SQL Server chez les clients – Self-Service BI et Microsoft Azure Machine Learning

Analyse de données et Machine Learning
Les métiers et professionnels ont un besoin croissant d'analyse de données diverses mais au-delà de la simple analyse nous devons de plus en plus comprendre nos données, les extrapoler, en déduire des prédictions, analyser le passé pour comprendre le futur, en déduire des comportements et prendre des actions ou décisions.
Microsoft s’intègre dans cette vision Big Datas et compréhension de la donnée de différentes façons toutes adaptées à différents usages :
- Microsoft HDInsightplatform
- Microsoft Hortonworks
- Microsoft Azure Machine Learning
- Microsoft Analysis Services DataMining
Nous n’allons pas faire une nouvelle description du big datas, chacun pourra intégrer cette notion à son projet suivant différents axes qui lui sont propres, mais nous allons parcourir les nouveaux usages et expliquer les fondements du machine learning au travers de la self-service BI connecté à la nouvelle plateforme Microsoft Azure Machine Learning.
Concept de "Machine Learning"
Le Machine Learning est une science qui permet de créer des systèmes qui vont apprendre des données, qu’elles soient connues, non connues et externes.
Le ML est une approche par les données répondant à une problématique métier. La résolution repose sur des patterns non connus, à découvrir, entrainer et optimiser.
Les process sous-jacents vont apprendre des données internes, externes et surtout vont s’adapter à d’éventuels changements de paramètres externes.
Le cœur de la technologie repose sur un ensemble d’algorithmes complexes, certains déjà présent dans certains outils par exemple Analysis Services depuis plusieurs versions.
Les quatre caractéristiques principales d’un système de machine learning performant sont les suivantes :
- Accurate : Plus le système absorbe de données plus la précision du modèle sera élevée
- Fast : Le système doit pouvoir exposer des interfaces pour soumettre des données et obtenir des réponses rapidement
- Scalable : Un tel système doit être scalable donc pouvoir croitre au fur et à mesure que le volume de données à traiter augmente
- Automated : Lors de la soumission d’une nouvelle entrée le système estime une réponse dans un workflow automatisé
Une définition du Machine Learning peut-être décrite par le schéma suivant:
X = les variables en entrée, y = les variables en sortie et h les variables cachées.
Les algorithmes de machine learning permettent de découvrir les relations entre les variables du système, qu’elles soient en entrée, sortie ou cachée depuis un extrait des données du système.
Ci-après vous trouverez plusieurs types de Machine Learning
- Learning association : Trouver des relations entre les données (market basket analysis)
- Supervised Learning : Classification ,Regression
- Unsupervised Learning : Seules les données en entrées sont disponibles et nous cherchons les régularités dans ces données
- Reinforcement Learning : Chercher un comportement qui associe un état à une action
- Etc.
L'approche Microsoft Azure Machine Learning
Microsoft accompagne ses clients en mettant à disposition à disposition des services Cloud permettant aux utilisateurs de mieux comprendre leurs données et d’en faire naitre des scénarios complexes pour des prises de décisions basées sur des analyses prédictives.
Pour illustrer l’approche nous allons par exemple étudier la classification à l’aide d’un algorithme de Clustering de type k-means.
La compréhension de cet algorithme est la suivante :
Sélection des entrées Sélection des k clusters (training datas)


Attribution sur le centre le plus proche et mise à jour des centres des clusters
Réassignation des entrées et répétition jusqu’à obtenir la convergence

Cette approche va permettre de classifier des données (clients, produits, etc.) suivant un nombre finit d’attributs. Dès lors Microsoft Azure Machine Learning permet d’exposer la fonction de classification sous la forme d’un web service qui sera accessible pour classifier en temps réel une nouvelle donnée entrante.
Pour avoir une présentation de l’interface de Microsoft Azure Machine Learning vous pouvez accéder à l’url suivante qui vous donnera plus de détail :https://azure.microsoft.com/en-us/campaigns/machine-learning/
Ce qui est intéressant c’est de croiser l’utilisation de Microsoft Azure ML avec de la Self-Service BI, mais comment faire ?
Imaginons que nous voulions classifier une ensemble de céréales suivant leurs apports caloriques, taux de graisse, etc. (nous pouvons extrapoler cette approche à des besoins plus business oriented).
Les étapes sont les suivantes :
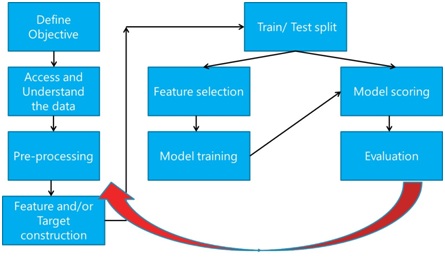
Mais concrètement comment cela se passe ? Il vous suffira de suivre les étapes suivantes :
1. Déployer le dataset sur Microsoft Azure ML
Dans cette première étape nous prendrons un fichier .csv au format suivant:

2. Définir le modèle, c’est à dire spécifier dans l’interface Microsoft Azure ML les attributs qui vont participer à la classification des éléments.
3. Intégrer l’algorithme de k-meansclustering comme algorithme à appliquer à nos données
4. Entrainer le modèle
5. Evaluer le modèle
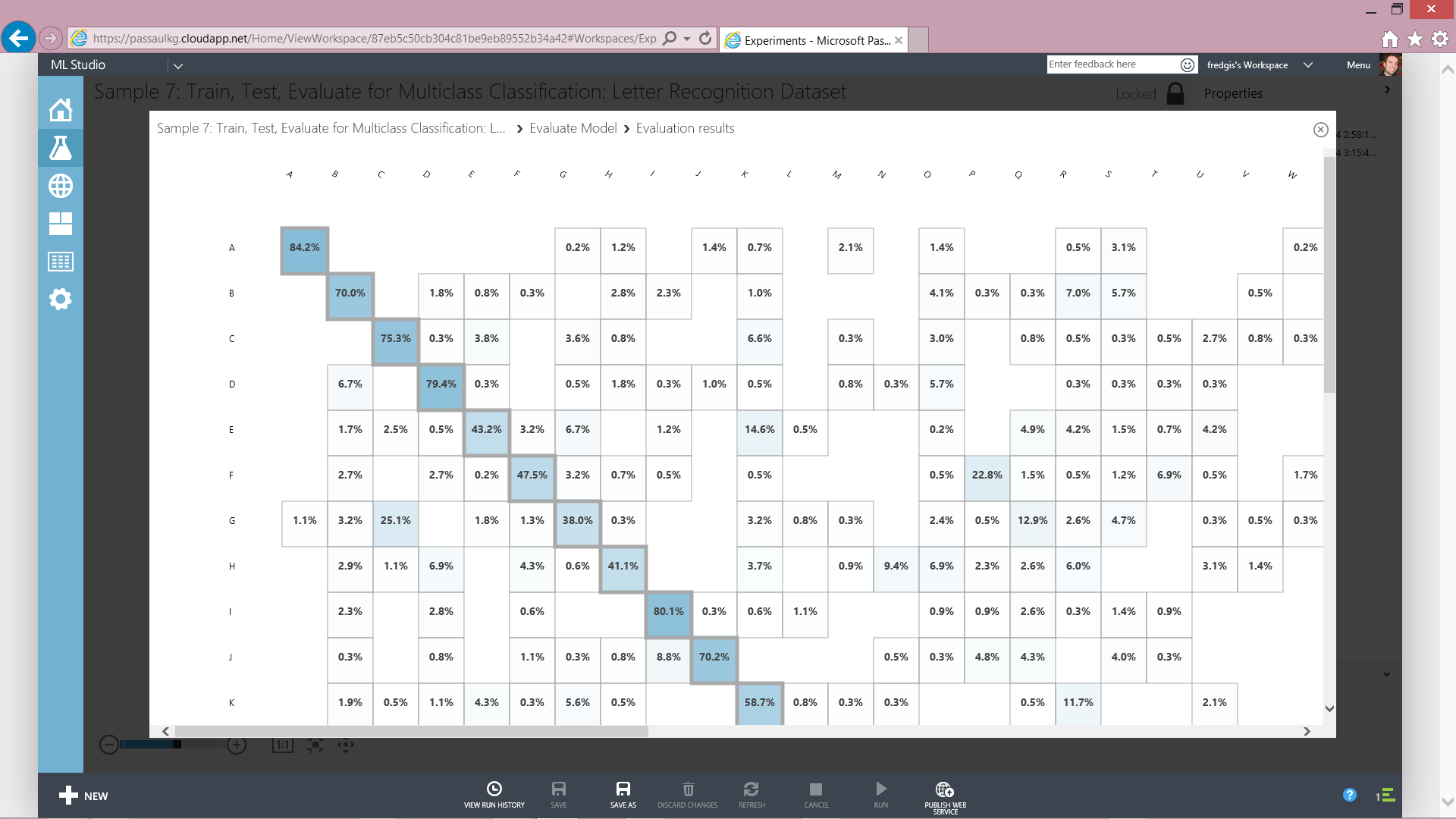
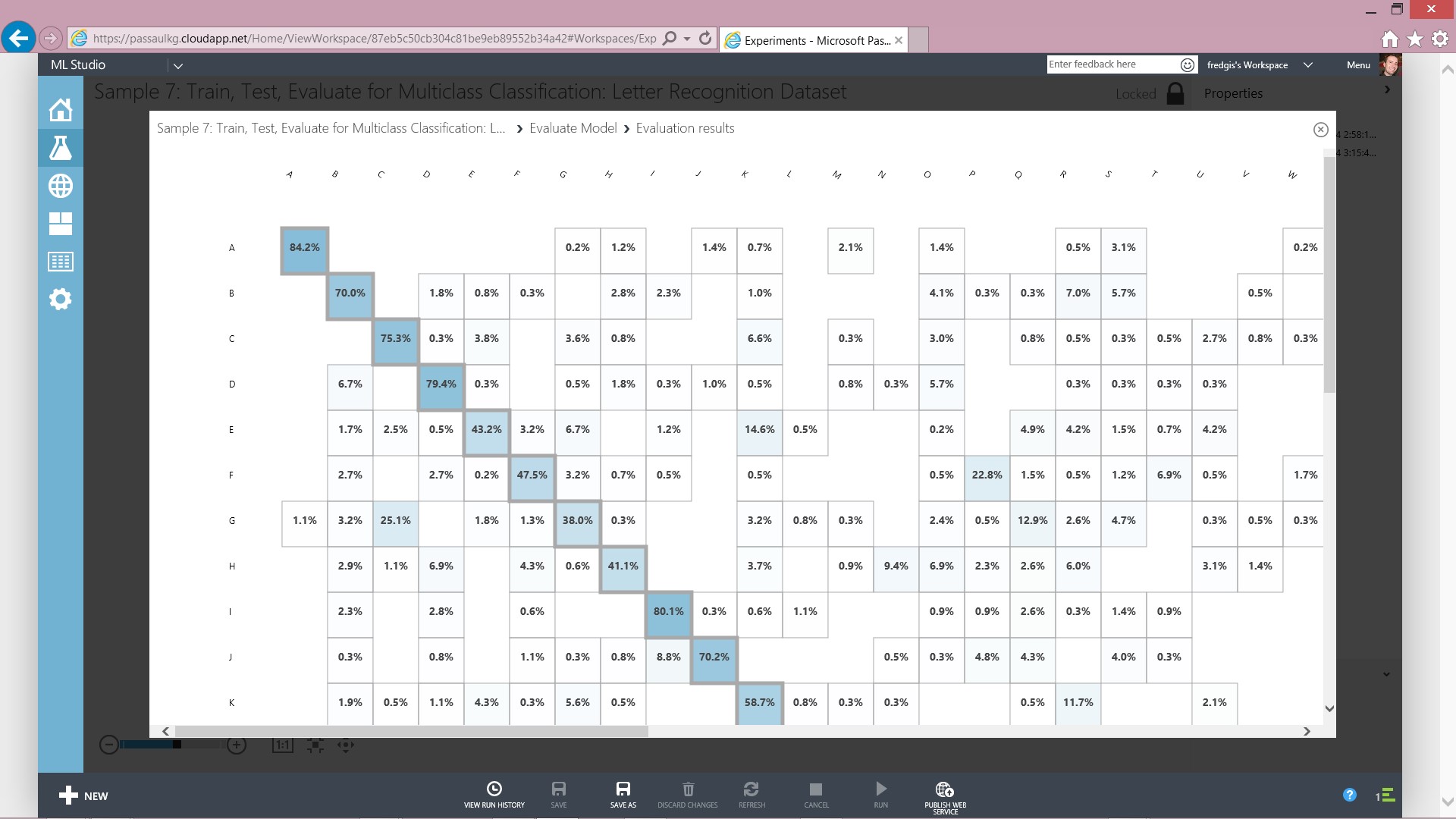
6. Consulter les résultats de classification
7. Dès lors des résultats sont visibles sous la forme de courbes statistiques. Le point intéressant est de consommer ces données en sortie directement dans notre solution de self-service BI.
{kind=link}
{kind=link}
Nous avons pour l’instant un dataset sur Azure, une solution qui permet de faire ma classification et nous choisissons en interface de sortie un blob storage azure que nous pouvons parcourir à l’aide de Microsoft Management Studio.
Cet Azure Storage Account dispose de l’ensemble des simulations de clustering faites du dataset en entrée préalablement chargé et analysé.
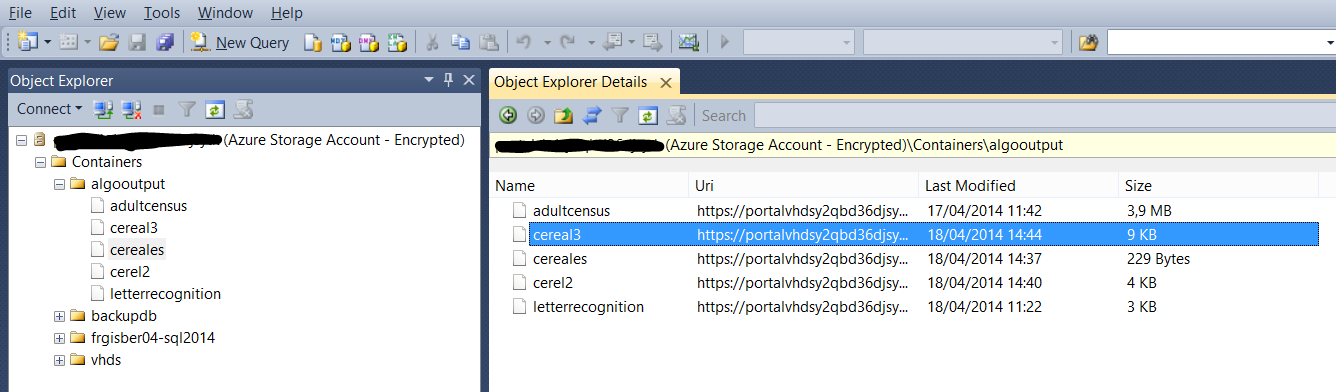
Le format de sortie est spécifié dans la destination, celui-ci se présente de la façon suivante :
"N","C",70,4,1,130,10,5,6,280,25,3,1,0.33,68.402973,1,"100%_Bran","N","C",70,4,1,130,10,5,6,280,25,3,1,0.33,68.402973
"Q","C",120,3,5,15,2,8,8,135,0,3,1,1,33.983679,0,"100%_Natural_Bran","Q","C",120,3,5,15,2,8,8,135,0,3,1,1,33.983679
"K","C",70,4,1,260,9,7,5,320,25,3,1,0.33,59.425505,1,"All-Bran","K","C",70,4,1,260,9,7,5,320,25,3,1,0.33,59.425505
"K","C",50,4,0,140,14,8,0,330,25,3,1,0.5,93.704912,1,"All-Bran_with_Extra_Fiber","K","C",50,4,0,140,14,8,0,330,25,3,1,0.5,93.704912
"R","C",110,2,2,200,1,14,8,-1,25,3,1,0.75,34.384843,4,"Almond_Delight","R","C",110,2,2,200,1,14,8,-1,25,3,1,0.75,34.384843
"G","C",110,2,2,180,1.5,10.5,10,70,25,1,1,0.75,29.509541,4,"Apple_Cinnamon_Cheerios","G","C",110,2,2,180,1.5,10.5,10,70,25,1,1,0.75,29.509541
"K","C",110,2,0,125,1,11,14,30,25,2,1,1,33.174094,4,"Apple_Jacks","K","C",110,2,0,125,1,11,14,30,25,2,1,1,33.174094
"G","C",130,3,2,210,2,18,8,100,25,3,1.33,0.75,37.038562,4,"Basic_4","G","C",130,3,2,210,2,18,8,100,25,3,1.33,0.75,37.038562
"R","C",90,2,1,200,4,15,6,125,25,1,1,0.67,49.120253,4,"Bran_Chex","R","C",90,2,1,200,4,15,6,125,25,1,1,0.67,49.120253
"P","C",90,3,0,210,5,13,5,190,25,3,1,0.67,53.313813,1,"Bran_Flakes","P","C",90,3,0,210,5,13,5,190,25,3,1,0.67,53.313813
"Q","C",120,1,2,220,0,12,12,35,25,2,1,0.75,18.042851,4,"Cap'n'Crunch","Q","C",120,1,2,220,0,12,12,35,25,2,1,0.75,18.042851
L'intégration avec la BI en libre service Microsoft
Nous utilisons maintenant Microsoft PowerQuery pour consommer directement le résultat depuis le blob storage azure.
On ajoute maintenant le résultat de la requête au modèle Microsoft PowerPivot. Nous avons alors chargé les produits de céréales avec leur classification.
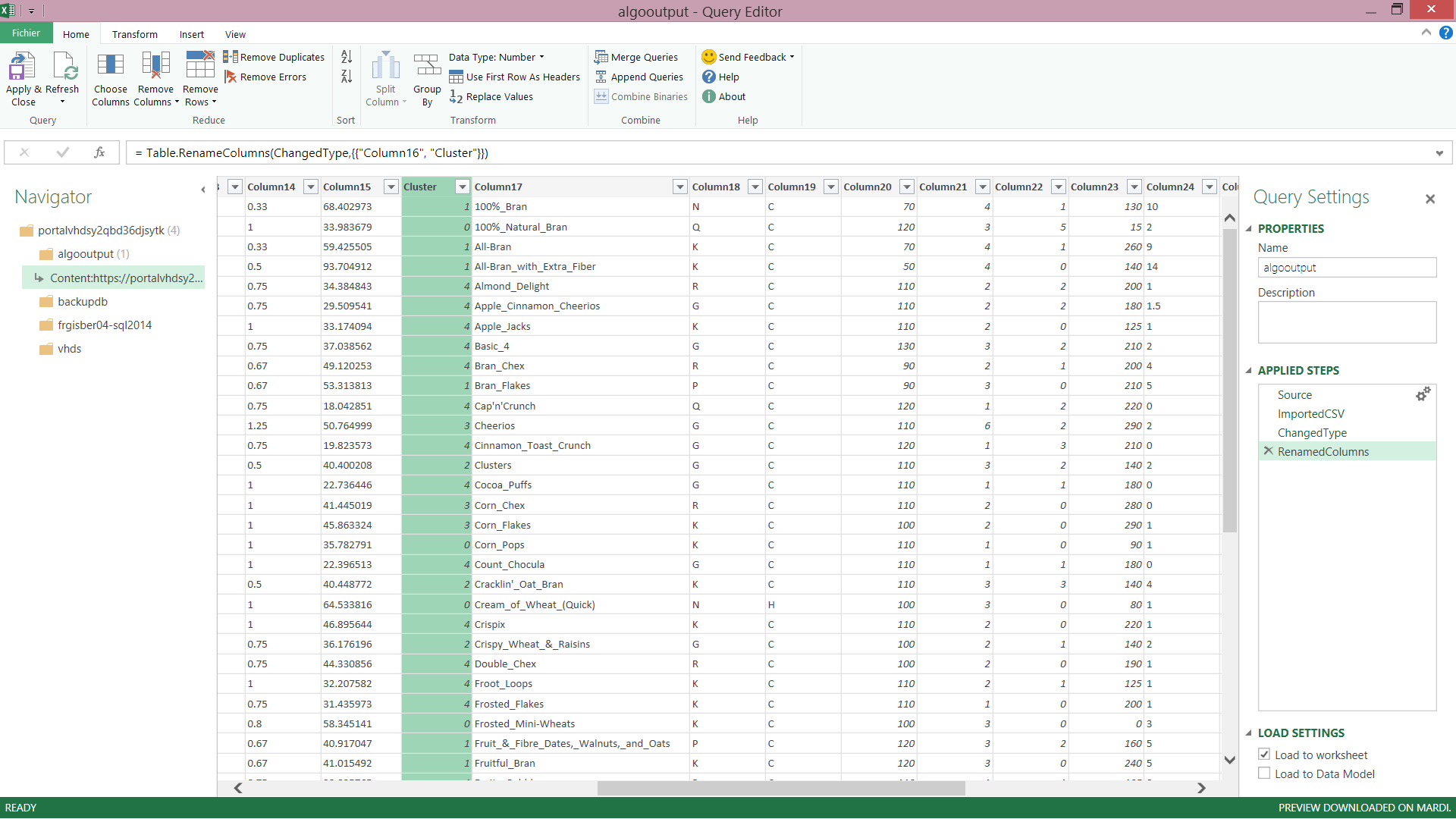
{kind=link}
Il n’y a plus qu’à consommer ce modèle dans PowerView directement avec Excel 2013 et laisser place à l’analyse
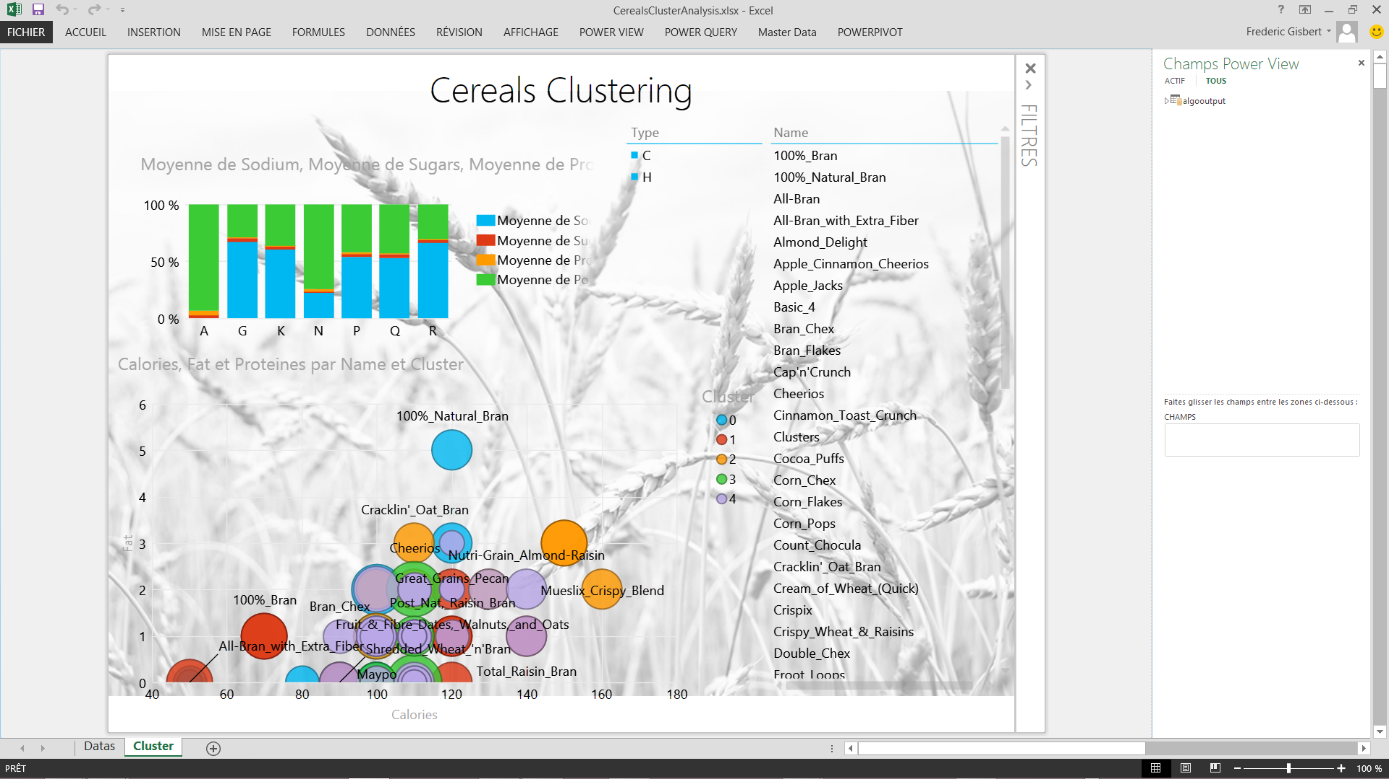
Vous pouvez alors filtrer sur les différents clusters, ici de 0 à 4, et voir se représenter les articles positionnés dans ceux-ci. Bien sûr vous aurez ainsi accès à toutes les mesures définies dans votre dataset caractérisant chacun des produits.
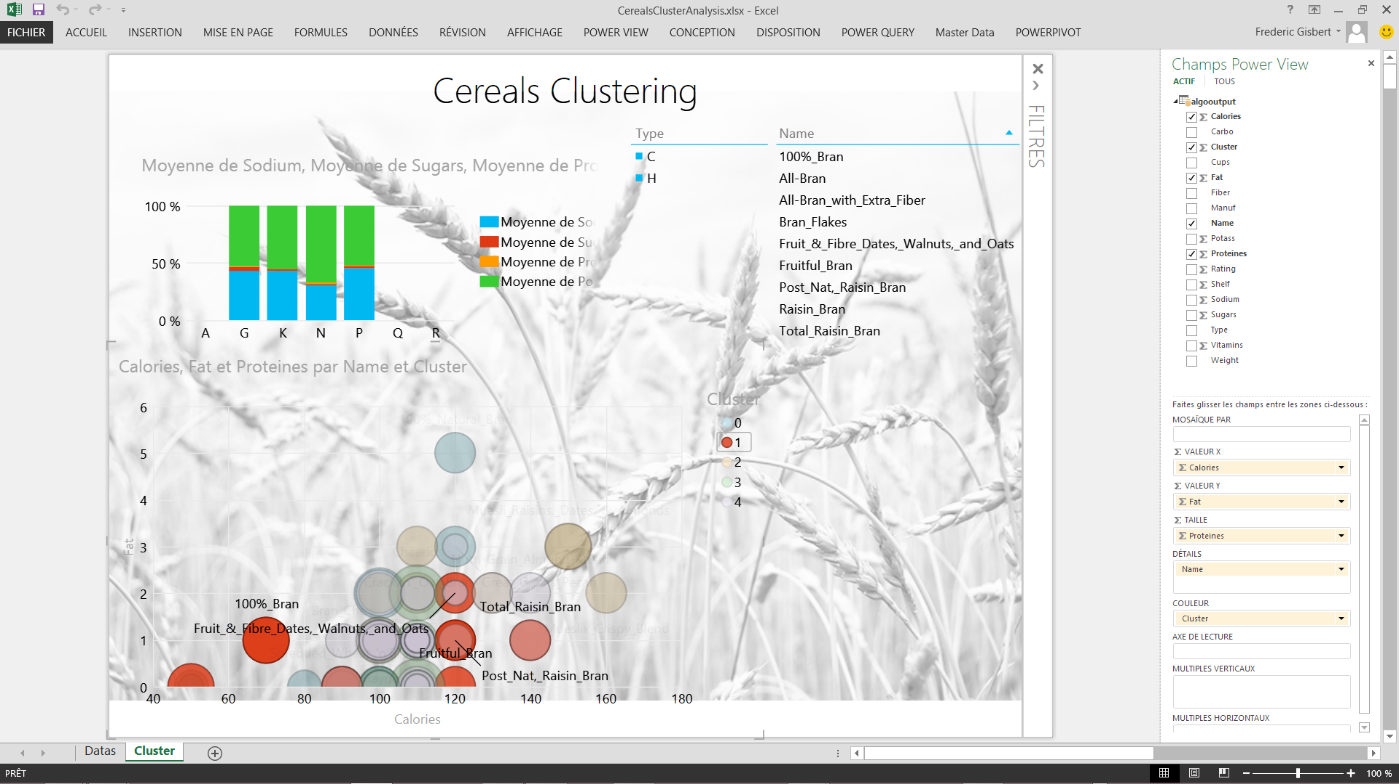
Ceci est un avant-gout de l’apport d’une solution Microsoft Azure Machine Learning couplée à de la self-service BI.
Pour plus d’informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d’informations sur les blogs « SQL Server chez les clients ».
 |
Frédéric Gisbert, Architecte BI/SQL/Big Data Microsoft Consulting Services J’interviens en clientèle sur des problématique BI, Big Data et plus globalement de gestion de données (MDM, CEP, SharePoint) en tant que lead technique et architecte. Le but premier d’un architecte solution est d’intégrer la suite SQL Server dans des environnements hétérogènes en considérant toutes les spécificités de chacun de nos clients. J’interviens aussi dans des problématiques Big Data sur nos solutions Hortonworks (Hadoop). Certification : Analysis Services MAESTRO |