SQL Server chez les clients – Conception de packages SSIS de chargement de données – Les bonnes pratiques

SQL Server Integration Services (SSIS) est une plateforme, incluse dans la suite SQL Server, permettant de créer des solutions d’ETL (Extract Transform Load) appelées Packages.
Quelques heures de formation peuvent permettre à un informaticien d‘avoir la connaissance suffisante pour concevoir des packages SSIS. Cependant, si cette conception n’est pas faite dans le respect d’un certain nombre de bonnes pratiques, les packages SSIS peuvent être longs à s’exécuter et rapidement devenir difficile à maintenir et à faire évoluer.
L’objectif de cet article est d’énumérer les plus importantes de ces bonnes pratiques.
Problématique
- Utiliser les composants SSIS les plus adaptés en fonction du besoin
- Configurer les propriétés d’un composant SSIS pour optimiser son exécution
- Concevoir des packages performants, tant au niveau de la durée d’exécution que de la sollicitation des ressources
Bénéfices
- Des packages SSIS qui s’exécutent de manière optimale
- Une lecture facilitée de la structure du package et de son fonctionnement
Les packages SSIS sont constitués de Control Flows (Flux de contrôle) qui incluent une ou plusieurs séquence(s) de différentes tâches et Data Flows (Flux de données).
Ces Control Flows permettent de piloter la logique d’exécution des tâches d’un package SSIS.
Les Data Flows sont généralement constitués de :
- Une ou plusieurs source(s) de données
- Eventuellement, une ou plusieurs transformation(s)
- Une ou plusieurs destination(s)
La conception d’un package SSIS consiste en l’utilisation des différents éléments des Control Flows et des Data Flows, selon un ordre logique et en l’adaptation de chacun de ces éléments au besoin de l’alimentation.
Nommage des éléments du package
Il est impératif de renommer systématiquement et de manière unique tous les éléments du package SSIS (Control Flows, Data Flows et composants) au fur et à mesure de leur conception.
Ceci facilitera non seulement la compréhension des packages et l’identification des flux mais aussi la lecture des rapports de journalisation d’exécution de SSIS.
Ajouter des notations et des commentaires
Il est impératif d’ajouter des commentaires au package, décrivant ses différentes étapes ainsi que la logique de leur enchaînement afin de permettre plus facilement à d’autres intervenants la compréhension de ce qui a été mis en place et la reprise de l’existant.
Ctrl+Enter permet un retour à la ligne dans un commentaire.
Renommer les colonnes sources comme les colonnes de destination
Il est recommandé de renommer les colonnes de la source comme les colonnes de la destination et de garder le même nommage tout au long du package afin de faciliter le suivi des modifications et de permettre une correspondance automatique avec les colonnes de destination.
Restreindre les données sources à celles qui sont nécessaires
Très souvent, toutes les données contenues dans les sources de données utilisées ne sont pas nécessaires à l’alimentation. Il est recommandé de ne récupérer que les données sources nécessaires et ce, en utilisant des requêtes spécifiant les noms des colonnes à récupérer au lieu de se contenter d’un « Select * » sur une table ou une vue.
Utilisation de la connexion MULTIFLATFILE
Il est recommandé d’utiliser une connexion MULTIFLATFILE lors du chargement de plusieurs fichiers plats ayant le même format.
Déclarer les colonnes à ignorer à l'aide d'une source Flat File en String
Il est recommandé de déclarer les colonnes non nécessaires d’une source Flat File en String (Non-Unicode) plutôt que leur type d'origine. Cela permet une analyse plus rapide des colonnes du fichier.
Activer la propriété "FastParse" des colonnes source d'un Flat File
Il est recommandé de sélectionner la valeur « True » de la propriété « FastParse » des colonnes sources d’un Flat File. Pour les formats Date et Float, cette propriété utilise un nombre de formats prédéfinis incluant les formats ISO.

Effectuer les conversions de types Non-Unicode en Unicode au niveau de la source de données
Il est recommandé d’effectuer les conversions de type Non-Unicode en Unicode dès le départ au niveau de la source de données, quand cela est possible, plutôt que d’utiliser les composants « Data Conversion » ou « Derived Column » pour le faire par la suite.
Appliquer les filtres les tris, les jointures et les transformations au niveau de la source de données
Il est recommandé de s’appuyer sur la puissance du moteur SQL Server pour réaliser certaines opérations complexes telles que les jointures en tables et/ou vues.
Il est recommandé de filtrer les données lors de leur extraction via le composant Source de données en utilisant la commande « WHERE ». Cela réduit les données à traiter et élimine dès le départ les données inutiles.
Il est également recommandé d’effectuer les tris, tant que possible, au niveau de la source de données en utilisant la commande « ORDER BY » et de limiter tant que possible l’utilisation du composant « SORT » de SSIS.
D’autre part, il est recommandé privilégier les commandes SQL au niveau de la source, telles que Replace, NULL, IsNull, RTRIM, LTRIM, les Concaténation et les Jointures, plutôt que l’utilisation des composants SSIS.
Ajuster la taille des données en zone tampon (BufferSize)
DefaultBufferSize est utilisé pour limiter la taille des données en zone tampon. Sa valeur par défaut est de 10 MB.
DefaultBufferMaxRows permet le stockage d’un nombre maximal défini de lignes dans la zone tampon.
Augmenter ces valeurs peut booster les performances en permettant le stockage de davantage de données en zone tampon.
Limiter les données sélectionnées dans les Lookups
De même que pour les sources de données, il est recommandé de ne récupérer que les données nécessaires dans le composant « Lookup ». Et ce, en selectionnant les données grâce à une requête SQL plutôt que de sélectionner la table ou la vue puis de décocher les colonnes non nécessaires.
Adapter la mise en cache au niveau des Lookups
Il est recommandé de sélectionner le :
- « Full Cache » pour de petits datasets répétitifs
- « No Cache » pour des datasets volatiles
- « Partial Cache » pour des datasets volumineux avec des clés lookup dupliquées.
Utilisation des composants « Raw File Source » et « Raw File Destination »
L’utilisation des composants « Raw File Source » et « Raw File Destination » (dossiers contenant des données non encryptées et non compressées), est l’un des moyens les plus rapides de charger et de transférer des données.
Ces composants sont généralement utilisés lorsque les données sources du package sont les données résultantes d’un autre package.
Définir la valeur de la propriété « PreCompile » du composant « Script Component »
La propriété « PreCompile » du composant « Script Component » permet, lorsque sa valeur est à « True », un démarrage plus rapide de la tâche. Cependant, ceci augmente la taille du package.

Limiter l’utilisation du composant « Multicast »
Il est recommandé de limiter l’utilisation du composant « Multicast ». En effet, ce composant cause une consommation supplémentaire de mémoire étant donné qu’il génère une duplication des flux de données et cause une copie des données dans un nouveau buffer.
Eviter les transformations complexes et combinées
Il est recommandé, tant que possible, de privilégier la décomposition des transformations en plusieurs transformations simples à la suite les unes des autres plutôt que de les combiner pour en faire une seule transformation complexedont les tâches deviennent consommatrices de mémoire lorsqu’elles sont exécutées.
Optimiser le découpage des packages SSIS
Il est recommandé, tant que possible, de découper les packages SSIS de façon à avoir plusieurs packages plus simples plutôt qu’un seul package très complexe et/ou lourd.
Utilisation de la destination « SQL Server Destination »
Il est recommandé de privilégier la destination « SQL Server Destination » plutôt que la destination « OLE DB Destination » lorsque le package SSIS et la base SQL de destination sont sur le même serveur.
Déployez vos projets dans le Catalogue SSIS
Depuis la version SQL Server 2012, il est possible de déployer les solutions SSIS non plus seulement au niveau package mais aussi au niveau « Projet ».
Ceci permet :
- de gérer les connexions au niveau projet de manière mutualisée pour l’ensemble des packages du dit projet.
- l’utilisation de « Paramètres » d’exécution des packages ont les valeurs configurées ou calculées à un niveau parent, peuvent être passés au(x) niveau(x) enfant(s).
- une coordination simplifiée des appels inter-packages.
Le catalogue SSISDB permet non seulement le stockage des packages SSIS mais aussi leur paramétrage, leur configuration, leur exécution et le stockage de toutes les informations de suivi et de log.
Ce nouveau type de déploiement se fait à travers une nouvelle base système SQL server qui offre de nombreuses fonctionnalités natives :
- Enregistrement des configurations (paramètres, connections…) en base lors du déploiement ou à posteriori avec des scripts SQL
- Notion « d’environnements » qui sont des collections de configuration pour cibler différentes plateformes
- Version des packages déployés avec possibilités d’un retour arrière
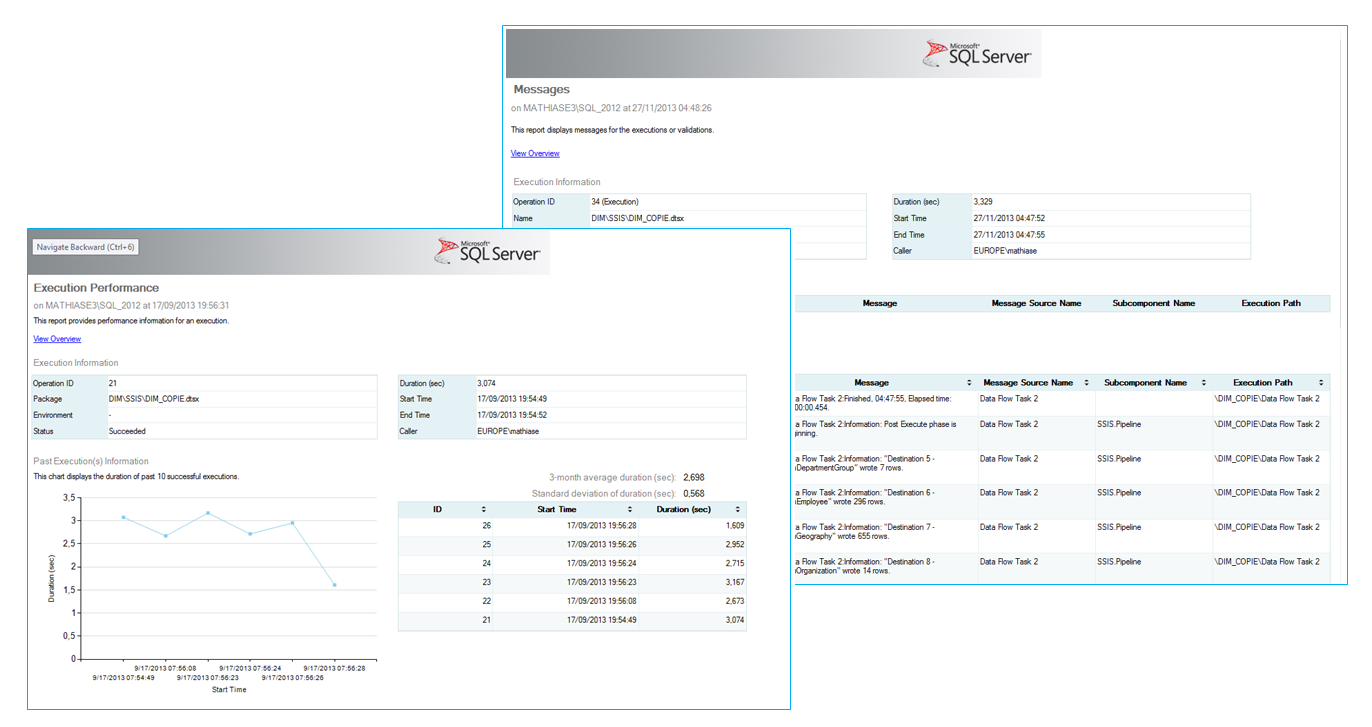
- Rapports de monitoring très détaillés sur les exécutions de package permettant à la fois un suivi en temps réel de l’exécution, et une tendance sur l’évolution des performances de l’exécution du package
L’expertise Microsoft Consulting Services au service de ses clients
MCS propose une offre de service packagée pour la conception de packages SSIS de chargement de données optimisés sur des plateformes et solutions SQL Server & MSBI. Les packages SSIS conçus selon les bonnes pratiques ont été éprouvés et ont prouvé leur efficacité à travers de nombreux projets chez des clients grands comptes :
- Grandes banques d’investissement
- Leaders mondiaux de l’industrie cosmétique
- Acteurs majeurs de l’industrie automobile
- Acteurs majeurs du transport d’énergie
- Et bien d’autres …
Cette offre de service peut aussi bien être mise en œuvre dans le cadre d’un projet géré par Microsoft Services, que dans le cadre d’une assistance technique sur certains aspects du projet (architecture, validation…).
Pour plus d’information sur SQL Server Integration Services, rendez-vous sur https://technet.microsoft.com/fr-fr/library/ms141026.aspx
https://msdn.microsoft.com/en-us/library/jj873729.aspx
https://msdn.microsoft.com/en-us/library/hh667275.aspx
Pour plus d’information sur le catalogue SSISDB rendez-vous sur https://technet.microsoft.com/fr-fr/library/hh479588.aspx
Pour plus d’informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d’informations sur les blogs « SQL Server chez les clients ».
 |
Manon B., Consultante BI/SQL, Microsoft Consulting Services Je suis consultante BI depuis 2007, principalement sur les technologies Microsoft BI. J’interviens chez des clients, en tant que leader technique. Je participe également à des missions de cadrage et d’avant-vente. Je suis spécialisée en intégration des données, gestion de la qualité des données et reporting. |