SQL Server chez les clients – Le Partitionnement Analysis Services

SQL Server Analysis Services (SSAS) est la plateforme d’analyse multidimensionnelle de l’offre décisionnelle de Microsoft, intégrée au sein de la suite SQL Server. SSAS fournit des fonctionnalités d’analyse interactive et prédictive, directement exploitables au sein de la gamme de produit Office, notamment Excel et SharePoint.
Déployé chez de nombreux clients, SSAS est capable de prendre en charge des volumétries de plus en plus importantes, tout en fournissant un excellent niveau de performance et de disponibilité, ce qui permet de répondre aux besoins critiques de reporting et d’analyse des entités métiers.
Le découpage physique d’un cube multidimensionnel à travers une stratégie de partitionnement adaptée fait partie des problématiques cruciales dans la mise en place d’une solution décisionnelle performante, capable de prendre en charge d’importantes volumétries.
Cet article a ainsi pour objectif d’illustrer les fonctionnalités de partitionnement de SSAS afin d’en comprendre les bénéfices apportés et les possibilités d’évolution pour s’adapter aux besoins métier du système décisionnel tout en garantissant de hautes performances.
Problématique
- Comprendre les bénéfices du partitionnement avec SQL Server Analysis Services
- Identifier des scénarios de partitionnement
- Adapter sa stratégie de partitionnement aux besoins des utilisateurs
- Connaitre les best-practices à adopter pour le design de partition
Rappel de concept
Une mesure représente une colonne qui contient des données, généralement numériques, qui peuvent être quantifiées et agrégées. Une mesure est mappée généralement à une colonne d'une table de faits.
Un groupe de mesures est composé d'informations de base, de mesures, de dimensions et de partitions. Un cube multidimensionnel peut contenir plusieurs groupes de mesures. Les requêtes/calculs réalisés sur le cube peuvent utiliser des données issues de plusieurs groupes de mesures.
Les partitions sont la collection de fractionnements physiques d’un groupe de mesures.
Ainsi les partitions sont utilisées par Microsoft SQL Server Analysis Services pour gérer et stocker au sein du cube les données détaillées et les agrégations d’un groupe de mesures (ensemble d’indicateurs).
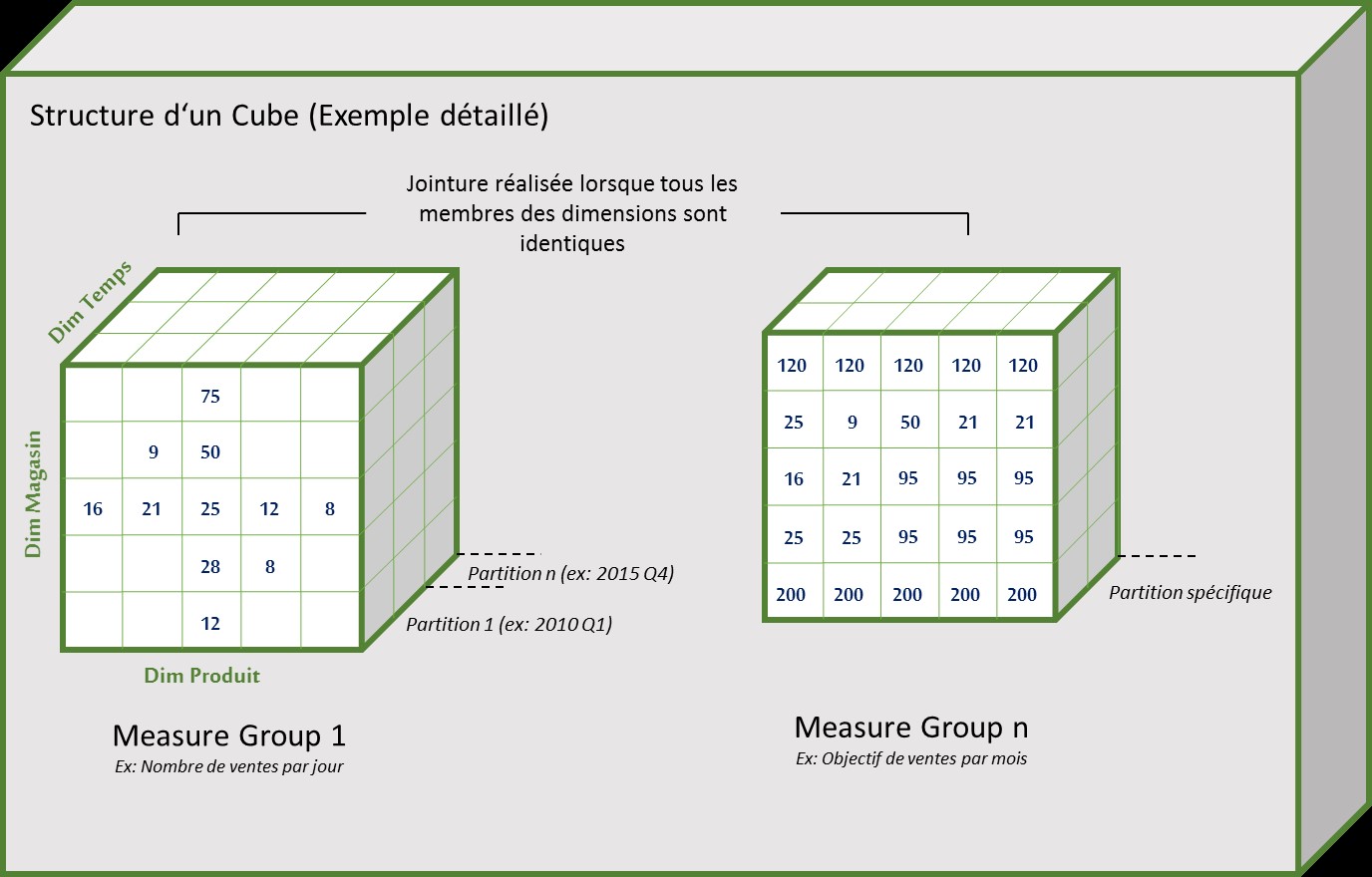
Il est possible de découper un groupe de mesure en plusieurs partitions, afin de repartir la volumétrie de données entre différentes structures de stockage logique.
Comme on peut l’observer sur l’illustration ci-dessus, le principe de découpage des partitions est réalisé en fonction d’une dimension/axe analytique (ex : temps, géographie, catégorie de produits…) et d’une granularité (ex : année, mois, région, vtt...) à définir lors de la conception du cube.
Pour de plus amples informations concernant le partitionnement SSAS en mode multidimensionnel, n’hésitez pas à vous référer à l’article suivant : Partitions (Analysis Services - Multidimensional Data).
Bénéfices
Le partitionnement de SQL Server Analysis Services présente de nombreux avantages
Parallélisme des traitements : Plusieurs partitions peuvent être rafraichies en parallèle et ainsi réduire le temps de process total du cube.
Traitements et Requêtes distribués : Le partitionnement permet la répartition des données pour réduire les temps de calcul et les temps de réponses des requêtes. En effet les partitions offrent la possibilité de répartir les données sources et les données agrégées d'un cube sur plusieurs disques durs et sur plusieurs serveurs. Ces ressources peuvent ainsi être utilisées en supplément du serveur portant le cube.
Remarque : lors de l’utilisation de ces fonctionnalités, il faut bien tenir compte des limitations de l’infrastructure en place afin d’éviter des baisses de performances des traitements et requêtes.
Fraicheur des données: Le partitionnement permet de mettre plus rapidement à disposition des utilisateurs les dernières données modifiées ou ajoutées, en rafraichissant uniquement la partie du cube concernée par ces données. Cela permet également, si nécessaire, de « reconstruire » plus rapidement un cube à forte volumétrie, en traitant en priorité les partitions les plus récentes pour finir avec les partitions concernant des données « d’archives ».
Performance des requêtes et des agrégations : Grâce au partitionnement, les requêtes exécutées sur le cube sont réalisées sur des sous-ensembles plus fins du cube ce qui permet d’en accélérer le résultat. Les agrégations profitent aussi de ses sous-ensembles.
Ainsi le concept de partitionnement répond aux besoins tels que la BI temps réel et l’archivage dynamique des données mais peut aussi aider à réduire les problèmes de calculs et de performances.
Attention : un mauvais design de cube ou un design de partitions dont les requêtes MDX ne sont pas optimisées peuvent réduire les optimisations de performances voir rendre totalement contre-productive la stratégie de partitionnement.
Best Practices
Un design de partitionnement efficace fait appel à des partitions permettant d'éliminer tout process inutile et charge résultante au niveau du processeur des serveurs Analysis Services, tout en veillant à ce que les données soient processées et actualisées suffisamment souvent pour refléter les données les plus récentes.
Spécificités du parallélisme
Les traitements sur les partitions s’effectuant sur des threads différents, un serveur possédant un ou des processeurs à plusieurs cœurs permet ainsi de paralléliser d’autant les traitements sur ces partitions.
Par contre en cas de fort partitionnement, le support de stockage doit fournir suffisamment de performance I/O en lecture aléatoire car les charges I/O (lecture et écriture) augmentent avec le nombre de partitions présentes. Les nouveaux supports de stockage SSD ou Fusion IO sont adaptés à ce type de lecture/écriture et offre des gains de performances non négligeables dans ces conditions.
Administration du partitionnement
Plusieurs outils permettent d’administrer le partitionnement SSAS d’un cube multidimensionnel.
Partitionnement avec SQL Server Management Studio (SSMS)
SSMS permet de gérer manuellement les partitions de chaque groupe de mesures, on peut ainsi au sein d’un groupe de mesures :
Créer de nouvelles partitions en spécifiant l’étendue de la partition
Réaliser des merges de partitions
Supprimer des partitions
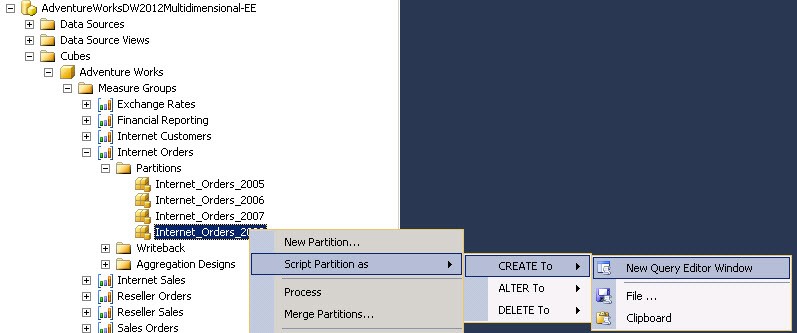
Chaque partition peut aussi être scriptée (Create, Alter, Delete) comme le montre l’illustration ci-dessus.
Partitionnement par Script
- Analysis Management Objects (AMO) est une librairie de développement permettant de gérer des instances SSAS au sein d’autres applications (en .NET, avec Powershell).
Voici par exemple comment créer avec AMO en .NET (C#) une partition associée à un groupe de mesure spécifique :
static void CreateInternetSalesMeasureGroupPartitions(MeasureGroup mg)
{
Partition part;
part = mg.Partitions.FindByName("Internet_Sales_184");
if (part != null)
part.Drop();
part = mg.Partitions.Add("Internet_Sales_184");
part.StorageMode = StorageMode.Molap;
part.Source = new QueryBinding(db.DataSources[0].ID, "SELECT * FROM [dbo].[FactInternetSales] WHERE OrderDateKey <= '184'");
part.Slice = "[Date].[Calendar Year].&[2001]";
part.Annotations.Add("LastOrderDateKey", "184");
}
Le process des partitions peut ensuite être réalisé ainsi :
static void FullProcessAllPartitions(MeasureGroup mg)
{
foreach (Partition part in mg.Partitions)
part.Process(ProcessType.ProcessFull);
}
- XMLA (XML for Analysis) est un protocole XML basé sur SOAP (Simple Object Access Protocol) conçu spécifiquement pour offrir un accès universel à n'importe quelle source de données multidimensionnelle standard accessible via une connexion http. Ce protocole permet aussi de gérer le partitionnement d’un cube SSAS comme on pourra le voir plus spécifiquement dans la suite de l’article.
Partitionnement avec SQL Server Integration Services (SSIS)
SSIS propose 2 tâches spécifiques à SSAS :
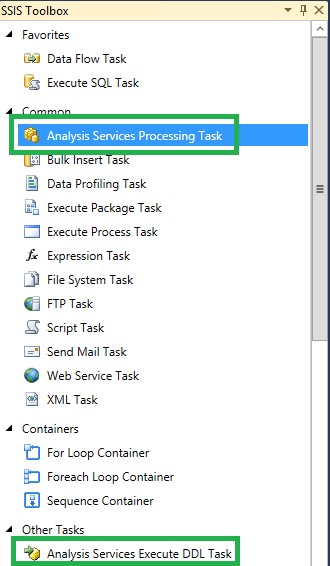
Analysis Services Execute DDL Task propose d’exécuter du script XMLA sur une instance Analysis Services. Cela permet dans le cas du partitionnement de créer/supprimer/processer des partitions mais aussi d’administrer l’ensemble des objets de l’instance SSAS.
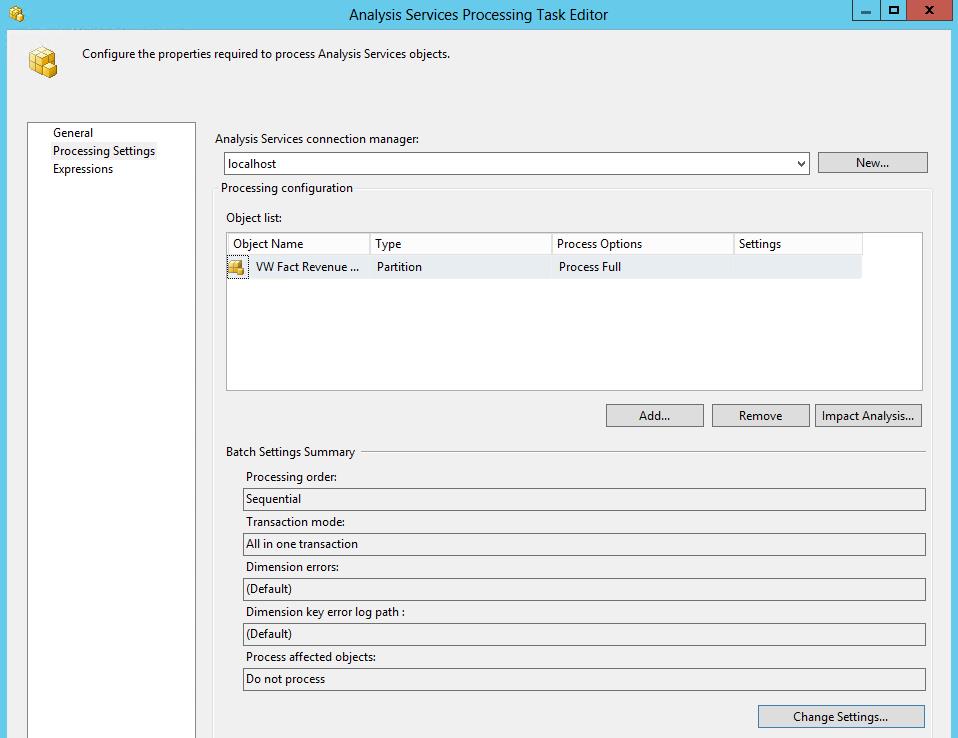
Analysis Services Processing Task permet de processer le cube avec une configuration spécifique.
{kind=link}
-
Liste des objets à processer (bases de données, cubes, groupes de mesures, partitions) ainsi que le type de process à réaliser. Les types proposés seront différents en fonctions de l’objet ciblé par la tâche de process.
D’autres paramètres permettent de définir le comportement des différentes actions de process (sequentiel ou parallèle) et la gestion des erreurs.
Mise en place d'une solution de partitionnement dynamique, souple et administrable
Sans mise en place d’une solution spécifique, la stratégie de partitionnement des données d’un cube SSAS reste statique. Cependant il est possible d’implémenter une stratégie de partitionnement dynamique directement liée aux évolutions des données applicatives. Voici la description d’une solution de partitionnement dynamique permettant d’en faciliter l’administration.
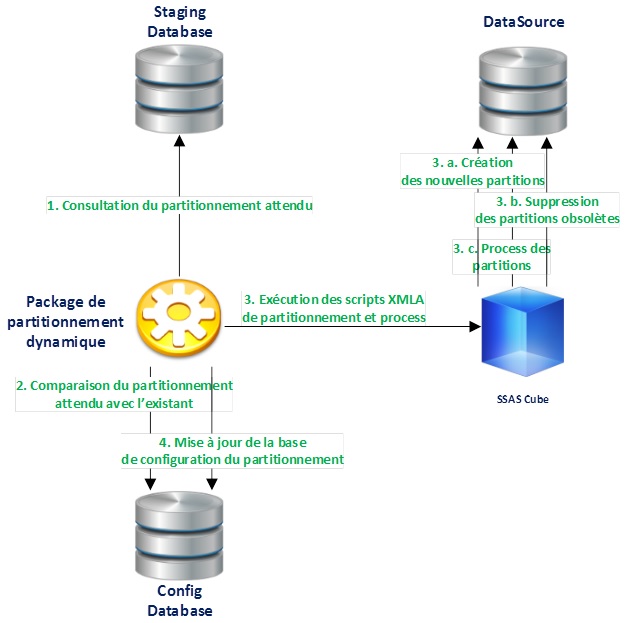
Architecture de la solution
La solution est divisée en plusieurs modules distincts :
Staging Database : Les données métiers en provenance des applications sont contenues dans des tables dites de « Staging » permettant le nettoyage et la transformation des données avant insertion dans le dataware pour consultation par le cube. Certaines tables spécifiques permettent d’identifier comment doit être réalisé le partitionnement des données.
Config Database : Contient 2 tables spécifiques au partitionnement dynamique et permettant de stocker la liste des partitions des précédentes exécutions du partitionnement dynamique ainsi que la liste du contenu de chaque partition grâce à des clés de partitionnement.
DataSource : Source de données requêtée par le cube dont certaines données seront partitionnées.
SSAS Cube : Cube analytique.
Package de partitionnement dynamique : Mécanisme permettant de gérer automatiquement et dynamiquement les partitions de données du cube SSAS. C’est un package Integration Services (SSIS) qui peut être exécuté de différentes manières (manuellement, via Job SQL, via autre package SSIS, via procédure stockée) afin d’être intégré au sein de l’administration du cube SSAS et des bases de données.
Principe de fonctionnement
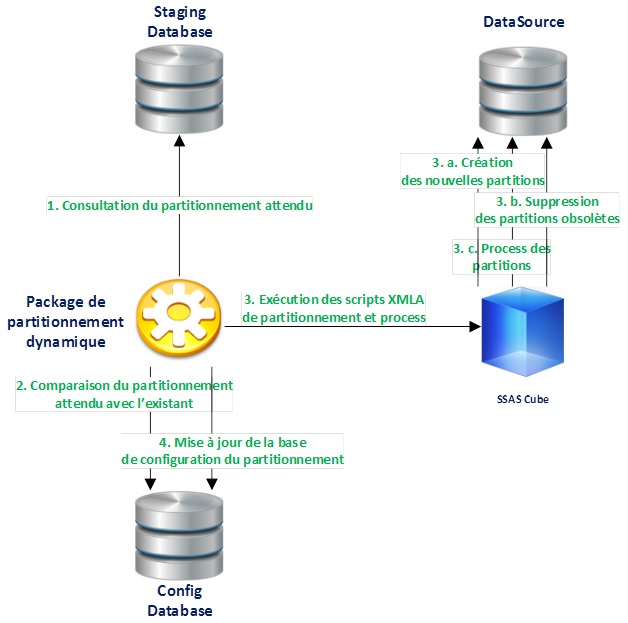
1. Le package de partitionnement dynamique consulte les données métiers au sein de la base de staging pour identifier quel est le partitionnement attendu.
2. Le partitionnement attendu est comparé avec le partitionnement existant dont les configurations sont stockées dans la base de configuration. Ces configurations sont mises à jour avec le nouveau partitionnement attendu.
3. Le package de partitionnement exécute plusieurs scripts XMLA à partir de templates prédéfinis sur le cube SSAS en fonction du contenu de la base de configuration afin de :
-
Créer les nouvelles partitions,
Supprimer les partitions obsolètes,
Processer l’ensemble des partitions nouvellement créées ou mises à jour
Remarque : les scripts XMLA peuvent être exécutés en mode batch pour une exécution en parallèle afin d’optimiser les temps de traitements des partitions (Performing Batch Operations (XMLA)).
4. En fonction du résultat de chaque script la base de données de configuration est mise à jour pour refléter l’état du partitionnement en cours d’application.
Template Scripts XMLA
Plusieurs templates de scripts XMLA sont utilisés dans la solution afin de réaliser les actions suivantes :
- Création de partitions
<Alter AllowCreate="true" ObjectExpansion="ExpandFull" xmlns="https://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
< DatabaseID ></ DatabaseID >
< CubeID ></ CubeID >
< MeasureGroupID ></ MeasureGroupID >
< PartitionOriginID ></ PartitionOriginID >
</Object>
<ObjectDefinition>
<Partition xmlns:xsd="https://www.w3.org/2001/XMLSchema" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="https://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="https://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="https://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="https://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="https://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="https://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="https://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="https://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="https://schemas.microsoft.com/analysisservices/2012/engine/400/400">
<PartitionID></PartitionID>
<PartitionName></PartitionName>
<Source xsi:type="QueryBinding">
<DataSourceID></DataSourceID>
<QueryDefinition>
SELECT [SK_ID]
,...
,[KEY_1]
,[KEY_2]
FROM [dwh].[v_Fact_Table]
where
[KEY_1] = 'KEY_1_ID'
AND [KEY_2] = 'KEY_2_ID'
</QueryDefinition>
</Source>
<StorageMode valuens="ddl200_200">InMemory</StorageMode>
<ProcessingMode>Regular</ProcessingMode>
<ddl300_300:DirectQueryUsage>InMemoryOnly</ddl300_300:DirectQueryUsage>
</Partition>
</ObjectDefinition>
</Alter>
- Suppression de partitions,
<Delete xmlns="https://schemas.microsoft.com/analysisservices/2003/engine">
<Object>
< DatabaseID ></ DatabaseID >
< CubeID ></ CubeID >
< MeasureGroupID ></ MeasureGroupID >
< PartitionID ></ PartitionID >
</Object>
</Delete>
- Process de partitions.
<Process xmlns="https://schemas.microsoft.com/analysisservices/2003/engine">
<Type>ProcessDefault</Type>
<Object>
< DatabaseID ></ DatabaseID >
< CubeID ></ CubeID >
< MeasureGroupID ></ MeasureGroupID >
< PartitionID ></ PartitionID >
</Object>
</Process>
Ces templates contiennent des balises mises à jour lors de l’exécution du package et prenant en compte les spécificités du partitionnement attendu.
Tout d’abord tous les scripts contiennent les balises ci-dessous qui seront identiques pour un groupe de mesures donné quelle que soit la partition :
CubeID : Identifiant SSAS du modèle,
DatabaseID : Identifiant SSAS de la base portant le cube,
DataSourceID : Identifiant SSAS de la source de données ciblées par le cube,
MeasureGroupID : Identifiant SSAS du groupe de mesures concernée par le partitionnement.
Et certains scripts contiennent des balises spécifiques à chaque partition :
PartitionID : Identifiant SSAS de la partition (stocké dans la base de données de configuration),
KEY_1_ID et KEY_2_ID: Identifiants des clés de partitionnement (uniquement utilisés à la création de partition).
Pour de plus amples informations sur le développement de scripts XMLA, n’hésitez pas à vous référer à l’article suivant : Developing with XMLA in Analysis Services.
Cas pratique
La solution précédemment évoquée a d’ores et déjà été mise en place chez plusieurs clients. Voici la démarche spécifique à l’un de nos clients du secteur bancaire.
Le cube mis en place chez ce client utilisait une vue relationnelle qui nécessitait un process complet du cube lors de mise à jour des données (30 million de lignes). Afin de limiter cette étape relativement coûteuse en temps et en ressources serveur, il a été identifié que la mise en place d’un partitionnement des données par silo permettrait de limiter le process du cube aux seules partitions concernées par la mise à jour des données.
En effet l’objectif du partitionnement étant de ne reconstruire qu’une portion spécifique du cube, cela permet d’accélérer l’accessibilité de l’information aux utilisateurs.
Pour ce faire, 3 tables de faits ont été partitionnées selon une clé spécifique au métier du client (2 dans les tables de fait). Ces clés de partitionnement sont gérées au sein d’une table de configuration. Ainsi, lorsque les tâches de partitionnement sont lancées, la solution identifie :
Les clés de partitionnement dont les données ont été mises à jour et nécessitant un process de leur partition,
Les nouvelles clés ajoutées et nécessitant une création de partition,
Les partitions devant être purgées.
L’application dispose ainsi d’un partitionnement dynamique correspondant aux attentes métiers du client et profitant de tous les bénéfices exposés en début d’article.
L’expertise Microsoft Consulting Services au service de ses clients
Microsoft Consulting Services vous accompagne depuis la conception de vos applications décisionnelles jusqu’à l’adaptation de vos stratégies de performances, tout en vous aidant à mieux appréhender les différents scénarios adaptés à votre métier ainsi que les best practices à adopter.
Pour plus d’informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d’informations sur les blogs « SQL Server chez les clients ».
 |
Jérôme Coquidé, Consultant Data Insights et CRM , Microsoft Consulting Services Tout d’abord consultant CRM et désormais consultant Data Insight au sein de la division Services de Microsoft j’interviens principalement sur les thématiques Business Intelligence et Reporting ainsi que l’intégration de données (Qualité de données, Gestion des données référentielles) sans oublier la Gestion de la Relation Client. |