Die Menschen hinter den Produkten, Teil 4: Sunil Agarwal, PM SQL Server Storage Engine
Der nächste in meiner Serie ist Sunil Agarwal, PM in der SQL Server Storage Engine Gruppe und in SQL Server 2008 vor allem für das Thema Datenkomprimierung zuständig. Daneben sprechen wir über Backup und Prüfsummen.
 Hallo Sunil. Du bist Program Manager in der SQL Server Storage Engine. Was ist das? Was ist die Storage Engine? Beschäftigst Du Dich mit SANs oder so?
Hallo Sunil. Du bist Program Manager in der SQL Server Storage Engine. Was ist das? Was ist die Storage Engine? Beschäftigst Du Dich mit SANs oder so?
Die Storage Engine ist ein riesiges Gebiet. Das beinhaltet Transaktionen, Parallelität, wie Daten gespeichert werden, SQLOS, viele Gebiete. Im Storage Engine Team haben wir etwa 10 Program Manager. Mein Arbeitsgebiet ist Parallelität (concurrency), Speicherstrukturen – dazu gehört zum Beispiel Datenkomprimierung. Dann beschäftige ich mich mit Bulk Import und Export, LOB Daten und Troubleshooting.
Du bist also ein klassischer Feature PM, beschäftigst Dich also mit allem bei einem Feature von „Was wollen wir tun?“ bis es im Produkt erscheint?
Das stimmt. Die meisten PMs bei uns sind Feature PMs. Als PM beginnt man bei einer Anforderung. Um die wichtigen Fragen zu bekommen sprechen wir mit MVPs, gehen zu Konferenzen, besuchen Kunden, schauen und sie Newsgroups an und natürlich vor allem die Verbesserungsvorschläge auf connect. Daraus machen wir dann Features oder Szenarios. Nehmen wir ein Szenario: Disaster Recovery. Die Anforderung ist, Disaster Recovery so problemlos wie möglich zu machen. Um das zu erreichen definieren wir mögliche Features oder Improvements. Dann wird entschieden welche Improvements implementiert werden und wir als Program Manager sind dafür verantwortlich, sie von Anfang bis Ende umzusetzen.
Wie wird entschieden, ob ein Feature in ein Produkt kommt oder nicht?
Im Optimalfall wäre es so, dass ich wüsste: Wenn ich dieses Feature im Produkt hätte, wie viel Kundenzufriedenheit und wie viel Umsatz gewinne ich damit? Dazu br äuchte ich wohl eine magische Glaskugel. Da wir die nicht haben entscheiden wir auf der Basis der Teams: Welche Szenarien sind nützlich und innerhalb der Szenarien, welche Features sind nützlich? Und welche Kundenprobleme löst das? Es ist also teilweise objektiv, teilweise subjektiv.
Wenn Du an die Storage Engine denkst, gibt es da Dinge, die die Kunden nicht wissen? So eine Art versteckte Perlen?
Davon gab es viele. Undokumentierte DBCC-Kommandos, Trace Flags. Aber wir haben das Ziel, all diese Sachen in Books Online zu dokumentieren wenn sie nützlich sind. Und wenn es da nicht steht dann beschreiben wir das in unseren Blogs. Wir wollen also diese schwarze Magie soweit wie möglich beseitigen.
Für die dokumentierten Features möchte ich vor allem auf den Best Practices Analyzer (BPA) hinweisen. Dieses Tool schaut sich eine Konfiguration entsprechend der von uns veröffentlichen Best Practices an, z.B. dass Log und Daten auf unterschiedlichen Platten sind. Dieses Tool wird immer weiter ergänzt.
Und wir haben viele Best Practices Dokumente, die vor allem auf der SQLCAT Seite stehen. Wenn wir also aus dem Support erfahren, dass für uns bestimmte Dinge völlig klar sind, für die Kunden aber nicht, dann versuchen wir, ein Best Practices Dokument dazu zu erstellen.
Hast Du aus diesem Bereich ein häufiges Problem, mit dem sich Kunden konfrontiert sehen?
Ich kann das jetzt nur aus dem Storage Engine Bereich beurteilen. Eine Sache, die mich immer wieder erstaunt ist, dass die Kunden Backups nicht ernst genug nehmen. Das basiert auf Daten von Anrufen von Kunden beim Support (CSS). Wenn die Datenbank aus welchem Grund auch immer, korrupt ist, meist ist Hardware der Grund, und der Kunde sagt: Meine Anwendung läuft nicht mehr, was soll ich tun? Dann sagt der Support: Gehen wir erst mal auf ein Backup zurück. Dann ist es oft so, das kein Backup da ist, oder nicht das richtige, oder es wurde nie DBCC ausgeführt um zu schauen, ob die Datenbank überhaupt konsistent ist.
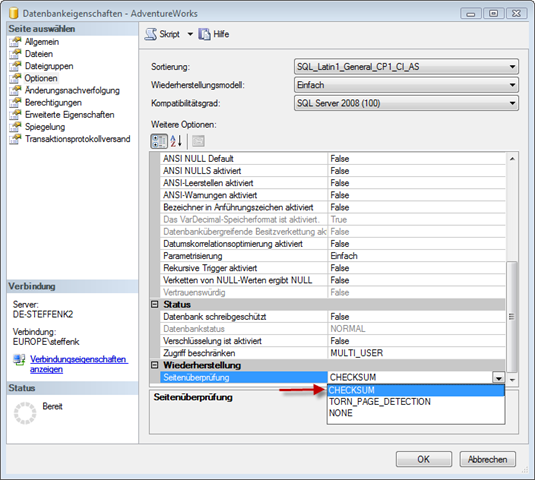
Etwas anderes, was mich überrascht ist, dass so wenige Kunden Prüfsummen verwenden.
Du meinst Seitenprüfsummen (page checksums), wie es sie seit SQL Server 2005 gibt.
Genau. Wenn eine Seite aus dem SQL Server Bufferpool auf die Platte geschrieben wird, dann wird eine Prüfsumme erzeugt und in die Datenseite geschrieben. Wenn die Seite dann wieder gelesen wird, dann wird dieser Wert erneut berechnet und mit dem gespeicherten Wert verglichen. Wenn diese Werte nicht übereinstimmen dann stimmt etwas an meinem IO Subsystem nicht. Man erkennt also sofort das Problem statt viel später, wenn es vielleicht schon zu spät ist. Und für uns ist das ein klares Zeichen, dass der Fehler im IO Codepfad zu suchen ist und nicht in SQL Server. Das sollten die Kunden benutzen, und meines Wissens überprüft der Best Practices Analyzer diese Einstellung auch.
Du warst auch für das Feature Datenkomprimierung in SQL Server 2008 zuständig. Dieses Feature wurde insbesondere für Data Warehouses entwickelt. Aber jetzt wollen viele Kunden es auch in OLTP-Szenarien einsetzen. Glaubst Du, es ist eine gute Idee, Datenkomprimierung nicht nur für Data Warehouses, sondern auch für OLTP zu benutzen?
Die Antwort ist ja, und lass mich das ein wenig erklären. Als wir mit Datenkomprimierung angefangen haben war das Ziel Data Warehouse, weil Data Warehouses nun mal viele Zahlen enthalten. Während des Designs dieses Features haben wir erkannt, dass wir zwei Ebenen der Komprimierung anbieten müssen. Die eine Ebene ist ´für die Spalten fester Breite: Integer, Float, Money und sowas. Wir wollten eine effizientere Speicherung für diese Datentypen und damit geringeren Platzbedarf erreichen. Wenn man sich nun OLTP Workloads anschaut, dann besten sie aus vielen Updates, Deletes und Reads. Mit Zeilenkomprimierung (row compression) können wir Updates, Deletes und Reads ein Stück billiger machen als mit voller Komprimierung (Seitenkomprimierung, page compression). Nach unseren Erfahrungen erfordert Zeilenkomprimierung für OLTP Workloads weniger als 10% CPU-Overhead, aber man kann rund 20-30% Plattenplatz und IO einsparen. Wir empfehlen also Zeilenkomprimierung für OLTP. Performancevergleiche zeigen, dass die Performance vergleichbar ist. Wenn man sich übrigens das Standard-Datenformat von Oracle anschaut dann funktioniert das wie unsere Zeilenkomprimierung. Oracle speichert alle Spalten als Länge + Wert. Wenn man also einen Integer, der normalerweise 4 Byte braucht, mit dem Wert 1 speichert dann ist das eine Länge von 1 und dann ein Byte. Mit Zeilenkomprimierung machen wir fast dasselbe, aber wir sind der Meinung dass unsere Zeilenkomprimierung ein besseres Storage-Format bietet als das was Oracle tut. Für Data Warehouses empfehlen wir die volle Seitenkomprimierung. Wir haben auch schon Kunden gesehen, die für OLTP-Workloads Seitenkomprimierung einsetzen, aber das ist nur in besonderen Fällen sinnvoll.
Jetzt etwas persönliches: Wie bist Du hierher gekommen?
Ich arbeite schon seit langem im Datenbank-Bereich. Ich habe für Digital Equipment Corporation (DEC) in Colorado als Entwickler im Datenbankbereich gearbeitet. Von dort bin ich zu Sybase gegangen. Dort habe ich 5 Jahre in der Storage Engine Group gearbeitet. Nachdem ich also 10-15 Jahre im Datenbankbereich gearbeitet habe wollte ich auf die Anwendungs-Seite. Datenbanken waren für mich zu weit unten, und ich wollte sehen, wie die Datenbanken verwendet werden. Damals war gerade der Internet-Boom, es waren die späten 90er Jahre, und ich habe nacheinander bei drei Startup-Firmen je 2 Jahre in der Anwendungsentwicklung gearbeitet. Alle drei Startups sind fehlgeschlagen. Aber ich habe Anwendungsentwicklung gelernt. Dann wollte ich zu den Datenbanken zurück, und Sybase ging es damals nicht allzu gut. Und ich wollte sowohl viel mit Kunden als auch mit der Entwicklung zu tun haben. Daher habe ich mich als Program Manager beworben, und hier bin ich.
Danke, Sunil