Identificando cálculos en modo Cell by Cell en consultas MDX
Hace algunas semanas me pidieron apoyo con un problema de desempeño en algunas consultas MDX.
Me mostraron lo que el cliente quería lograr, ellos necesitaban calcular algunas métricas incluyendo errores de muestra utilizando el método “Conglomerados Últimos” para calcular el error en la muestra a posteriores para muestras estratificadas. Éste método fue creado por un investigador español y fue publicado en España. Pueden encontrar la referencia aquí, https://dialnet.unirioja.es/descarga/articulo/250808.pdf
Tratar de entender el método y las fórmulas que se usan es difícil, afortunadamente el cliente ya tenía una implementación elegante de dichas fórmulas en el Script MDX usando la sentencia SCOPE y en solo unas líneas implementaron la parte más compleja de las fórmulas. Por lo tanto me enfoqué en el tema de performance en lugar de la implementación de las fórmulas.
Después de un par de horas encontré que la fórmula estaba usando calculas cell by cell en logar de cálculos por bloque, la causa era un operador (el operador “^”) y después de un pequeño cambio (multiplicar la métrica por si misma) el query mejoró de aproximadamente 30 segundos a 1 segundo.
Puedes encontrar el detalle acerca de operadores que soportan cálculos basados en bloque en el documento “Identifying and Resolving MDX Query Performance Bottlenecks in SQL Server 2005 Analysis Services” encontrado en https://www.microsoft.com/en-us/download/details.aspx?id=661, también puedes encontrar algunas recomendaciones para mejorar performance de queries en https://msdn.microsoft.com/en-us/library/bb934106.aspx
El enfoque de éste blog es en cómo podemos detectar los casos en donde el problema es cálculos Cell by Cell.
Tenemos 2 herramientas que usaremos para éste propósito, una es el SQL Server Profiler y la otra es el Performance Monitor, el orden recomendado es identificar primero que el problema está en el Formula Engine y después confirmar con el Performance Monitor que la causa de que el Formula Engine esté lento son cálculos Cell By Cell.
Aquí está la metodología recomendada, esto no es nuevo, pero no he encontrado una buena referencia que cubra éstos pasos.
Paso 1. Identificar si el cuello de botella está en el Formula Engine.
Utilizar el profiler para capturar la ejecución de tu query, es más fácil si haces esto en un ambiente aislado pero si no es posible, puedes filtrar los eventos en tu query por el ConnectionId o alguna otra columna que identifique todos los eventos de tu query.
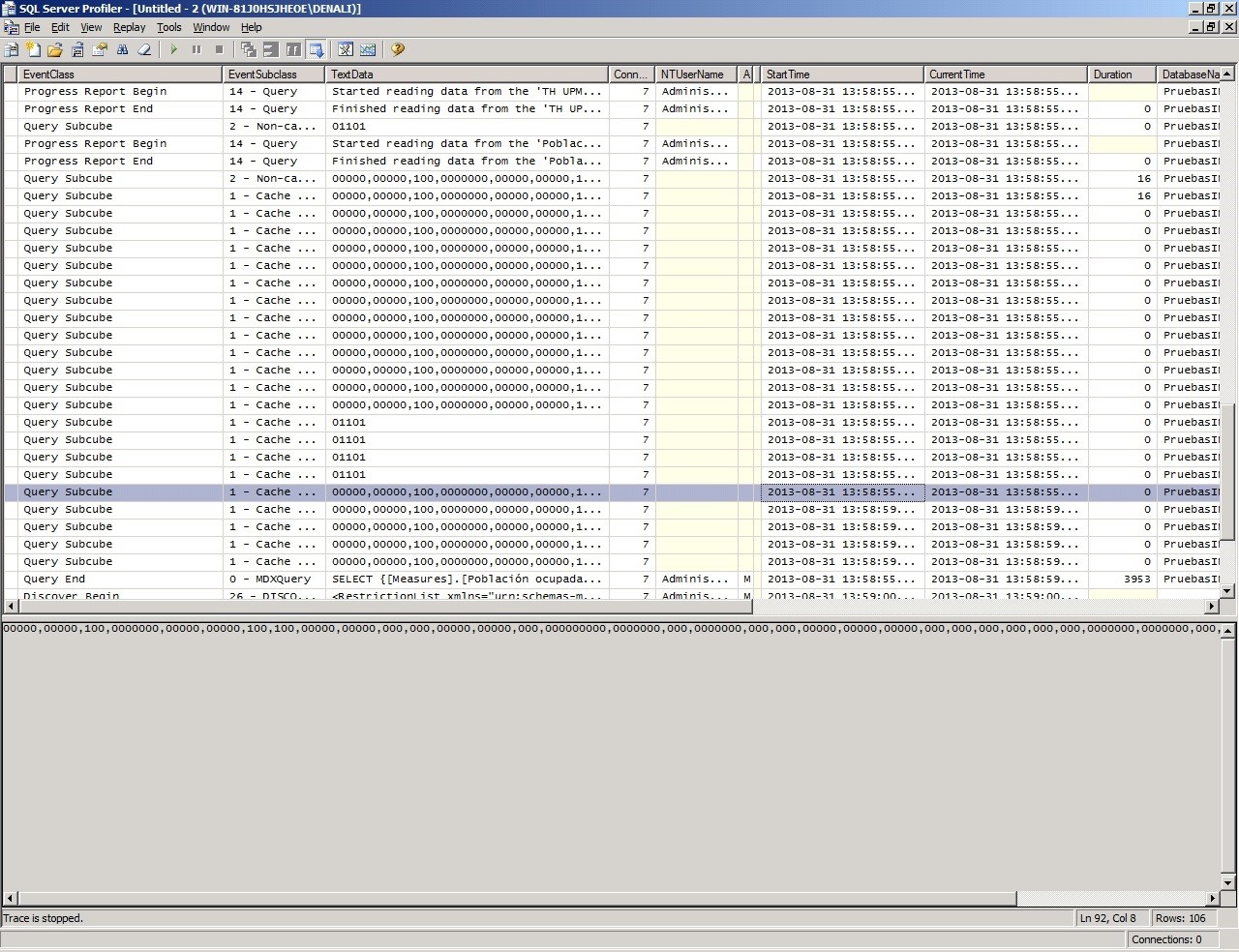
Necesitas sumar la duración de cada evento QuerySubcube y restar ese total de la duración mostrada en el evento QueryEnd. En éste ejemplo puedes ver que la mayoría de los subcubos tomó 0 ms, algunos tomaron 16ms y otro que no se ve en la imagen tomó alrededor de 110 ms. El total del query fue 3,953 ms, eso significa que Analysis Services utilizó 142 en el Storage Engine y la diferencia de 3811 se utilizó en el Formula Engine.
En conclusión, en el caso anterior tenemos un cuello de botella en el Formula Engine Bottleneck, revisemos si en éste caso es causado por cálculos cell by cell.
El procedimiento anterior puede no escalar tan bien cuando tienes cientos de subcubos o muchos queries utilizando cálculos Cell by Cell en el mismo trace, en esos casos el siguiente procedimiento puede ser más apropiado:
- Guarda el profiler a una table de SQL Server.
- Ejecutar el siguiente Query de T-SQL para obtener los queries de mayor duración
SELECT ROWNUMBER, EVENTCLASS, EVENTSUBCLASS, TEXTDATA, DURATION, CONNECTIONID FROM <TABLE_NAME> WHERE EVENTCLASS=10 - Ejecutar el siguiente Query de T-SQL para obtener el inicio y finalización del query en el trace.
SELECT TOP 2 ROWNUMBER, EVENTCLASS, EVENTSUBCLASS, TEXTDATA, DURATION, CONNECTIONID FROM <TABLE_NAME> WHERE EVENTCLASS IN (9,10) AND CONNECTIONID=<TARGET_CONNECTIONID> AND ROWNUMBER <= <ROWNUMBER_OF_TARGET_QUERY> ORDER BY ROWNUMBER DESC - Ejecutar el siguiente query de T-SQL para determinar la cantidad de tiempo que se gastó en el Storage Engine y en el Fórmula Engine.
SELECT SUM(DURATION) FROM <TABLE_NAME> WHERE EVENTCLASS=11 AND CONNECTIONID=<TARGET_CONNECTIONID> AND ROWNUMBER BETWEEN <QUERY_BEGIN_ROWNUMBER> AND <QUERY_END_ROWNUMBER>
Paso 2. Identificar si el problema es causado por cálculos Cell by Cell
Puedes utilizar el Performance Monitor para identificar si el problema son cálculos Cell By Cell. Para ser exitoso en ésta tarea es mucho mejor que ejecutes el query en un ambiente aislado porque tenemos un contador con el total de cálculos de celdas para toda la instancia y no hay forma de separarlo por query en el Performance Monitor. La imagen de abajo muestra cómo se ve el ejemplo nuestro.
En la imagen puedes ver que el contador usado es “MSOLAP&InstanceName:MDX \ Total Cells Calculated” y el valor inicial es 0 y el valor después de ejecutar el query es superior a 1 millón.
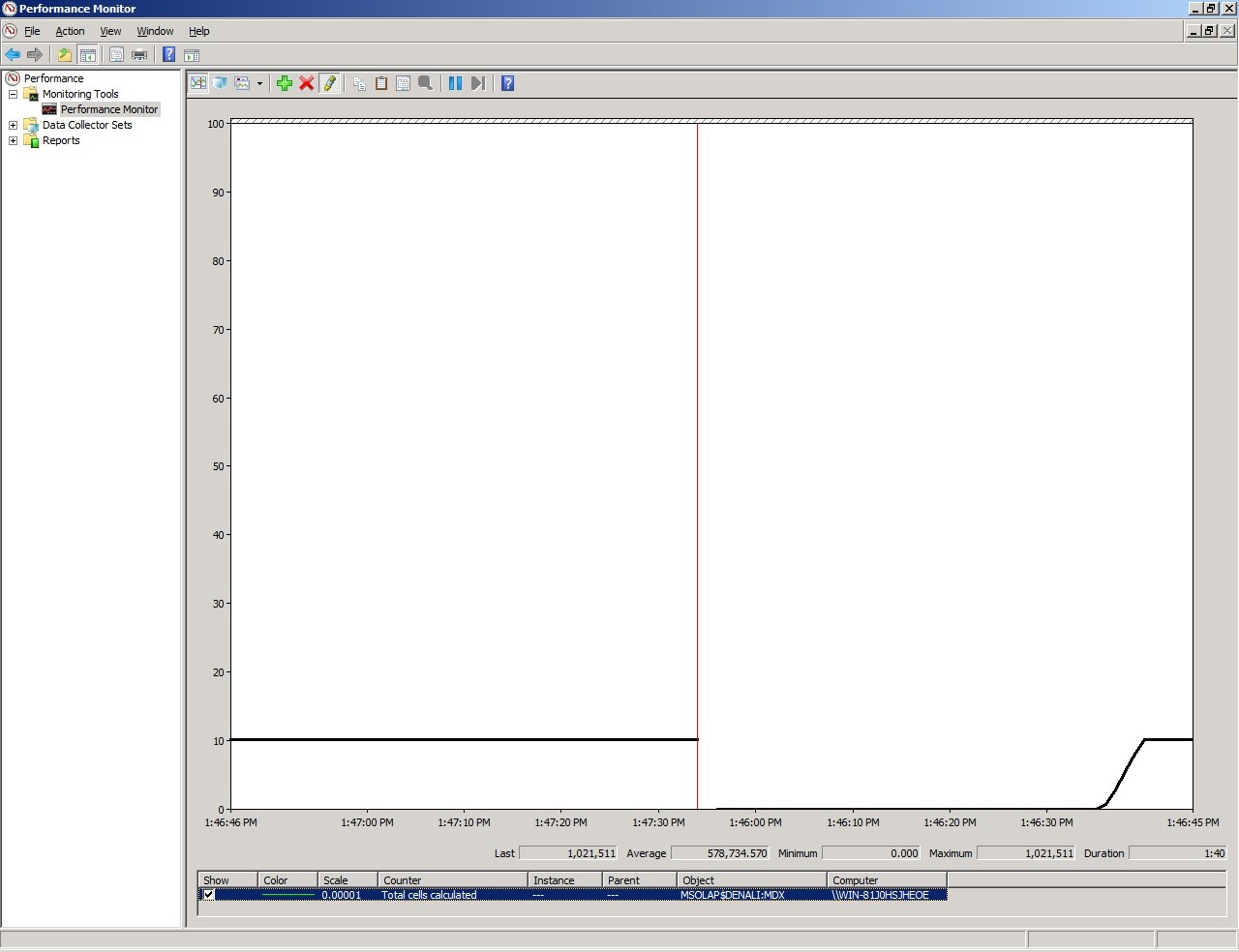
Los resultados anteriores fueron después de reiniciar la instancia y una sola ejecución del query generó más de un millón de celdas calculadas. Si ésta es la primera vez que haces esto no sabes si 1 millón es muy alto o es bajo. Puedo asegurarte que para éste query es un número bastante alto.
Paso 3. Modificar tu query
Modificar el query utilizando las recomendaciones en los links mencionados anteriormente hasta que dejes de ver el gran incremento en número de celdas calculadas para tu query.
En éste caso particular el Script MDX estaba usando algunas expresiones del tipo:
Measures.Measure1 ^ 2
Cambiamos la formula a algo como:
Measures.Measure1 * Measures.Measure1
Después de que la formula fue cambiada obtuvimos los siguientes resultados.
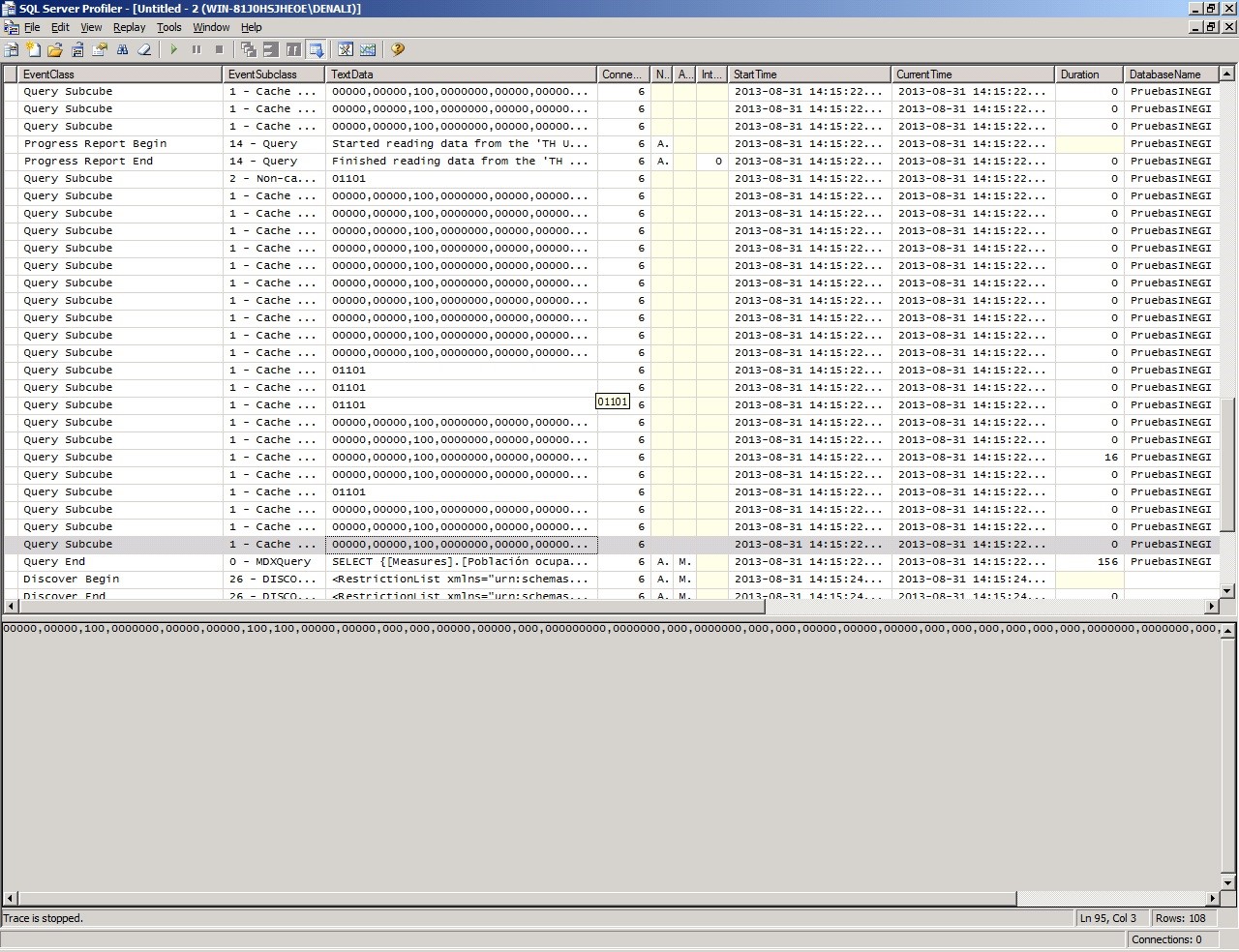
Puedes ver que el total del query es 156 ms, considerando que el Storage Engine debió usar el mismo tiempo, 132 ms, significa que el Formula Engine tomó aproximadamente 24 ms.
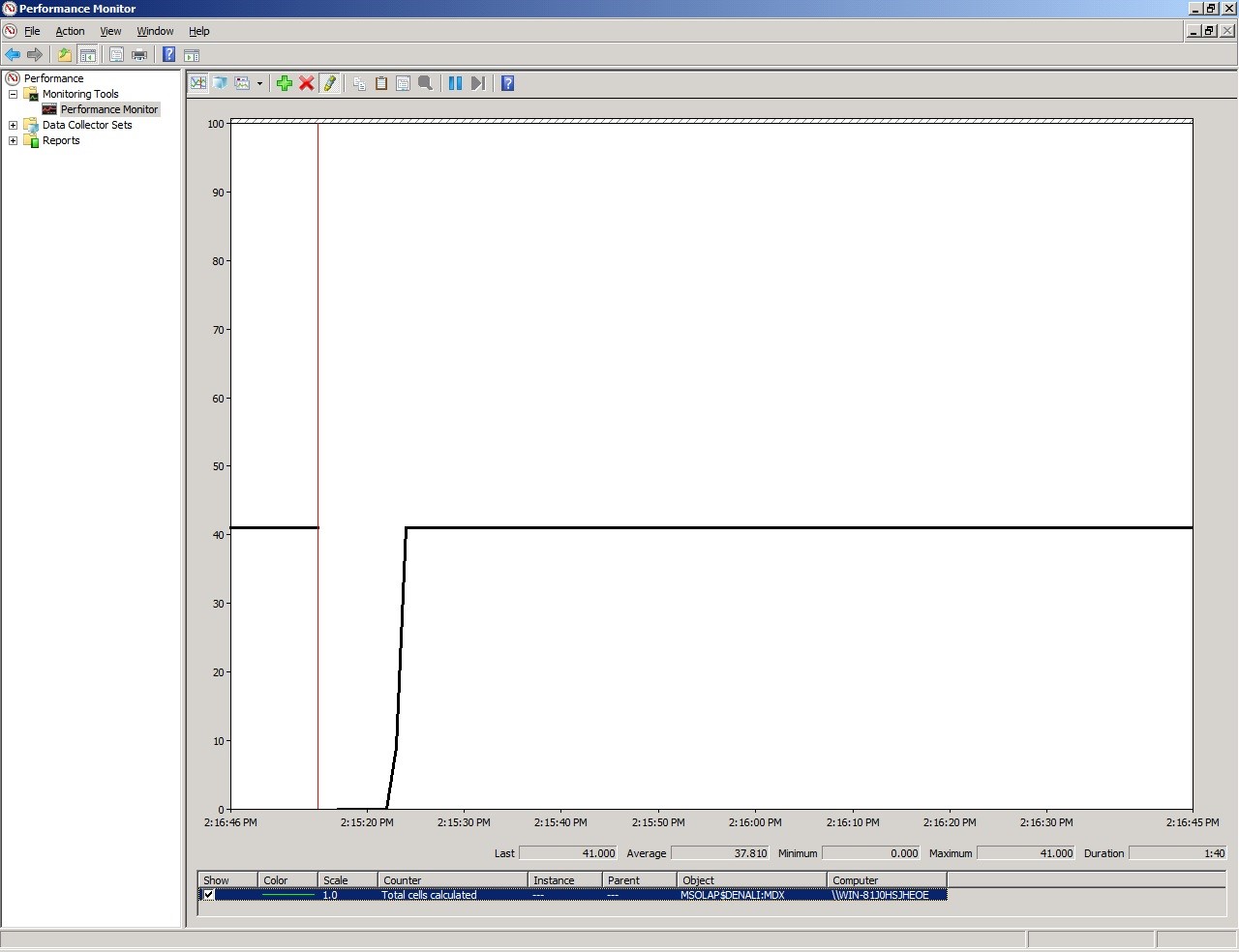
En el Performance Monitor podemos ver que el total de celdas calculadas fue 41. El query fue ejecutado después de que se reinició la instancia.
Comentarios Finales
Esto es solo el procedimiento básico para encontrar si los cálculos cell by cell están causando problemas en tu ambiente. Las modificaciones al query para evitar cálculos cell by cell puede ser fácil algunas veces, como en éste caso real, o muy difícil en otros escenarios.
Espero esto sea útil para que puedan empezar a solucionar sus propios casos.