SQL Server chez les clients – Les fondamentaux et les bonnes pratiques de la gestion des autorisations dans le moteur relationnel

Pour les bases de données critiques, il est indispensable de mettre en place des solutions de gestion des autorisations à la fois rigoureuse et efficace pour :
- Appliquer le principe des moindres privilèges
- Faciliter la gestion et les évolutions
- Satisfaire aux exigences de sécurité et de confidentialité
Pour cela, une bonne compréhension des principes et des mécanismes fondamentaux de la gestion des autorisations du moteur relationnel SQL Server est indispensable.
Dans cet article, nous allons présenter de manière synthétique les différents aspects du modèle des autorisations, ainsi que les bonnes pratiques dans le cadre de leur mise en œuvre.
Le modèle des autorisations
Le modèle des autorisations SQL Server repose sur 3 concepts de base :
« Entité Sécurisable »
(« Securable » dans la documentation en ligne en langue anglaise) : Tout objet sur lequel s’exercent les contrôles d’accès. Les « Entités Sécurisables » sont organisées en « Classes » et dans une structure hiérarchique à plusieurs niveaux : les « Scopes ».
Remarque : Un « Scope » est lui-même une classe d’« Entité Sécurisable ». Les entités sécurisables de type « Scope » ont un rôle particulier dans la gestion des autorisations : elles permettent de propager les autorisations vers les entités filles.
Depuis la version 2005, il existe 3 « Scopes » dans le moteur relationnel SQL Server : « Instance » (ou « Serveur »), « Base de données » et « Schéma ».
« Autorisation »
(« Permissions ») : Toute action de contrôle d’accès sur une « Entité Sécurisable » ou une « Classe d’Entité Sécurisable ».
Les autorisations sont reliées par des relations d’inclusion : Une autorisation « forte » sur une entité sécurisable peut impliquer un ensemble d’autorisations plus faibles sur cette même entité.
Une « Autorisation » appliquée peut être un accord (GRANT) ou un refus (DENY).
« Principal »
Tout acteur pouvant accéder aux « Entités Sécurisables » de manière contrôlée en fonction de ses « Autorisations ».
Remarque : Un « Principal » est aussi une « Entité Sécurisable ». Les autorisations possibles sur un « Principal » sont par exemple, CREATE, ALTER, IMPERSONATE.
Comme toutes les « Entités Sécurisables », les « Principaux » sont de différents types (classes) et associés aux différents scopes :
-
Au niveau « Instance » : « Login », « Rôle serveur fixe », « Rôle serveur défini par utilisateur ».
Au niveau « Base de données » : « User », « Rôle base de données fixe », « Rôle base de données défini par utilisateur », « Rôle d’application ».
Dans la suite de ce texte, sans précision supplémentaire :
Les « Rôles serveur ou bases de données fixes » seront toujours suffixés « fixe ».
Un « Rôle serveur » désignera un « Rôle serveur défini par utilisateur ».
Un « Rôle base de données » désignera un « Rôle base de données défini par utilisateur ».
La figure suivante (empruntée de la documentation en ligne) illustre de manière claire l’organisation hiérarchique des « Entités Sécurisables » et des « Principaux », ainsi que leur positionnement aux différents niveaux (« Scopes ») au sein du moteur relationnel SQL Server:
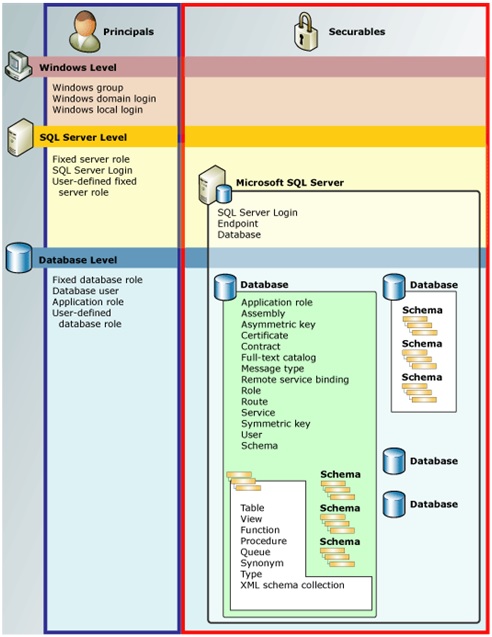
L'Organisation hiérarchique des Entités Sécurisables
Comme le montre la partie droite de la figure précédente, les « Entités Sécurisables » sont organisées en différentes « classes » et selon une structure hiérarchique à 3 niveaux (« Scopes ») :
SERVER
ENDPOINT
LOGIN
SERVER ROLE
…
DATABASE
SERVICE
USER
ROLE
…
SCHEMA
TYPE
OBJECT
…
La maitrise de cette structure est fondamentale pour bien comprendre le comportement du système des autorisations de SQL Server.
Lorsqu’une « Autorisation » est configurée (accordée ou refusée) au niveau d’un « Scope », elle est automatiquement propagée au niveau de tous objets enfants et petits-enfants, y compris les scopes enfants et petits-enfants.
Lorsqu’un objet est créé sans propriétaire explicitement désigné, son propriétaire « par défaut ou implicite » peut être le propriétaire du « Scope » auquel il appartient (et non celui qui a exécuté la commande « CREATE … »).
Comme nous allons voir tout au long de cet article, la fonction « sys.fn_builtin_permissions » permettre de connaitre les métadonnées les plus fondamentales du système des autorisations.
Il n’existe pas de vue catalogue, ni de fonction système, permettant de lister toutes les instances particulières d’entités sécurisables, mais il existe en général une vue catalogue permettant de lister toutes les instances d’une classe particulière d’entités sécurisables.
Par exemple
« sys.databases » permet de lister toutes les bases de données ;
« sys.schemas » permet de lister tous les schémas dans le contexte de la base courante ;
« sys.objects » permet de lister tous les objets (tables, vues, procédures, fonctions, etc.) de la base de données courantes.
Etc.
Les principaux
Il existe 2 grandes catégories de « Principaux » :
Ceux qui sont porteurs d’identités et d’autorisations : les « Logins » et les « Users »
Ceux qui sont uniquement porteurs d’autorisations : les « Rôles ».
« sa » et « sysadmin»
Avant de commencer notre discussion sur les « principaux », il nous faut évacuer le cas particulier des principaux très spéciaux que sont « sa » et « sysadmin » :
« sa » et tout login membre de « sysadmin » court-circuitent complètement le système d’autorisation de SQL Server.
Ils ont donc un intérêt limité dans une discussion portant sur la gestion des autorisations. Ainsi, sauf mention explicite, ils sont exclus des discussions des paragraphes suivants.
Les « Logins » et les « Users»
Les « Logins » au niveau instance et les « Users » au niveau base de données sont les « Principaux » de base : le système d’authentification et d’autorisation de SQL Server ne peut pas fonctionner sans les « Logins » et « Users ».
Les « Logins » interviennent à la fois dans les processus de l’authentification (permettant de connecter à une instance) et de l’autorisation sur les ressources au niveau instance ;
Les « Users » sont impliqués dans le processus d’identification lors de l’accès aux bases de données, ainsi que dans celui de l’autorisation sur les ressources des bases de données.
Un « Login » est utilisé pour établir une connexion avec une instance. Une fois la connexion établie, une session doit être ouverte dans le contexte d’une base de données.
A tout « Login » est associée une base de données par défaut : à l’ouverture de la session, la base de données sera celle indiquée par la chaine de connexion ou la base de données par défaut, si la chaine de connexion n’indique pas de valeur explicite.
Pour pouvoir accéder à une base de données particulière, le « Login » doit être explicitement associé à un « User » de la base de données cible.
Dans le cas contraire, il sera implicitement et temporairement mappé à « Guest » (en tant que « User » de la base) et ne pourra se connecter à la base que si l’autorisation « CONNECT » est accordée à « Guest » (Par défaut, ce n’est pas le cas).
La vue catalogue permettant de lister les « Logins » est « sys.server_principals ».
Cette vue peut être consultée quel que soit le contexte de base de données.
La vue catalogue permettant de lister les « Users » est « sys.database_principals ».
Cette vue doit être consultée dans le contexte de la base de données cible.
Les « Rôles … »
Un « Rôle » peut être défini soit au niveau (scope) « Instance » (serveur), soit au niveau « Base de données ».
Un « Rôle serveur » peut accepter comme membres des « Logins » ou d’autres « rôles serveur » ;
Un « Rôle base de données » peut accepter comme membres des « Users » ou d’autres « rôles base de données » ;
En termes de « comportement », il existe 2 types de « Rôles » :
Les « Rôles fixes » (au niveau instance ou base de données) sont créés lors de l’installation de SQL Server. Ils ne peuvent être ni supprimés, ni modifiés (en termes d’autorisations associées). En plus, un « Rôle fixe » ne peut être membre,ni d’un autre « Rôle fixe », ni d’un« Rôle défini par utilisateur ».
Les « Rôles définis par utilisateur » (au niveau instance ou base de données) sont créés et restent complètement configurables par les utilisateurs (DBA). Un « Rôle défini par utilisateur » peut être membre d’un autre « Rôle défini par utilisateur ».
Un « Rôle défini par utilisateur » peut aussi être membre d’un « Rôle fixe » (autre que « sysadmin »), mais cela n’est pas recommandé pour des raisons que nous allons expliquer plus loin.
Les « Rôles fixes » (autres que « sysadmin » et « public » ) existent dans les versions récentes de SQL Server essentiellement pour des raisons de compatibilité ascendante. Un des objectifs de cet article est de vous inviter à abandonner l’usage de ces « Rôles fixes » au profit des « Rôles définis par utilisateur ».
Les « Rôles définis par utilisateurs » sont des « Principaux » secondaires dans le sens qu’ils ne sont pas indispensables au fonctionnement du système d’authentification et d’autorisation de SQL Server.
Cela étant, les « Rôles » permettent de regrouper les « Logins » ou « Users » pour leur attribuer collectivement et de manière cohérente les autorisations. A ce titre, ils constituent un moyen pratique essentiel pour gérer plus efficacement les autorisations.
Propriétaire d’entité sécurisable
Toute entité sécurisable a un propriétaire, un principal de type Login ou User :
Le propriétaire possède toutes les autorisations sur l’entité sécurisable qu’il possède ;
Aucune autorisation sur une entité sécurisable ne peut être retirée (ni DENY, ni REVOKE) à son propriétaire ;
Mais, le titre de propriété peut être transféré d’un principal à un autre. Une fois la propriété de l’entité est transférée à un autre principal, l’ancien propriétaire perd toutes les autorisations dues à son statut de propriétaire.
Une autre remarque intéressante par rapport à l’entité et son propriétaire : le propriétaire d’un rôle ne possède pas automatiquement les autorisations accordées au rôle.
S’il ne lui est pas toujours permis d’ajouter ces autorisations à lui-même avec la commande GRANT, il lui est possible d’ajouter lui-même en tant que membre du rôle dont il est propriétaire et d’acquérir ainsi les autorisations associées.
Par défaut, c’est le « créateur » (login ou user qui exécute la commande CREATE) qui sera le propriétaire (« Owner ») de toute nouvelle entité, mais un autre principal peut être désigné propriétaire :
Si la commande CREATE supporte l’option « AUTORISATION »
Ou par transfert de propriété via la commande « ALTER AUTHORIZATION … »
Ou par héritage du scope parent : les tables et procédures sont créées sans propriétaire explicite et ont pour propriétaire celui du schéma dont elles font partie.
Autres principaux spéciaux
En plus de « sa », « sysadmin » et propriétaires des entités sécurisables, il existe d’autres principaux spéciaux qu’il convient de connaitre afin d’appréhender dans son ensemble le système de gestion des autorisations :
« dbo »
« db_owner »
« public » (rôle serveur oubase de données)
« guest » (utilisateur de base de données)
« dbo » est un « database user » fixe (créé automatiquement avec la base de données, ne peut être supprimé), l’équivalent de « sa » au niveau de la base de données. En plus de posséder toutes les autorisations dans le scope de la base de données, il a comme particularité d’être mappé explicitement au login propriétaire de la base de données et implicitement à tous les logins membres de « sysadmin ». C’est le seul « database user » qui peut être utilisé par plusieurs logins pour accéder à la base de données.
« db_owner » est un « rôle fixe base de données », l’ équivalent de « sysadmin » au niveau de la base de données. Mais cette équivalence est trompeuse: en effet, un membre « non dbo » (comme « sa » est un membre inaltérable de « sysadmin », « dbo » est un membre permanent de « db_owner » et ne peut en être retiré) de ce rôle possède potentiellement toutes les autorisations sur tous les objets de la base, mais ses autorisations peuvent lui être retirées, alors qu’aucune modification d’autorisation n’est permise lorsqu’il s’agit de « dbo ». Le système de gestion des autorisations est « court-circuité » dans le cas de « dbo » comme pour « sa » et « sysadmin », mais pas dans le cas de « db_owner ».
« public » est un rôle fixe qui existe à la fois au niveau de l’instance et des bases de données, et joue un rôle équivalent dans les deux cas : tout « login » / « user » est automatiquement membre du rôle « public » et ne peut y être retiré ; et de ce fait, hérite de toutes les autorisations accordées à « public ».
« guest » est un « database user » qui permet de donner accès à tout login n’étant pas explicitement mappé à un « user » de la base de données. Il est par défaut désactivé pour toutes les bases de données créées par utilisateurs et activé pour les bases de données systèmes « master », « msdb » et « tempdb ».
Les autorisations : Deux systèmes en parallèles ou le poids de la compatibilité ascendante
Jusqu’à sa version « 2000 », la gestion des autorisations du moteur relationnel SQL Server est essentiellement basée sur les « Rôles Fixes » :
Rôles fixes serveur : « sysadmin », « securityadmin », etc.
Rôles fixes base de données : « db_owner », « db_securityadmin », etc.
Ce système a l’avantage d’être « simple », au moins pour une première approche. Mais du fait qu’il est basé sur un système d’autorisations granulaires insuffisamment structuré, mélangeant « commandes » (statement) et « objets », il souffre d’un manque de précision et de souplesse.
SQL Server 2005 introduit le système des « Autorisations Granulaires et Hiérarchiques » (« AGH » dans la suite de cet article) présentant une architecture bien structurée. Ce nouveau système des AGH permet une gestion des autorisations plus souple, plus précise et plus transparente.
Cependant, la migration du système de gestion des autorisations depuis les « Rôles fixes » vers les « AGH » est un processus très long, aussi bien pour SQL Server en tant que produit logiciel que pour les clients qui ont développé leurs solutions basées dessus. Elle n’est toujours pas terminée avec la sortie de la toute nouvelle version SQL Server 2014.
Pour des raisons de compatibilité ascendante, SQL Server continuera probablement à maintenir la présence des « Rôles fixes », même si les « AGH » permettent de réaliser toutes les fonctions offertes par les « Rôles fixes » et bien plus.
Ainsi, avec les versions de SQL Server actuellement déployées chez nos clients (de 2005 à 2014), nous sommes en présence de deux systèmes parallèles de gestion des autorisations, avec chacun ses propres métadonnées et peu de passerelle entre eux. Bien entendu, les 2 systèmes agissent sur les autorisations effectives accordées par le système.
Microsoft recommande à ses clients d’utiliser le nouveau système des « Autorisations Granulaires et Hiérarchique » (AGH) pour leurs nouveaux développements et de migrer leurs solutions existantes qui s’appuient sur les « Rôles fixes » vers les « AGH ».
Rappel historique sur les « Rôles fixes »
Remarque préliminaire :
Dans la suite de cette discussion, les « Rôles fixes » désignent les rôles fixes serveur et base de données autres que « sysadmin » et « public ».
En effet, « sysadmin » possède invariablement toutes les autorisations, quel que soit le système des autorisations ; alors que « public » n’en possède que le minimum et peut accepter les autorisations supplémentaires du système des AGH. Ainsi, « sysadmin » et « public » sont des rôles fixes complètement compatibles avec les « AGH ».
Les « Rôles fixes » ont été introduits à une époque (avant la version 2005) où SQL Server ne disposait pas encore d’un système d’autorisations granulaires bien structuré.
Par définition, les autorisations associées à un Rôle Fixe ne sont pas modifiables par un utilisateur (DBA).
Les procédures système « sp_srvrolepermission » et « sp_dbfixedrolepermission »permettent de connaitre les autorisations granulaires des rôles fixes serveur ou base de données, telles qu’elles sont dans les versions antérieures à 2005. Leur correspondance exacte vers les nouvelles « AGH » n’est pas possible. Une correspondance approximative a été documentée pour les versions 2005, 2008 et 2008 R2, mais abandonnée par la version 2012.
“Permissions of Fixed Server Roles (Database Engine)" https://technet.microsoft.com/en-us/library/ms175892(v=sql.105).aspx
“Permissions of Fixed Database Roles (Database Engine)" https://technet.microsoft.com/en-us/library/ms189612(v=sql.105).aspx
Pour des raisons de compatibilité ascendante, les rôles fixes (autres que « sysadmin » et « public ») continueront donc de garder leurs autorisations granulaires à l’ancienne.
Les autorisations des rôles fixes ne seront donc pas migrées vers les « AGH », mais gardées inchangées jusqu’à la fin de leur support.
Associé aux rôles fixes, un ensemble de procédures stockées systèmes assurait les actions concrètes du système de gestion des autorisations. Les autorisations d’exécution de ces procédures stockées système sont explicitement accordées aux rôles fixes et renforcées par la présence dans leurs codes des vérifications d’appartenance de l’appelant aux rôles fixes correspondants.
Ces procédures stockées systèmes sont progressivement déclarées obsolètes et mises en retraite. Elles sont ou seront remplacées par des commandes DDL de type CREATE / ALTER / DROP.
Comparaison entre les deux systèmes
Avant de quitter définitivement le monde des « rôles fixes » et entrer dans celui des « AGH », le tableau suivant résume les caractéristiques respectives des deux systèmes :
|
|
Rôles fixes |
AGH et Rôles définis par utilisateur |
|
Autorisations granulaires
|
Peu structurées, opaques (pas de visibilité globale) |
Hiérarchiques et transparentes, consultable via « sys.fn_builtin_permissions » |
|
Commandes de gestion des entités
|
Procédures stockées système (sp_XXX), commandes DBCC, etc. Quelques DDL |
DDL (CREATE, ALTER, DROP) |
|
Commandes de gestion des autorisations
|
Procédures stockées système (sp_XXX), commandes DBCC, etc. GRANT, DENY, REVOKE (GDR) sur les « objets » et « commandes » (statements) |
GRANT, DENY, REVOKE (GDR) sur les « classes » et « objets » |
|
Visibilités des membres
|
« sys.server_principals », « sys.server_role_members » « sys.database_principals », « sys.database_role_members » |
|
|
Visibilité des autorisations explicites
|
« sp_srvrolepermission » « sp_dbfixedrolepermission » |
« sys.server_permissions » « sys.database_permissions » |
|
Visibilité des autorisations effectives
|
« sys.fn_my_permissions » et « HAS_PERMS_BY_NAME », mais avec approximations, car il s’agit d’une vision à travers le filtre des AGH |
« sys.fn_my_permissions » et « HAS_PERMS_BY_NAME » |
Remarques :
Depuis SQL Server 2012, il est possible de définir des rôles serveur en plus des Rôles fixes serveur.
Les commandes « ALTER SERVER ROLE … » et « ALTER ROLE … » permettent d’ajouter un « Rôle défini par utilisateur » en tant que membre d’un « Rôle fixe ». Mais de par le manque de visibilité sur les autorisations des rôles fixes (ou de leur équivalence exacte en « AGH »), ce type de construction n’est pas recommandée. En effet, une fois ajouté en tant que membre d’un rôle fixe, un rôle défini par utilisateur n’est plus complètement dans le monde des « AGH » et ses autorisations ne sont plus visibles avec précision et transparence. Donc,
Ne pas ajouter un « Rôle défini par utilisateur » en tant que membre d’un « Rôle fixe ».
Le système des Autorisations Granulaires et Hiérarchiques (AGH)
La fonction « sys.fn_builtin_permissions »
La fonction système « sys.fn_builtin_permissions » est LA seule point d’entrée pour explorer les métadonnées et la structure des autorisations granulaires et hiérarchiques (AGH).
Comme son nom l’indique, le système des AGH se caractérise par la « granularité » des autorisations et la « hiérarchie » dans leur organisation.
Concernant l’aspect « granularité », la requête ci-dessous permet de lister TOUTES les AGH :
SELECT class_desc,permission_name FROM sys.fn_builtin_permissions(DEFAULT)
Depuis la version 2005, la liste des AGH s’allonge avec la sortie de chaque nouvelle version de SQL Server. Le nombre exact des autorisations granulaires dépend de la version de SQL Server. Par exemple, sous SQL Server 2012 SP1 édition Entreprise, la requête ci-dessus retourne 214 autorisations granulaires.
Les principales catégories desautorisations sont :
AUTHENTICATE, CONNECT, CONTROL, TAKE OWNERSHIP, IMPERSONATE ;
ALTER, CREATE, DELETE, VIEW, REFERENCE ;
EXECUTE, INSERT, SELECT, UPDATE.
Pour une description détaillée des AGH individuelles, nous vous invitons à consulter la documentation en ligne.Pour la version 2012, cette description détaillée se trouve à l’adresse URL suivante : https://technet.microsoft.com/en-us/library/ms191291(v=sql.110).aspx .
Un document poster est également disponible sur le site Technet Microsoft : https://social.technet.microsoft.com/wiki/contents/articles/11842.sql-server-database-engine-permission-posters.aspx
Pour étudier l’aspect « Hiérarchique » du système des AGH, nous faisons encore appel à la fonction « sys.fn_builtin_permissions ». En effet, elle permet de consulter :
- La hiérarchie des classes des entités sécurisables avec la requête suivante
SELECT DISTINCT parent_class_desc,class_desc
FROM sys.fn_builtin_permissions(DEFAULT)
ORDER BY parent_class_desc,class_desc
- La hiérarchie des autorisations granulaires et hiérarchiques (AGH) avec la requête suivante
SELECT * FROM sys.fn_builtin_permissions(DEFAULT)
ORDER BY parent_class_desc,class_desc,parent_covering_permission_name,covering_permission_name,permission_name
Voici un extrait de cette liste, arrangée (raccourcie et réordonnée) pour faciliter la lecture et aider à illustrer nos propos :
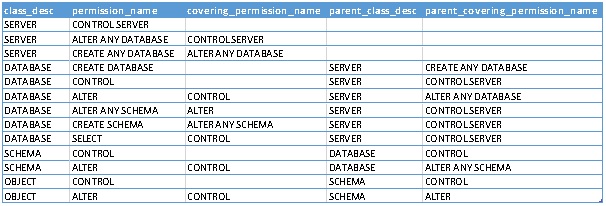
D’après cette liste, chaque AGH individuelle peut avoir jusqu’à 2 autorisations couvrantes (« covering or implying permissions ») immédiates :
0 ou 1 « autorisation couvrante » sur la même entité (la colonne « covering_permission_name »). En général, à part « CONTROL » qui est l’autorisation la plus forte, toutes les autres AGH ont une autorisation couvrante.
0 ou 1 « autorisation couvrante » sur le parent (la colonne « parent_covering_permission_name »).
Ainsi,
Une autorisation « forte » posée sur une entité de niveau supérieur, de type scope par exemple, permet d’induire un grand nombre d’autorisations équivalentes ou plus faibles sur les entités de niveaux inférieures,l’exemple le plus marquant étant bien sûr « CONTROL SERVER » permettant d’induire toutes les autorisations de cette liste.
Inversement, une autorisation sur une entité sécurisable peut être obtenue par assignation directe ou par induction à chemins multiples.
A partir de la fonction « sys.fn_builtin_permissions », la documentation en ligne propose une fonction intéressante pour mieux illustrer la structure hiérarchique des autorisations « AGH ».
Pour une AGH donnée, elle permet de connaitre toutes les AGH parentes qui peuvent l’induire.Le code de cette fonction est accessible à la page web « Autorisations couvrantes/implicites » https://technet.microsoft.com/fr-fr/library/ms177450(v=sql.105).aspx .
Par exemple, pour l’autorisation « ALTER » sur la classe « OBJECT », cette fonction retourne le résultat suivant :
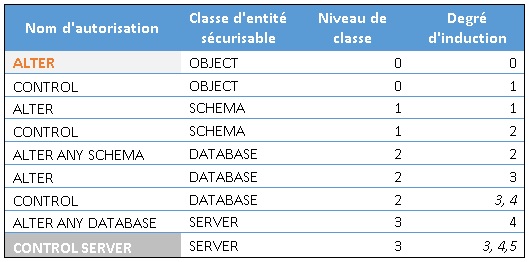
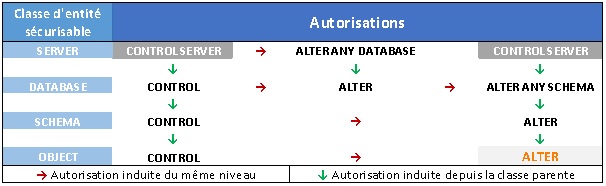
Il existe donc 8 autorisations qui permettent d’induire l’autorisation « ALTER » sur un « OBJET ». Le schéma suivant illustre le positionnement de ces 8 autorisations reliées par 5 chemins d’induction différents.
Les commandes "GRANT","DENY" et "REVOKE" (GDR)
La gestion effective des autorisations se fait à l’aide des commandes « GRANT, DENY, REVOKE » (« GDR ») avec la syntaxe générale suivante :
<G/D/R><AGH> ON <Securable> TO <Principal>
Ces commandes permettent d’accorder (GRANT),de refuser (DENY) ou de retirer (REVOKE) une autorisation de manière explicite.
Les résultats directe de ces commandes sont visibles à travers les vues catalogues « sys.server_permissions » et « sys.database_permissions » .
Pour maintenir un état persistant et cohérent des autorisations, le système des AGH observe les règles de superposition et de précédence suivants :
- « Superposition temporelle » : Posées sur la même entité sécurisable, les commandes GRANT et DENY sont à force égale et c’est la dernière commande qui prime.
“GRANT P ON S”puis“DENY P ON S” =>“DENY P ON S”
“DENY P ON S”puis“GRANT P ON S” =>“GRANT P ON S”
- « Superposition spatiale » : Lorsque GRAND et DENY posées explicitement sur des entités différentes, leurs effets induits ou directs peuvent se superposer sur une même entité cible. Dans ce cas, DENY prime sur GRANT sur cette entité cible.
Soient S1 et S2 2 entités liées par la relation père-fils : S1 est père de S2
“GRANT P ON S1” et “DENY P ON S2” =>“DENY P ON S2”
“DENY P ON S1” et “GRANT P ON S2” =>“DENY P ON S2”
Cette règle s’applique aussi aux cas où un principal (login ou user) hérite des autorisations provenant de plusieurs rôles dont il est membre.
Exception : Il existe une seule exception à la règle ci-dessus. Pour des raisons de compatibilité ascendante, un GRANT sur une « colonne » prime sur un « DENY » au niveau de la table parente.
REVOKE porte toujours sur une autorisation (GRANT ou DENY) existante et explicitement posée. Les effets de GRANT et de DENY sont persistants, mais REVOKE efface de manière neutre et symétrique l’effet de la commande existante, GRANT ou DENY :
“GRANT P ON S” puis “REVOKE P ON S” => ni GRANT ni DENY de P sur S
“DENY P ON S” puis “REVOKE P ON S” => ni GRANT ni DENY de P sur S
Remarque : Il n’est pas permis de d’utiliser les commandes GDR pour modifier les autorisations de « sa », « sysadmin », « dbo », propriétaire de l’entité ou de soi-même.
Autres mécanismes importants du système de gestion des autorisations
Pour compléter notre discussion sur le modèle des autorisations, nous allons évoquer rapidement quelques autres mécanismes importants du système de gestion des autorisations qui permettent d’acquérir des autorisations de manière indirecte et interviennent ainsi dans l’évaluation des autorisations effectives.
Les chaines de propriété (« Ownership chain ») intra et inter bases
Une« chaîne de propriété » est un mécanisme qui provoque un court-circuit partiel du système des autorisations.
Une « chaîne de propriété » se forme entre les objets d’une même base de données, lorsque ces objets sont reliés par des relations de « référencement », et qu’ils ont le même propriétaire.
Par exemple, la procédure stockée P fait référence à la table T (SELECT, UPDATE, etc.). Si P et T ont le même propriétaire, elles forment une chaine de propriété.
Lorsqu’une telle chaîne de propriété est identifiée / reconnue par le système de gestion des autorisations, le contrôle d’autorisation a bien lieu sur le 1er objet de la chaîne, mais non sur les autres objets de la chaîne.
Ce comportement spécial du système de gestion des autorisations est souvent exploité pour autoriser les accès contrôlés aux objets de base (par exemple les tables), sans donner aucune autorisation directe et explicite sur ces mêmes objets.
Remarques :
- Les chaînes de propriété s’applique aux commandes DML (SELECT, UPDATE, INSERT, DELETE), mais pas aux commandes DDL ;
- Les chaînes de propriété ne s’appliquent pas aux requêtes SQL dynamiques.
La chaîne de propriétés peut, dans certains cas, traverser les frontières des bases de données et s’appliquer aux objets dans des bases de données différentes :
- Lorsque tous les objets de la chaîne (reliés par la relation de référencement) ont des propriétaires (user dans différentes bases de données) qui mappent sur le même login ;
- Le login possède l’autorisation « CONNECT » à toutes les bases de données (éventuellement par l’intermédiaire de l’utilisateur « guest », si ce dernier n’est pas « désactivé »)
- Et que la propriété « Cross Database ownership chain » est activée sur toutes les bases de données impliquées dans la chaîne des objets.
On parle alors de la « Chaîne de propriété inter-bases de données ».
La « Chaîne de propriété inter-bases de données » (« Cross Database ownership chain ») est désactivée par défaut sur toutes les bases de données créées par les utilisateurs (maisactivéesur « master », « msdb » et « tempdb »), car il s’agit d’une propriété très dangereuse d’un point de vue sécurité. En effet, elle peut permettre à un utilisateur propriétaire d’une base de données de s’appuyer sur cette dernière pour élever ses privilèges et prendre le contrôle sur les autres bases de la même instance.
Les Rôles d'application
Les « Rôles d’application » sont un type spécial de « Principaux » au niveau base de données.
Un « Rôle d’application » ressemble plutôt à un « User » sans « Login » correspondant : il permet à une application de s’exécuter avec les autorisations qui lui sont propres.
Contrairement aux rôles (fixes ou définis par utilisateurs), un « Rôle d’application » ne peut pas avoir de membre.
Les « Rôles d’application » fonctionnent quel que soit le mode d’authentification utilisé par l’application.
Un « Rôle d’application » est inactif par défaut, il est activé par la commande « sp_setapprole » accompagnée d’un mot de passe. Les autorisations attribuées sont en générale limitées à sa base de données d’origine et ne peut accéder aux ressources des autres bases de données qu’à travers les autorisations attribuées à l’utilisateur « guest ».
L’utilisation d’un « Rôle d’application » ressemble à l’« Impersonation » que nous allons discuter dans le paragraphe ci-dessous :
Il y a un changement de contexte d’exécution dans le but d’acquérir de nouvelles autorisations.
Il y a quelques différences de styles et de compatibilités, mais pas de différence fondamentale au niveau des principes de fonctionnement et de capacités.
Impersonation
L’impersonation est le processus qui consiste à prendre l’identité d’un autre principal (de type Login ou User) et à changer de contexte d’exécution (au niveau de l’instance ou d’une base de données).
L’impersonation peut se faire de manière explicite, avec la commande « EXECUTE AS … », ou implicite en exécutant un module (procédure, fonction, trigger, etc.) créé avec l’option « WITH EXECUTE AS … ».
Lorsqu’un principal exécute une procédure créée avec l’option « WITH EXECUTE AS … », seule l’autorisation d’exécution de la procédure est vérifiée contre le principal appelant. Les autorisations des actions effectuées dans la procédure sont vérifiées contre le principal cible de l’impersonation, spécifié après « WITH EXECUTE AS … ». Bien entendu, au moment de créer ou de modifier la procédure, l’autorisation « IMPERSONATE » est vérifiée contre le principal qui crée ou modifie la procédure.
L’impersonation est ainsi un moyen très puissant pour acquérir des privilèges élevés. L’autorisation « IMPERSONATE »(sur les classes LOGIN ou USER) doit donc être contrôlée avec beaucoup de précautions, en particulier lorsque l’entité cible est un principal sensible : « sa » ou autres membre de « sysadmin », « dbo », etc.
Les modules signés
Un module signé (procédure stockée, fonction, etc.) permet l’acquisition d’autorisations supplémentaires sans changement de contexte d’exécution.
Les autorisations supplémentaires sont apportées par l’intermédiaire d’un login basé sur un certificat :
Un login basé sur un certificat permet de recevoir les autorisations nécessaires, mais ne peut être utilisé pour se connecter à SQL Server, et donc ne peut être cible d’impersonation.
Le certificat permet de signer la procédure et d’associer à l’exécution de la procédure les autorisations supplémentaires apportées par le login ci-dessus.
A l’exécution, l’autorisation « EXECUTE » de la procédure est vérifiée contre le principal appelant. Les autorisations des actions effectuées par la procédure sont vérifiées contre le principal appelant ou le login associé au certificat qui a servi à signer la procédure.
La mise en œuvre des modules signés est certainement plus complexe que l’utilisation de l’impersonation, mais les procédures signées apportent des avantages uniques sur le plan de la sécurisation des accès aux données, en particulier, lorsqu’il s’agit de mettre en place des procédures appliquant les principes des moindres privilèges et de séparation des responsabilités.
En effet, outre le fait que l’exécution d’un module signé n’est pas accompagnée d’un changement de contexte de sécurité (donc plus facile à suivre dans un audit), la création de la procédure et l’ajout de la signature avec le certificat sont des actions qui peuvent être effectuées par des personnes différentes, avec des profils d’autorisations différents.
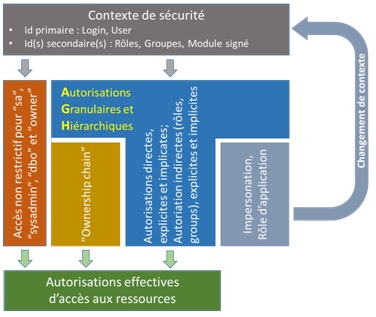
Evaluation des autorisations effectives
Lors de l’exécution d’une commande / requête, le système des autorisations détermine les « autorisations effectives » pour décider si une action particulière de la part d’un principal particulier sur un objet particulier doit être autorisée ou interdite.
La logique permettant d’aboutir à cette décision est basée sur un algorithme général comprenant les étapes suivantes
- Détermination du contexte d’exécution en fonction du principal contre qui les autorisations devront être vérifiées.
Lorsqu’un principal exécute une requête ou une commande, l’ensemble de ses identités aux niveaux de l’instance et de la base de données, ainsi que celles du module signé si ce dernier est concerné par l’exécution en cours, forment le contexte de sécurité de l’exécution de la requête ou de la commande. Le contenu de ce contexte de sécurité peut être consulté via
-
sys.login_token
sys.user_token
Un « token » contient 1 principal en tant que l’identité primaire et 0 à N principaux en tant qu’identités secondaires (Rôles ou Groupes Windows).
Autorisation directe en mode « court-circuit » si le principal qui exécute la commande / requête est dans l’un des cas suivants :
« sa » ou autre login membre du rôle fixe « sysadmin » ;
« dbo » de la base de données à laquelle appartient l’entité cible ;
Propriétaire de l’entité cible.
Autorisation indirecte ou en mode « court-circuit partiel », par l’intermédiaire de « chaine de propriété » ;
Evaluation d’autorisations effectives à partir des métadonnées des autorisations granulaires et hiérarchiques (AGH) : Autorisations explicites ou implicites (induites), directes ou indirectes (héritées des Rôles auxquels appartient le principal).
Les autorisations explicites directes sont décrites par les vues catalogues :
-
sys.server_permissions (filtrée par le principal id de login)
sys.databbbase_permissions (filtrée par le principal id de user)
Les autorisations explicites indirectes sont celles obtenues par les rôles serveurs ou base de données décrites par les vues catalogues :
-
sys.server_role_membership
sys.database_role_membership
sys.server_permissions (filtrée par le principal id du rôle serveur)
sys.databbbase_permissions (filtrée par le principal id du rôle base de données)
ou par l’intermédiaire d’un login de type groupe Windows.
L’évaluation des autorisations implicites ou induites se fait selon les principes décrits dans le paragraphe précédent consacré aux AGH en tenant compte de la hiérarchie des entités sécurisables et de la hiérarchie des autorisations.
Identification des autorisations requises nécessaires à l’exécution de la requête ou de la commande.
La vérification des autorisations échoue si au moins une des autorisations requises est explicitement ou implicitement refusée par DENY à l’une des identités du contexte de sécurité ;
La vérification des autorisations réussit si aucune autorisation requise n’est refusée (DENY explicite ou implicite) et que toutes les autorisations requises sont accordées par au moins un GRANT explicite ou implicite à l’une des identités du contexte de sécurité.
Ainsi, pour une autorisation granulaire exigée à l’exécution d’une commande, il existe multiples façons de la vérifier. Par exemple, « CONNECT DATABASE à MyDB pour LoginL » peut être obtenu par l’une des manières suivantes :
GRANT explicite à LoginL;
GRANT explicite à RoleR et LoginL est membre de RoleR
LoginL est membre de “sysadmin”
LoginL possède “CONTROL SERVER”
LoginL est propriétaire de la base MyDB
“guest” est active sur la base MyDB
Etc.
La figure ci-dessous montre ces différentes possibilités de manière schématique:
L’évaluation des autorisations effectives est un processus complexe et non complètement documenté.
Lorsqu’on se limite à utiliser les AGH et non les rôles fixes, le résultat de ce processus peut être obtenu avec précision à l’aide des fonctions telles que « sys.fn_my_permissions » ou « HAS_PERMS_BY_NAME » pour un contexte de sécurité donné.
Pour plus de détails, nous vous invitons à vous référer à la documentation en ligne à l’url https://technet.microsoft.com/en-us/library/ms191291(v=sql.110).aspx#_algorithm .
Les bonnes pratiques de la gestion des autorisations
Avant de terminer notre discussion, un peu longue, sur le système de gestion des autorisations, voici quelques bonnes pratiques en matière de gestion des autorisations que je voudrais partager avec vous, afin que vous puissiez tirer meilleure partie des fonctionnalités offertes par ce système complexe, et éviter les éventuelles désagréments que peuvent entrainer un système d’autorisations mal configuré.
Appliquer le principe des moindres privilèges ("Least Privileges")
Le principe des moindres privilèges est à la base de toutes les bonnes pratiques en matière de gestion des autorisations. Pour appliquer ce principe, veillez à :
Ne pas utiliser les « Rôles fixes » autres que « sysadmin » et « public » ; Migrer vos solutions existantes utilisant ces rôles fixes vers les « AGH ».
Utiliser les fonctions « sys.fn_my_permissions » ou « HAS_PERM_BY_NAME » pour connaitre les équivalents AGH d’une solution existante à migrer ;
Analyser les besoins réels de la solution existante pour déterminer les AGH réellement nécessaires.
Modifier, Tester et Valider la solution existante avec les AGH identifiées.
Utiliser les « AGH » et les « Rôles définis par utilisateurs » pour gérer les autorisations plus finement en fonction des besoins :
Se familiariser avec les AGH (si vous avez lu cet article jusqu’ici, un premier pas est déjà franchi dans ce sens !)
Se mettre au courant des nouvelles AGH apportées par chaque nouvelle version de SQL Server.
Par exemple, SQL Server 2014 apporte 3 nouvelles autorisations sur la classe «SERVER » : «CONNECT ANY DATABASE », « IMPERSONATE ANY LOGIN » et « SELECT ALL USER SECURABLES ».
L’article BLOG de mon collègue Hervé Marie donne une explication plus détaillée de ces autorisations avec des exemples d’usage : https://blogs.technet.com/b/sql/archive/2014/05/09/sql-server-chez-les-clients-les-nouveautes-sql-server-2014.aspx
Désactiver « sa » sur tout système de production :
Ne jamais utiliser « sa » pour les connexions applicatives ;
Ne jamais utiliser « sa » pour des opérations de DBA courantes.
Minimiser l’usage des logins membres de « sysadmin ».
Un principal à pouvoir illimité , hors contrôle du système d’autorisations, restera incontournable dans l’absolu, quel que soit le degré de perfection du système « AGH ».
Sur le plan pratique, utiliser un login avec privilège « sysadmin » est préférable à « sa », car cela permet d’auditer les actions DBA de manière nominative.
L’usage de logins membres de « sysadmin » doit être réduit à minimum et uniquement pour des opérations DBA exceptionnelles :
Toute commande applicative doit être exécutée avec un principal à privilèges contrôlées par les « AGH ».
Toute opération DBA courante doit être exécutée par un principal à privilèges contrôlées par les « AGH ».
Utiliser les modules signés pour encapsuler les fonctions / commandes qui nécessitent l’usage des principaux spéciaux : « sa », « sysadmin », « dbo ».
Utiliser les "AGH" avec les "Rôles défini par utilisateur"
SQL Server 2012 apporte la possibilité de définir des rôles serveurs, ce qui facilite l’abandon des « Rôles fixes » (sauf le « sysadmin ») ou de leur migration vers les « AGH ».
La combinaison des « AGH » et des « Rôles défini par utilisateur » donne toute la puissance nécessaire pour construire des systèmes d’autorisation, des plus simples aux plus sophistiqués. Attention cependant aux points suivants :
Les vérifications d’autorisations sont consommatrices de ressources systèmes (principalement CPU et Mémoire). Il faut donc chercher à préserver l’efficacité du système de gestion des autorisations en évitant de configurer des autorisations trop fines et trop complexes.
Accorder (GRANT) les autorisations sur des objets cibles de plus grosse granularité (par exemple Schéma) et interdire (DENY) les accès sur les objets de faible granularité. Les effets de ces actions seront propagés aux objets du scope, y compris les nouveaux objets qui seront créés dans le futur.
Un rôle défini par utilisateur peut être membre d’autres rôles définis par utilisateur. Attention à ne pas créer des structures trop complexes avec un nombre important de niveaux et en « spaghetti ».
(on répète) Ne pas ajouter un « Rôle défini par utilisateur » en tant que membre d’un « Rôle fixe ».
Accorder avec restrictions les autorisations sensibles : CONTROL, TAKE OWNERSHIP, IMPERSONATE
Pour les données particulièrement sensibles, interdire tout accès direct ; Contrôler les accès via des modules signés.
Maitriser l’usage et les effets des « Chaines de propriété » à l’intérieur d’une même base de données.
Eviter d’utiliser les « Chaines de propriété » inter base de données.
- La propriété « Cross databaseownershipchain » doit être désactivée au niveau instance;
Attention, lorsque la propriété « Cross databaseownershipchain » est activée au niveau de l’instance, elle est automatiquement activée pour toutes les bases de données, quel que soit la valeur de cette propriété au niveau de chaque base de données.
-
La propriété « Cross databaseownershipchain » ne doit être activée au niveau d’une base de données qu’après une évaluation sérieuse des différents éléments du contexte d’utilisation.
Eviter d’utiliser l’option base de données « Trustworthy »
Pour les accès cross bases de données, contrôler les accès via les modules signés.
Minimiser l’usage de l’impersonation, explicite ou implicite. Minimiser son scope et Maitriser ses effets lorsque son usage est inévitable.
Enfin, en corollaire de l’abandon des « Rôles fixes » :
Pour les opérations courantes de la gestion des autorisations, utiliser les nouvelles commandes DDL au lieu des procédures stockées systèmes déclarées obsolètes.
Pour consulter les métadonnées du système de gestion des autorisations, utiliser les vues catalogues et les DMVs, au lieu des procédures stockées systèmes déclarées obsolètes.
Appliquer le principe de la séparation des responsabilités ("Séparation of Duties")
La séparation des rôles et des responsabilités (« Separation of Duties ») est indispensable pour respecter les exigences réglementaires et lutter contre la fraude et les accès aux données non autorisés.
Pour cela, les privilèges du DBA doivent être contrôlées et maitrisées :le DBA est responsable du bon fonctionnement de la base de données (disponibilité, performance, sécurité), mais ne doit pas pouvoir accéder à toutes les données applicatives sans contrôles.
La séparation des rôles et de responsabilités implique qu’il n’y ait pas d’administrateur tout puissant, à qui il n’est pas possible de refuser un accès. Par conséquent, l’utilisation récurrente de « sa » et de « sysadmin » doit être bannie dans un tel environnement.
L’adoption des AGH est le point de départ pour toute mise en place concrète de dispositif technique visant à appliquer le principe de la séparation des rôles et de responsabilités. Pour une explication plus détaillée d’une telle solution, je vous invite à consulter l’article BLOG de mon collègue Christian François à l’url suivant : https://blogs.technet.com/b/sql/archive/2013/10/01/sql-server-chez-les-clients-confidentialite-des-donnees.aspx .
Utiliser l'authentification intégrée Windows
Utiliser l’authentification intégrée Windows fait partie des bonnes pratiques en matière de sécurité SQL Server. Dans ce contexte et comme conséquence logique de la pratique courante de gestion des comptes et groupes Windows, des logins sont créés dans SQL Server pour les groups « Windows » permettant ainsi de donner accès à tous les membres de ces groups Windows sans avoir à créer les logins dans SQL Server pour tous les comptes Windows individuels.
Cette pratique présente indéniablement des avantages en termes de facilité d’administration et de gestion. Il convient cependant d’être vigilant vis-à-vis de quelques effets de bord qui peuvent se produire dans certains cas :
Avant SQL Server 2012, il n’est pas possible de définir un schéma par défaut pour un user mappé à un login de type Group Windows. Cela entraîne la création automatique de user et schéma pour chaque compte Windows lorsque ce dernier accède à une base via un login de type Group Windows.
Avec SQL Server 2012, un schéma par défaut peut être défini pour un user mappé à un login de type Group Windows. Mais si un utilisateur Windows appartient à plusieurs groups Windows qui ont tous leur login dans SQL Server, il est plus difficile de prévoir quel sera le schéma par défaut utilisé par l’utilisateur Windows lorsqu’il accède à une base de données. En effet, le choix du schéma par défaut est fait implicitement en fonction de l’ordre de tri des SID des groups Windows. L’appartenance aux groups Windows pouvant changer en dehors des actions DBA, le comportement des requêtes exécutées par un tel utilisateur Windows peut donc apparaitre non déterministe, si les objets ne sont pas explicitement qualifiés avec leur schéma dans ces requêtes …
Enfin, un utilisateur Windows ayant déjà ouvert une fois avec succès une session avec SQL Server grâce au login du groupe Windows dont il est membre, peut continuer à accéder à la même instance SQL Server après que l’administrateur l’a exclu du groupe Windows auquel il appartenait.
Utiliser « Police Based Management» et SQL Server BPA
Le « Policy Based Management » et le SQL Server BPA (Best Practices Analyzer) peuvent être d’une aide précieuse pour appliquer et renforcer les différentes bonnes pratiques recommandées.
Pour plus d’informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d’informations sur les blogs « SQL Server chez les clients ».
 |
Xiaozhao Li, Consultant SQL Server, Microsoft Consulting Services J’ai rejoint MCS en 1999, d’abord en tant que consultant en développement et architecture applicative. Je me suis ensuite spécialisé en SQL Server pour accompagner nos clients dans la conception, la mise en œuvre et l’optimisation des bases de données critiques.
|