Доступ к данным в memory optimized таблицах
Мы продолжаем изучение новых возможностей SQL Server 2014 в части In-memory database.
Сегодня мы рассмотрим методы доступа к объектам In-memory базы данных.
Доступ к таблицам In-memory базы данных может быть осуществлен:
- Используя Natively compiled хранимых процедур – наиболее быстрый способ доступа к данным;
- Используя стандартный T-SQL;
Особенности Natively compiled хранимых процедур:
- Код хранимой процедуры, написанный на T-SQL, преобразуются в код на языке “С” и далее в объектный код, и dll;
- Код компилируются один раз при создании и далее перекомпилируются при рестарте сервера и более ни при каких условиях.
- Результат компиляции (алгоритм и код) зависит от среды существовавшей при компиляции (в том числе от статистики);
- Объекты, на который ссылается такая хранимая процедура, не могут быть изменены DDL операторами.
Особенности доступа к In-memory таблицам через T-SQL (Этот метод доступа еще называется Inter-Op или Interpreted TSQL access):
- Этот метод доступа снимает ряд ограничений которые присутствуют в Natively Compiled хранимых процедурах:
- Truncate table
- MERGE используя Memory-optimized table как целевые
- Dynamic и keyset cursors;
- Cross database запросы или транзакции;
- Связанные сервера;
- Блокировочные подсказки (hints).
- Как правило использование T-SQL предназначено для выполнения:
- Ad hoc запросов и административных задач;
- Запросов для построения отчетов;
- Одиночных DML операторов (SELECT, UPDATE, INSERT);
- Первого шага к миграции из стандартной в In-Memory базу данных.
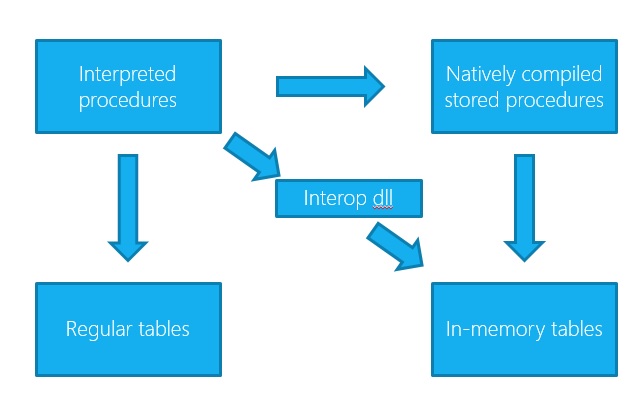
Как видно из рисунка, приведенного ниже, возможно получить доступ к In-memory таблицам из T-SQL кода, а вот из Native compiled хранимых процедур получить доступ к регулярным таблицам не возможно. Связано это с тем, что структура таблиц прописывается в код Native compiled хранимых процедур на этапе их создания и более не может меняться.
Исполнение Native-compiled хранимых процедур имеет ряд особенностей которые должны учитываться при проектировании систем, а именно:
- Актуальный план выполнения Native-compiled хранимой процедуры не отображается никакими средствами.
- Статистика выполнения Native-compiled хранимых процедур не выводится через SET STATISTICS IO поскольку In-memory таблицы имеют построчную, а не постраничную организацию.
- При выполнении Native-compiled хранимых процедур не используется параллелизм.
- Для соединения таблиц используется только алгоритм NESTED LOOP.
- Компиляция Native-compiled хранимой процедуры может выполняться достаточно долго, поэтому, по возможности, не создавайте их динамически (по ходу выполнения).
- DBCC freeproccache и DBCC freesystemcache не могут использоваться для очистки процедурного кэша Native-compiled хранимых процедур.
- Для контроля объемов памяти, используемой для хранения необходимо применять sys.dm_os_memory_object с группировкой по объекту MEMOBJ_XTPPROCCACHE.
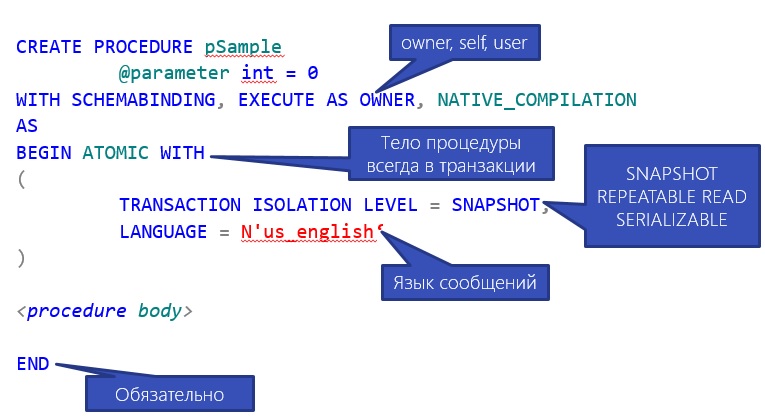
Ниже приведен пример синтаксиса, такой процедуры.
Обратите внимание на некоторые особенности синтаксиса:
- EXECUTE AS есть только три варианта OWNER, SELF, USER;
- Тело всегда начинается с BEGIN ATOMIC WITH;
- TRANSACTION ISOLATION LEVEL может быть только SNAPSHOT, REPETABLE READ, SERIALIZABLE.
Мониторинг Native Compiled хранимых процедур имеет также некоторые особенности:
- Статистика выполнения не выводится через SET STATISTICS IO.
- Можно использовать SET STATISTICS TIME.
- sys.dm_exec_query_stats и sys.dm_exec_procedure_stats, по-умолчанию не содержат статистки, разрешение сбора статистики производится путем включения ее сбора через sp_xtp_control_proc_exec_stats и sp_xtp_control_query_exec_stats.
- Выполнение Native Compiled хранимых процедур не генерирует Xevent-событие sp_statement_starting, а только событие sp_statement_completed.
- Счетчики Performance Monitor с расширением XTP
- Все XEvent события для Native Compiled хранимых процедур относятся к каналам “Analytic” и “Debug”.
В следующем блоге мы рассмотри процедуру компиляции объектов в In-Memory базах данных.
Александр Каленик, Senior Premier Field Engineer (PFE), MSFT (Russia)