin de s'appuyer sur l'ensemble des briques EIM intégrés dans SQL Server (MDS/DQS/SSIS).
Intégrer des données de qualité dans un référentiel MDS via SSIS
MDS et DQS s’interfacent par le bais de SSIS pour construire une solution d’alimentation automatisée, avec contrôle de qualité dans un référentiel MDS.
La première étape consiste à créer un package SSIS, qui va assurer l’automatisation du nettoyage et de la correspondance des données lors de l’alimentation du référentiel.
Pour ce faire nous allons créer un projet SSIS, puis y ajouter une étape de type « DataFlow » dans lequel les opérations d’extraction, de nettoyage et de chargement vont être effectuées.
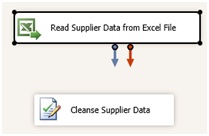
Dans notre exemple nous allons ajouter une source de données de type Excel au DataFlow, puis faire pointer cette source de donnée vers le fichier de donnée fournisseur (Nous aurions pu choisir parmi les nombreuses sources de données disponible dans SSIS).
Nous allons également ajouter une transformation de type DQS Cleansing. Cette transformation permet de confronter des données aux règles d’une base de connaissances DQS (A configurer en amont).
Configurer la tâche DQS pour qu’elle pointe vers votre instance DQS et utilise la base de connaissances souhaitée (Suppliers dans notre cas).

Dans l’onglet "Mapping", il suffit de sélectionner les colonnes du flux que nous souhaitons analyser et de les mapper avec les domaines correspondants de la base de connaissances DQS.

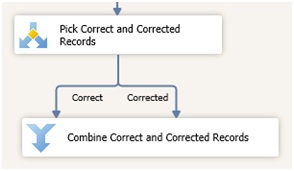
Il faut ensuite séparer les lignes saines (correctes ou corrigées) des lignes en anomalie, car nous ne chargerons uniquement les lignes saines dans le référentiel (les lignes en anomalie peuvent être également redirigées pour un traitement spécifique).
Pour ce faire nous pouvons utiliser une transformation de type "Conditional Split".
Le Conditional Split permet de router les lignes vers des sorties distinctes en fonction de conditions définies.
La condition que nous allons mettre en œuvre va tester le contenu de la colonne [RecordStatus] pour chacune des lignes.
La colonne [RecordStatus] étant directement enrichie par la tâche DQS, elle retourne le statut de la ligne suite à la confrontation de celle-ci aux règles de la base de connaissance.
Il suffit ensuite de regrouper ces lignes dans un même flux, grâce à une transformation de type Union All.
Nous devons également enrichir les lignes avec des informations nécessaires au chargement dans MDS.
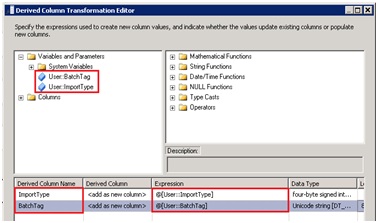
Pour ce faire nous utiliserons une transformation de type DerivedColumn.
MDS requiert deux informations pour le chargement par batch, ImportType et BatchTag :
- ImportType correspond au type d’import à réaliser
- BatchTag correspond au nom que nous souhaitons donner au chargement, (On retrouvera cette information par la suite dans l’interface Master Data Manager).
Le tableau ci-dessous récapitule les différentes valeurs pour ImportType :

Pour réaliser l’opération, nous allons définir ces deux valeurs comme variable de package pour ensuite les utiliser dans la transformation DerivedColumn.
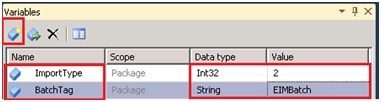
Utilisation des deux variables dans la transformation DerivedColumn :
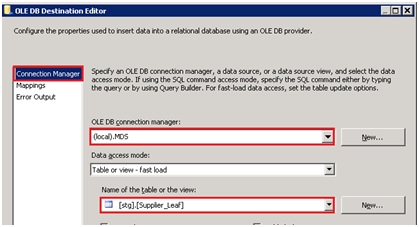
Il ne nous reste plus qu’à écrire les lignes dans les tables de Staging d’MDS.
Nous allons donc utiliser un composant destination de type OLE DB, le faire pointer vers l’instance MDS et sélectionner la table de Staging à alimenter.
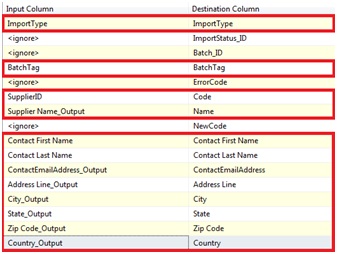
Configurer le mapping pour faire coïncider les données en entrée avec les données en destination :
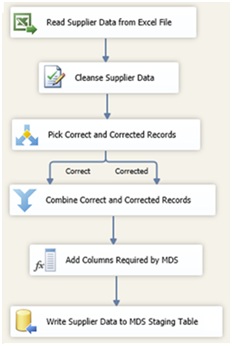
Voici donc la structure finale du DataFlow :
- Extraction des données à partir d’un fichier Excel
- Confrontation des données aux règles de la base de connaissance DQS
- Dissociation des lignes saines (Correctes + Corrigées) des lignes en anomalie
- Regroupement des lignes dans un flux de données unique
- Enrichissement des lignes avec les informations requises par MDS en vue de leur intégration
- Alimentation en base de Staging MDS
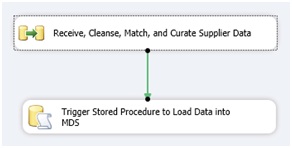
Une fois chargée en zone de Staging, nous pouvons automatiser l’alimentation effective du référentiel.
Ce déclenchement peut être effectué par le biais d’une procédure stockée dont nous allons lancer l’exécution grâce à une simple tâche de type SQL Task.
Code SQL de lancement de la procédure :
USE [MDS_DB]
GO
EXEC[stg].[udp_Supplier_Leaf] @VersionName=N'VERSION_1',@LogFlag= 1,@BatchTag=N'EIMBatch'
GO
Cette procédure stockée, tout comme la table de staging, est crée lors de l'instanciation de l'entité dans MDS.
Nous pouvons à présent vérifier au sein de l’interface Master Data Services que l’intégration s’est déroulée correctement.
Dans l'interface Web "Master Data Manager", sous l’onglet Import Data, nous avons une vue sur les différents chargements ayant été effectué. On y retrouve entre autre le BatchTag que nous avons renseigné dans le package SSIS ainsi que l’entité ciblé (Supplier) et le nombre de ligne chargées.
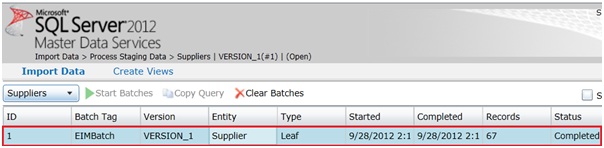
Les données nettoyées sont désormais chargées au sein de l’entité Supplier dans le référentiel de données.
Conclusion
Dans ce billet, nous avons vu comment il était possible d’alimenter un référentiel de données MDS de manière automatisée par le biais de SSIS tout en maitrisant la qualité de ses données à l’aide de DQS.
Ceci est un exemple typique de solution d’Enterprise Information Management (EIM) implémentée avec la plateforme Microsoft SQL Server.
L'expertise Microsoft Consulting Services au service de ses clients
MCS propose une offre de service packagée pour implémenter des solutions de Master Data Management sur des plateformes SQL Server & MSBI.
Cette méthodologie de mise en œuvre de solutions de Master Data Management a été éprouvée à travers des réalisations chez des clients grands comptes dont voici quelques exemples :
- Grandes Sociétés d’Assurance Françaises
- Grandes Banques Françaises
- Gestionnaire de flotte de véhicules
Elle peut aussi bien être mise en œuvre dans le cadre d’un projet géré par Microsoft Services, que dans le cadre d’une assistance technique sur certains aspects du projet (architecture, validation…).
Pour plus d’informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d’informations sur les blogs « SQL Server chez les clients ».
 |
Jordan Doullé, Consultant Data Insights, Microsoft Consulting Services Spécialiste des problématiques EIM d’Intégration de donnée, de Gestion de Master Data, et de Qualité de donnée, j’interviens sur l’ensemble des phases des projets décisionnels de nos clients. |