Основы построения In-Memory СУБД SQL Server 2014. Bw-tree индексы.
В предыдущих блогах мы рассмотрели основы построения In-Memory баз данных. См. https://blogs.technet.com/b/sqlruteam/archive/2014/03/28/sql2014_5f00_memory_5f00_optimized_5f00_rdbms_5f00_overview_5f00_physical_5f00_structure.aspx, https://blogs.technet.com/b/sqlruteam/archive/2014/04/03/sql2014_5f00_memory_5f00_optimized_5f00_rdbms_5f00_overview_5f00_hash_5f00_indexes.aspx.
Из предыдущего блога стало понятно, что в In-Memory базах данных используется другой класс индексов. Это hash-индексы. Hash-индексы играют важную роль в работе этого типа баз. В отличии от стандартных баз (On-Disk), где возможно существование таблицы в формате "куча" (heap), при этом страницы, принадлежащие одной таблице, связаны вместе с использованием специальных структур (IAM), таблицы, оптимизированные для выполнения в памяти (Memory optimized table), не могут быть созданы без наличия хотя бы одного hash-индекса.
Однако у hash-индексов есть серьезный недостаток. Они не могут использоваться для поиска по диапазону значений. Для устранения этого недостатка в таблицах используются Bw-tree индексы.
BW-tree индексы. Это еще зачем?
Как вы знаете в классических (On-Disk) OLTP базах используются B-tree индексы. Их структура представляют собой сбалансированное N-дерево (отсюда "B", что значит balanced). О достоинствах такого подхода написано много и нет смысла это повторять, однако...
Однако такие индексы имеют и серьёзные недостатки, которые стали особенно заметны при росте нагрузки на систему и увеличении количества процессоров.
Основные недостатки B-tree индексов:
- Наложение блокировок (Lock) и защелок (Latch).
- Необходимость балансировки дерева, а отсюда наложение Latch-ей
- Деление страниц связанной с фиксированным размером страниц и опять же, связанное с этим наложение Latch-ей.
Как понятно из вышеприведенных рассуждений - основная проблема, существующей индексной системы это наличие "защелок" (Latches) без которых невозможно обойтись в много задачных и многопроцессорных системах. Для устранения этого в новой системе реализован метод неблокирующих модификаций, основанный на добавлении дельта-записей к существующим записям при выполнении их модификаций. Т.е. система никогда не производит in-place обновления, а все операции обновлений реализуются путем добавления новой дельта-записи. При таком подходе производится только краткосрочная блокировка ячейки памяти, где храниться ссылка на обновленную запись, чтобы перенаправить эту ссылку в новое местоположение.
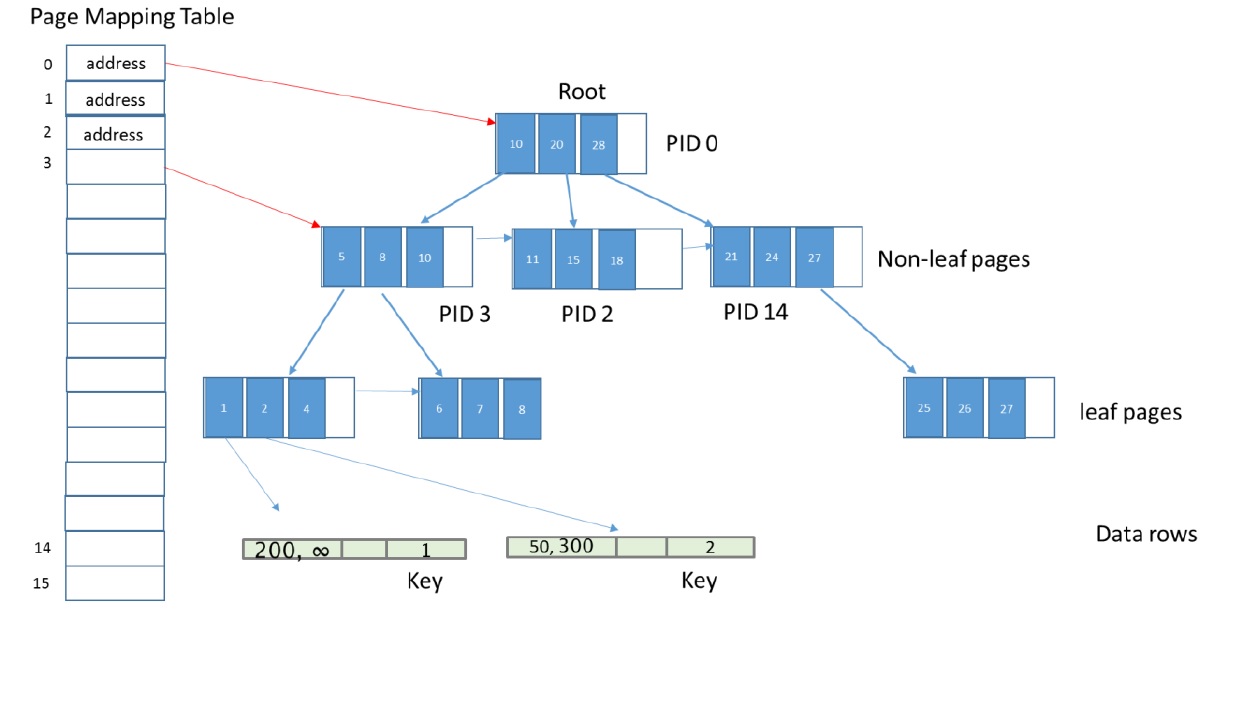
Давайте посмотрим на структуру Bw-tree дерева.
Внешне оно не отличается от стандартного B-tree дерева, но это только внешне.
Первое отличие состоит в том, что адреса индексных страниц это не номера страниц, как в стандартной (On-Disk) базе данных, а адрес ячеек памяти, где реально размещена эта страница. Т.о. страница не должна быть размещена в фиксированном месте определяемом ее номером (file:page). При таком подходе отсутствует необходимость перемещения страницы при ее делении и нет фрагментации, поскольку страницы в памяти никак не связаны с дисковыми страницами. Связь между номером страницы и ее адресом производится через Page Mapping Table (Таблица привязки страниц).
Второе отличие состоит в том, что в данной структуре размеры страниц индексов не фиксированы (elastic pages) и система сама принимает решение о необходимости деления или слияния страниц. В случае деления страницы происходит ее добавление к существующей цепочке страниц и модификация адресных ссылок. Такая операция может быть выполнена очень быстро и практически без блокировки данных.
Третье отличие - страницы литьевого уровня всегда ссылаются на строки (как в некластерном индексе).
Четвертое отличие - модификация данных. Она всегда выполняется без блокировки модифицируемой строки путем добавления дельта записи к существующей строке.
Давайте рассмотрим принцип модификации данных в дереве Bw-tree индекса.
Предположим мы хотим вставить новую строку в дерево индекса. По своему содержимому эта строка должна быть вставлена в страницу P. Адрес страницы P хранится в Page Mapping Table (PMT). При вставке строки к странице P добавляется новая дельта-строка (Insert record 50) и в Page Mapping Table переписывается ссылка на эту строку, а из нее на страницу. При удалении строки происходит тоже самое. Со временем таких строк станет достаточно много и СУБД примет решение о слиянии строк со страницей.
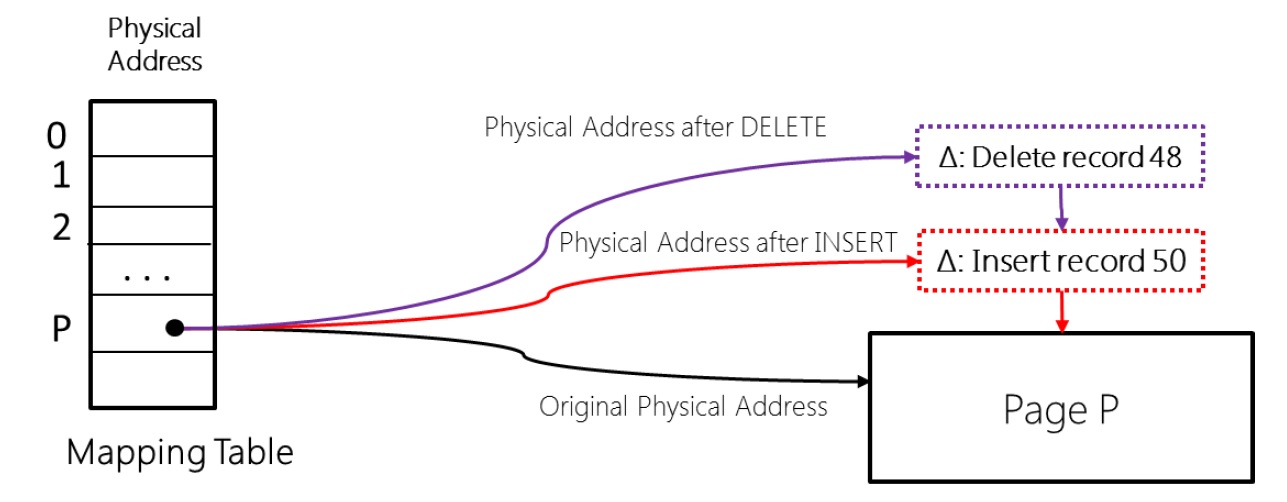
Добавление новых строк производится методом Compare and swap (См. https://en.wikipedia.org/wiki/Compare-and-swap). Суть метода состоит в том, что атомарно производится модификация ячейки памяти, где содержится указатель на модифицируемую страницу, и в эту ячейку записывается адрес дельта строки. Поскольку такая операция выполняется очень быстро, то вероятность конфликта очень мала, но если конфликт за ячейку памяти возникает, то он обрабатывается СУБД.
Как указывалось выше новая СУБД использует страницы индексов переменных размеров. Для уменьшения количества переключений между дельта записями СУБД периодически выполняет консолидацию страниц. Суть консолидации состоит в слиянии всех строк, которые были вставлены (модифицированы) и удалении строк, которые были удалены. Данная операция выполняется путем создания новой страницы, копирования в нее всех данных и переключения указателя в PMT на новый адрес.
Такое архитектура индексов (latch-free) предполагает наличие некоего механизма удаления неиспользуемых страниц. Такой механизм создан и называется Garbage Collection. Задача этого механизма - производить сканирование страниц и очистка неиспользуемых участков памяти.
Поскольку данный тип индекса преимущественно ориентирован на выборку по диапазону значений, то для выполнения этой операции разработаны алгоритмы обеспечивающие непротиворечивость операций выборки при модификации данных.
Предположим мы выполняем запрос по диапазону значений, по которому построен индекс.
SELECT * FROM t1 WHERE NAME BETWEEN 'Alex' and 'Bob'
- Запоминается момент времени начала транзакции выборки данных.
- Выполняется проход по дереву индексов с целью формирования вектора ссылок для выборки данных.
- После сканирования и формирования вектора определяется не произошло ли каких-либо изменений, которые могут изменить вектор.
- Если произошли, то выполняется обновление вектора.
- Если нет, то производится считывание данных соответствующих критерию выборки и временной метке начала транзакции. (См. )https://blogs.technet.com/b/sqlruteam/archive/2014/03/28/sql2014_5f00_memory_5f00_optimized_5f00_rdbms_5f00_overview_5f00_physical_5f00_structure.aspx.
В цикле блогов мы рассмотрели основные принципы построения новой СУБД (In-Memory Database). Далее мы начнем рассмотрение работы с этой частью SQL Server.
Александр Каленик, Senior Premier Field Engineer (PFE), MSFT (Russia)