Tuning Enovia SmarTeam – Indexes – Part 1
[Prior Post in Series] [Next Post in Series]
Adding indexes helps SQL Server retrieve records in a table faster. There is a special type of index called ‘clustered’; a clustered index determines the physical order of the records on the disk. For the most common reads, you want the records to be adjacent to each other so they are read fast and do not have to wait for the physical disk heads to move or for the next rotation of the spindle.
This post looks at the results of the first Database Engine Tuning Advisor (DTA) results and extracts one pattern of indexes from it. My criteria for tuning are usually:
- Add no more than one index per table on each pass
- Add the most common index pattern from DTA
- If there is no clustered index on the table, you should add a clustered index.
This approach usually produces a good first pass and will often reduce the ‘noise’ of index recommendations returned by DTA.
Getting the list of recommended index columns
As cited in the introduction, I use the XML results file. Everything that I do with XML may be done manually be reading the two other formats. The XML approach is more accurate and faster.
For each of my saved XML files some simple modifications make the TSQL simpler to write.
- Delete:
- <?xml version="1.0" encoding="utf-16"?>
- Change:
- <DTAXML xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xmlns="https://schemas.microsoft.com/sqlserver/2004/07/dta">
- To
- <DTAXML>
This removes complexities with XML namespaces from the TSQL below.
Clustered Indexes
My first step is to look at any recommendations for clustered indexes and which columns are involved. This is done by this little snippet of code.
DECLARE @Xml Xml
Set @Xml='{paste here}'
Select ColName,Count(1) FROM
(SELECT node.value('(.)[1]','sysname') as ColName
FROM @Xml.nodes('//Index[@Clustered="true"]/Column')
as Ref(node)) DTA
GROUP BY ColName
ORDER BY COUNT(1) DESC
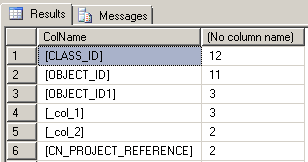
The results shown below display two dominant columns, [CLASS_ID] and [OBJECT_ID]
{kind=link}
So the question is, how often do [CLASS_ID] and [OBJECT_ID] occur in the same index? This can be obtained by a simple join as shown in this snippet of code:
DECLARE @Xml Xml
Set @Xml='{paste here}'
SELECT A.IndexName,Cluster FROM
(SELECT
node.value('(parent::*/Name)[1]','sysname') as IndexName,
node.value('parent::Index/@Clustered','sysname') as Cluster
FROM @Xml.nodes('//Index/Column')
as Ref(node)
WHERE node.value('(.)[1]','sysname')='[OBJECT_ID]')
A
JOIN
(SELECT
node.value('(parent::*/Name)[1]','sysname') as IndexName
FROM @Xml.nodes('//Index/Column')
as Ref(node)
WHERE node.value('(.)[1]','sysname')='[CLASS_ID]')B
ON A.IndexName=B.IndexName
ORDER BY Cluster DESC,A.IndexName
This produced 28 rows, an example is shown below:

Finding 28 indexes listed from a total of 67 recommended indexes is a 42% hit ratio.
Next I did a reasonableness analysis, which I will not recite. My conclusion was to create a clustered index on ( [OBJECT_ID], [CLASS_ID] ) for every table. I scanned the recommendations to see which was the most common recommendation:
[OBJECT_ID], [CLASS_ID], or
- [CLASS_ID], [OBJECT_ID]
And ([OBJECT_ID], [CLASS_ID]) was the most common.
Since I do not know what tables exist in your installation (because of customization), I wrote code that queries the tables and their columns and then dynamically builds the indexes that apply The SET @CMD= below shows the TSQL pattern produced.
SET NOCOUNT ON
DECLARE @CMD nvarchar(max)
DECLARE @Schema nvarchar(max)
DECLARE @Table nvarchar(max)
DECLARE PK_Cursor CURSOR FOR
Select o.Table_Schema, O.Table_Name
FROM Information_Schema.Columns O
JOIN Information_Schema.Columns C
ON O.Table_Name=C.Table_Name
AND O.Table_Schema=C.Table_Schema
JOIN Information_Schema.Tables T
ON O.Table_Name=T.Table_Name
AND O.Table_Schema=T.Table_Schema
WHERE O.Column_Name='Object_ID'
AND C.Column_Name='Class_ID'
AND T.Table_Type='BASE TABLE'
ORDER BY T.Table_Name
OPEN PK_Cursor;
FETCH NEXT FROM PK_Cursor INTO @Schema,@Table
WHILE @@FETCH_STATUS = 0
BEGIN
SET @CMD='CREATE /*UNIQUE*/ CLUSTERED INDEX [PK_'+@TABLE +'] ON ['+@Schema+'].['+@Table+']([Object_ID] ASC,[Class_ID] ASC)'
IF NOT EXISTS(SELECT 1 FROM sys.indexes WHERE Name='PK_'+@Table)
BEGIN TRY
EXEC (@CMD)
END TRY
BEGIN CATCH
SET @CMD='Error: '+@CMD
Print @CMD
END CATCH
FETCH NEXT FROM PK_Cursor INTO @Schema,@Table
END;
CLOSE PK_Cursor;
DEALLOCATE PK_Cursor;
CAVAETS
The following are items that I explored but excluded from the final TSQL shown above:
- Checking if a clustered index already existed – I found none, so I omitted that qualification from the Cursor’s Select
- Checking if unique would work – it did. All indexes built with no exceptions. I excluded it because:
- Checking for uniqueness consumes additional resources.
- If a non-unique situation can arise legitimately, it would likely cause an obtuse error to occur in the application that could be difficult to resolve. UNIQUE is what ISV’s development staff should add, not clients.
Summary
The above is the rough analysis that I did to add the first pattern of indexes. The pattern was:
- add a clustered index on every table that had ([OBJECT_ID], [CLASS_ID])
After applying this to the database, I executed DTA again and found that the number of indexes recommended dropped from 67 to 15 and the performance improvement possible dropped by 16%. This is a good result.
Post Script: The Math of Tuning
We had 67 recommendations and did a pattern based on 28 recommendations. We would expect 67-28 = 39 recommendations on the next tuning. We did not, we had just 15. This may be a surprise to you. Correlation and interactions between indexes and the query engine are complex – hence my habit of adding one index pattern at a time.