SQL Server chez les clients – AlwaysOn pour les applications critiques

AlwaysOn, solution 2 en 1, combinant à la fois haute disponibilité et Disaster Recovery, disponible à partir de SQL Server 2012 a déjà été explicitée en vis-à-vis des autres solutions disponibles dans le précédent article d’un de mes collègues que vous pouvez avoir le plaisir de lire ou relire : https://blogs.technet.com/b/sql/archive/2013/10/30/sql-server-chez-les-clients-bien-comprendre-les-solutions-de-ha-dr.aspx
Dans quels contextes recommande-t-on l’implémentation d’AlwaysOn ?
Pourquoi AlwaysOn est une solution de haute disponibilité convenant particulièrement aux applications critiques nécessitant un niveau de disponibilité maximum, et ce notamment dans le milieu bancaire ?
Problématique
- Comprendre le mode de fonctionnement et les possibilités offertes par AlwaysOn
- Choisir une stratégie de Backup adaptée
Bénéfices
Une interface de monitoring unique pour la haute disponibilité et le Disaster Recovery
Une solution flexible offrant la possibilité de Secondaires accessibles en lecture
Une réelle valeure ajoutée dans un contexte applicatif
Glossaire
| Terme | Explication |
| DB | Database, Database Management System |
| DR | Disaster Recovery |
| HA | High Availability |
| MCS | Microsoft Clustering Services |
| OS | Operating System |
| RPO | Recovery Point Objective |
| RTO | Recovery Time Objective |
| SAN | Storage Area Network |
| WSFC | Windows Server Failover Cluster |
| FCI | Failover Cluster Instance |
| VNN | Virtual Network Name |
| DBM | Database Mirroring |
| DC | Domain Controller |
| AD | Active Directory |
| LS | Log Shipping |
| AG | Availability Groups |
| LSN | Log Sequence Number |
Comprendre l’approche d’AlwaysOn
AlwaysOn est une désignation qui englobe à la fois les fonctionnalités Availability Groups et Failover Cluster Instances de SQL Server 2012.

AlwaysOn s’appuie sur la couche logicielle WSFC. Pour l’implémenter, il faut que la couche logicielle WSFC soit déjà installée. Cela nécessite une version Enterprise pour les OS inférieurs à WS 2012.
Techniquement, il s’agit d’une fonctionnalité à activer dans SQL Server 2012 version Enterprise.
Contrairement au Database Mirroring, aucune fonctionnalité limitée d’AlwaysOn n’est disponible dans la version standard.
La couche WSFC joue le rôle que jouait le Witness / Serveur Témoin dans un contexte de Database Mirroring.
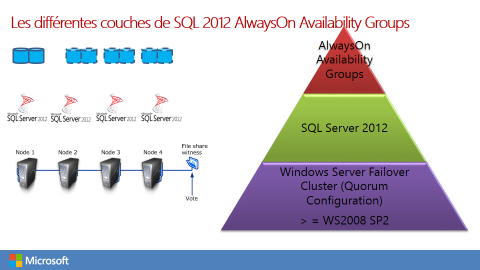
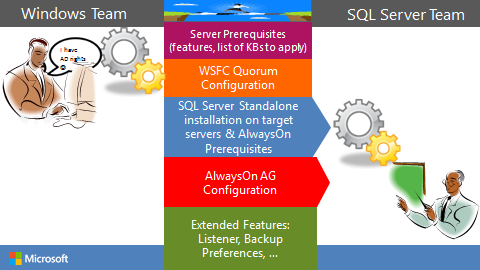
Du fait de ces différentes strates, l’implémentation d’AlwaysOn nécessite une démarche partagée entre les équipes Windows et les équipes SQL Server.
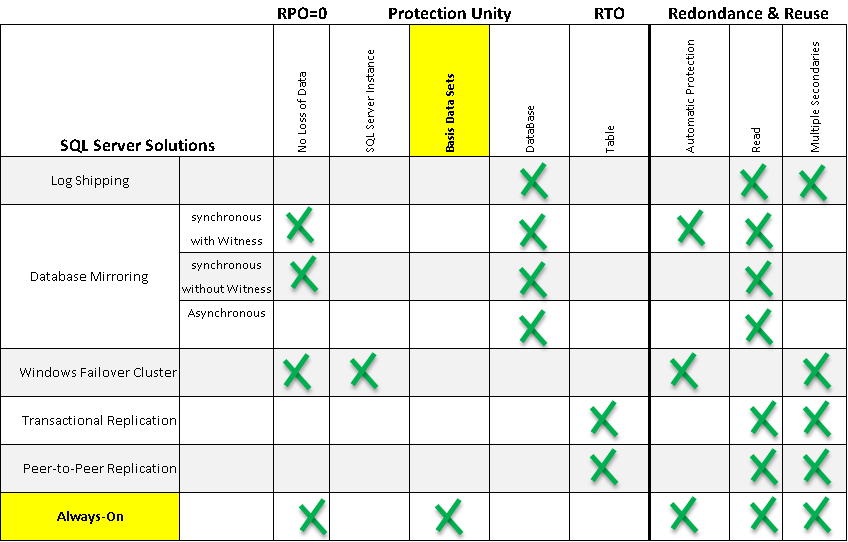
Unité de sauvegarde
AlwaysOn diffère des autres possibilités de Haute disponibilité et de DR, en cela que son unité de sauvegarde est un ensemble de bases de données et non plus une unique base de données.
AlwaysOn est donc particulièrement bien adaptée à un contexte applicatif dans lequel une application utiliserait une base de configuration, et une base de données clients.
Il semble donc tout naturel aux banques, repères gravitationnels de moult applications, dont plusieurs sont classifiées critiques et exigent une haute disponibilité de s’orienter vers AlwaysOn, plutôt que de combiner du clustering et du mirroring et/ou log shipping comme elles le faisaient auparavant.
AlwaysOn offre la possibilité de Secondaires ouverts en lecture, ce qui s’avère particulièrement intéressant pour répartir les charges de lecture, en fonction de critères géographiques par exemple.
Il est possible de sécuriser l’accès en lecture à l’un des serveurs secondaires via l’implémentation d’une « Readable Routine », qui indiquera qui est le Secondaire de lecture préféré en fonction du serveur primaire, et des disponibilités ou indisponibilités des autres serveurs secondaires, et de sécuriser la chaîne de connexion. Il faudra alors montrer patte blanche pour pouvoir passer le garde-fou à l’entrée du portail qui ouvre l’univers de la base de données.
Le schéma ci-dessous résume quel serveur l’Availability Group résoudra en fonction du paramétrage implémenté, et des paramètres de la chaîne de connexion.
Nous partons du postulat que c’est le Listener qui est indiqué dans la chaîne de connexion de l’application. Il faut bien garder à l’esprit que le Listener ne permet de résoudre qu’un seul serveur cible à la fois, c’est-à-dire le primaire, ou le secondaire de lecture préféré, défini en fonction du serveur primaire.

Exemple d’architecture logique :
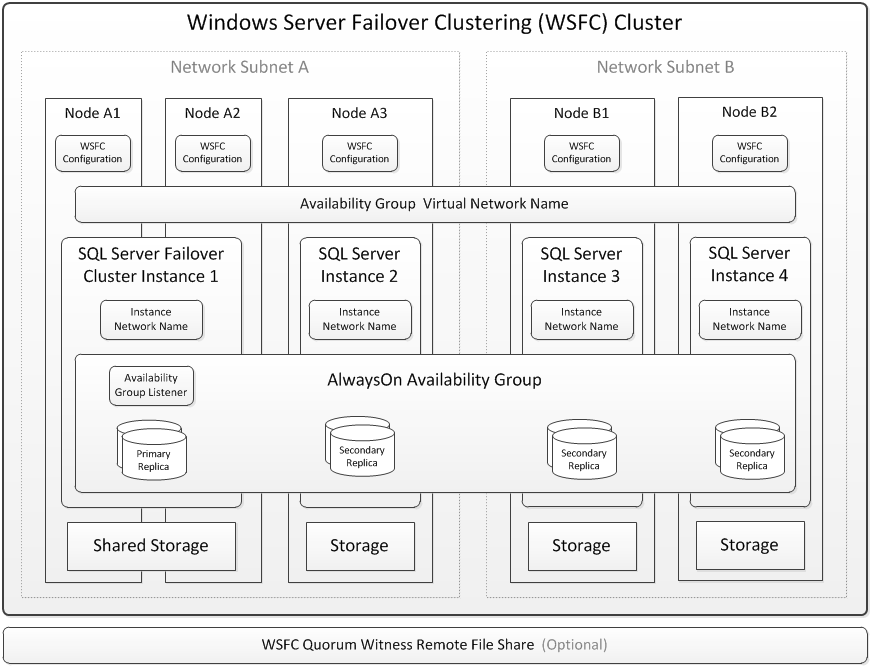
Chaque instance SQL Server en standalone est directement rattachée à un espace de stockage qui lui est propre, et les instances en cluster (FCI) disposant d’un stockage partagé pourraient être placées dans un WSFC qui pourrait s’étendre à plusieurs sous-réseaux. Il est possible d’avoir jusqu’à 5 réplicas (1 primaire et 4 secondaires) dans des datacenters locaux ou distants, en utilisant la fonctionnalité AlwaysOn AG.
L’application peut se connecter au replica primaire en utilisant l’adresse IP du listener ou le VNN qui résout le serveur primaire à un instant t et donc masque le failover à l’application tiers.
Optez plutôt pour un OS Windows Server 2012
Dans Windows Server 2012, nous bénéficions du quorum dynamique.
Le quorum dynamique est la capacité de recalculer le quorum à la volée, tout en maintenant l’activité du cluster. C’est une amélioration très importante, puisque nous sommes maintenant capables de continuer à faire fonctionner le cluster si le nombre de nœuds restants est inférieur à 50%. Cela n’était pas possible auparavant, mais le quorum dynamique nous permet maintenant de faire cela. En effet, nous pouvons réduire le cluster jusqu’à son dernier nœud (connu comme « le dernier homme debout ») et maintenir le quorum.
Le quorum dynamique permet donc une tolérance aux défaillances maximum.
Le quorum dynamique est activé par défaut et recalcule le quorum quand un ou plusieurs nœuds de ce même quorum ne répondent pas. Le quorum dynamique fonctionnera seulement si ces 2 conditions sont respectées :
1. Le cluster a déjà réalisé le quorum.
2. Des défaillances séquentielles se sont produites au niveau des nœuds
Si de multiples nœuds d’un cluster tombent au même moment, le quorum dynamique ne sera pas capable de recalculer le nombre de votes et de maintenir le cluster. En lieu et place, une recréation du groupe se produira, et une fois que le cluster aura déterminé si le quorum est maintenu, le quorum dynamique pourra de nouveau être utilisé, si les 2 conditions ci-dessus sont respectées.
| Le choix de l’OS Windows Server 2012 permet de bénéficier de cette fonctionnalité. |
Par ailleurs, Windows Server 2012 et SQL Server 2012 combinés permettent des performances optimales. En effet, Windows Server 2012 inclut des améliorations relatives au clustering.
Recommandation: Utiliser Windows Server 2012 et des réseaux dédiés pour le trafic SAN et le heartbeat du cluster. Par ailleurs, beaucoup moins de correctifs sont à appliquer sur Windows Server 2012.
Se référer au White Paper “Better Together: SQL Server 2012, Windows Server 2012, and System Center 2012 " pour de plus amples informations.
Recommandations générales
- Réplicas d’envergure similaire : garder à l’esprit que chacun des réplicas peut être amené à devenir le serveur primaire
- Espace disque suffisant
- 1 AlwaysOn Availability Group par contexte applicatif
Limites relatives au nombre d’availability groups et d’availability databases par ordinateur
Le nombre actuel de bases de données et d’availability groups maximum possibles sur un serveur dépend des hardware et workload mais il n’y a pas de limite imposée. Microsoft a testé 10 AGs et 100 DBs par machine physique. Les signes de surcharge des systèmes peuvent inclure, mais ne sont pas limités aux critères suivants :
- thread exhaustion
- lenteur des temps de réponse pour les vue systèmes AlwaysOn et DMVs
- stalled dispatcher system dumps
Il est recommandé de tester son environnement avec une charge similaire à celle de l’environnement de production pour s’assurer que la pointe de charge de travail peut être absorbée par l’application.
Les recommandations suivantes ont pour but de garantir la performance et la stabilité des AlwaysOn Availability Groups:
- Limites: 5 availability replicas per availability group
- Recommandé: 1 – 10 Availability Groups
- Recommandé: 1 – 10 Databases per Availability Group
- Recommandé: <= 100 Total Database Replicas
Log Generation Rate : Il est important de mesurer les Log Bytes Flushed/sec qui correspondent à la vitesse à laquelle les logs sont écrits sur le disque. Cela joue un rôle important dans la détermination de performance d’AlwaysOn Ce compteur est présent dans l’objet [sys].[dm_os_performance_counters]
Il est important de comparer ce nombre aux autres compteurs de performance d’AlwaysOn, comme les compteurs relatifs aux opérations « send queue » & « redo queues » Si les performances attendues ne sont pas atteintes, il sera possible d’investir dans un hardware optimisé pour l’écriture de logs, et d’améliorer les synchronisations en leur réservant un réseau heartbeat dédié.
Choisir une stratégie de backup adaptée
L’implémentation d’AlwaysOn aura des impacts sur la stratégie de backup.
Il faut bien prendre en compte les possibilités offertes, et prendre en compte le fait qu’il est impossible d’effectuer des backups différentiels sur les serveurs secondaires.

Se rappeler que les logs de tous les Réplicas forment une chaîne unique
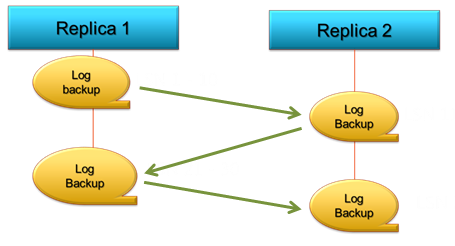
Automatiser ses Backups
Il est possible de définir via le Wizard des préférences de backup, et d’indiquer une priorité de choix parmi les réplicas.

Recommandations générales

Nous recommandons d’effectuer les backups de façon centralisée. Il faut garder à l’esprit que n’importe lequel des serveurs peut devenir le serveur préféré sur lequel les sauvegardes seront effectuées. Centraliser les backups dans un emplacement dédié, permettra de restaurer facilement un point choisi dans le temps, ce quel que soit le serveur duquel le backup cible recherché était issu.
Vous pouvez consulter l’article suivant pour de plus amples informations sur la procédure à suivre pour restaurer un point choisi dans le temps: https://blogs.msdn.com/b/sqlgardner/archive/2012/10/19/alwayson-restore-revisited.aspx
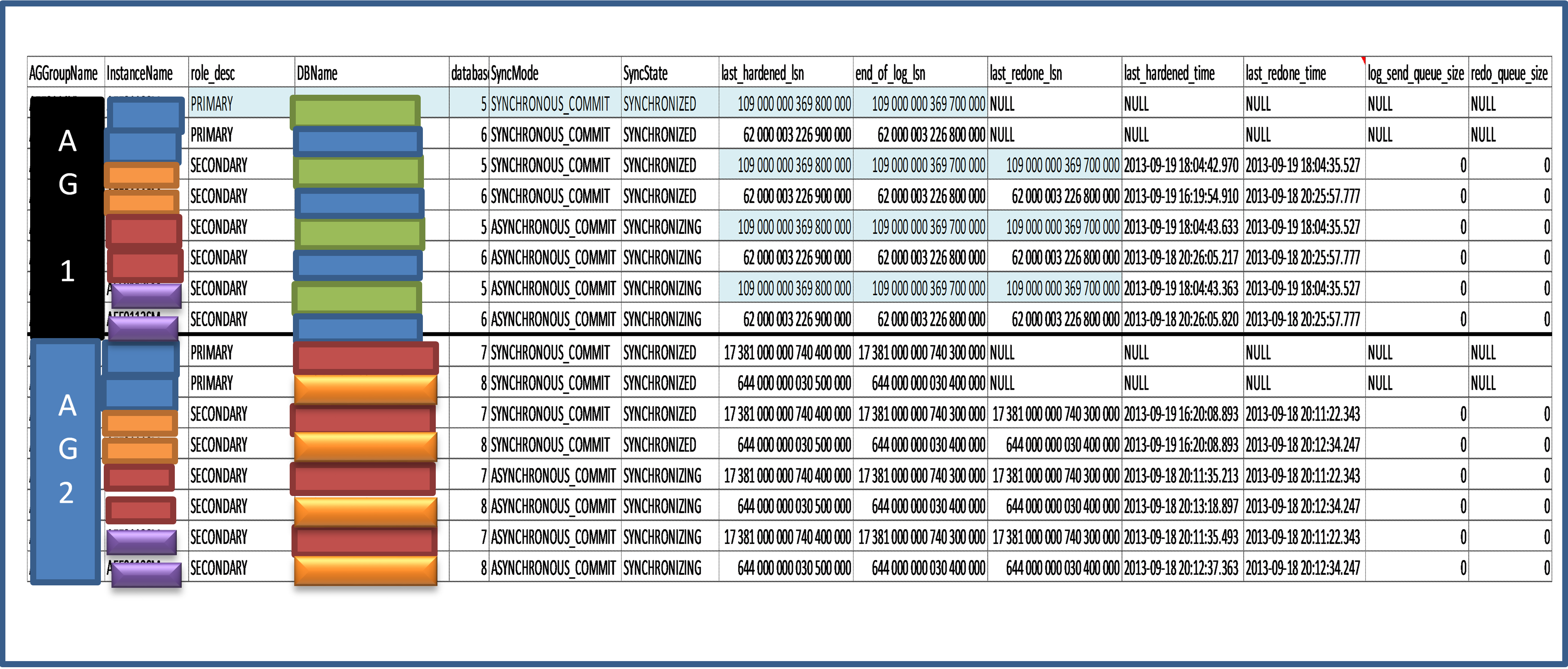
La requête suivante permet d’identifier les différentes informations utiles relatives aux Availability Groups.
SELECT ags.name as AGGroupName,
ar.replica_server_name as InstanceName,
hars.role_desc,
db_name(drs.database_id) as DBName, drs.database_id,
ar.availability_mode_desc as SyncMode,
drs.synchronization_state_desc as SyncState,
drs.last_hardened_lsn, drs.end_of_log_lsn, drs.last_redone_lsn,
drs.last_hardened_time, drs.last_redone_time,
drs.log_send_queue_size, drs.redo_queue_size
FROM sys.dm_hadr_database_replica_states drs
LEFT JOIN sys.availability_replicas ar
ON drs.replica_id = ar.replica_id
LEFT JOIN sys.availability_groups ags
ON ar.group_id = ags.group_id
LEFT JOIN sys.dm_hadr_availability_replica_states hars
ON ar.group_id = hars.group_id and ar.replica_id = hars.replica_id
ORDER BY ags.name, ar.replica_server_name, db_name(drs.database_id)
Colonne |
Type |
Explication |
|---|---|---|
last_hardened_lsn |
numeric(25,0) |
Début du bloc de journal contenant les enregistrements de journal du LSN de dernière sécurisation renforcée sur une base de données secondaire. Sur une base de données principale avec validation asynchrone ou sur une base de données avec validation synchrone dont la stratégie actuelle est « delay », la valeur est NULL. Pour les autres bases de données principales avec validation synchrone, last_hardened_lsn indique la valeur minimale de LSN renforcé dans toutes les bases de données secondaires. Remarque last_hardened_lsn reflète un ID de bloc de journal complété avec des zéros. Il ne s'agit pas d'un numéro séquentiel réel dans le journal. Pour plus d'informations, consultez Présentation des valeurs de colonne de numéro séquentiel dans le journal, plus loin dans cette rubrique. |
end_of_log_lsn |
numeric(25,0) |
LSN de fin de journal local. Numéro séquentiel réel dans le journal correspondant au dernier enregistrement du journal dans le cache du journal sur les bases de données primaire et secondaire. Sur le réplica principal, les lignes secondaires reflètent le LSN de fin de journal, depuis les derniers messages de progression que les réplicas secondaires ont envoyés au réplica principal. end_of_log_lsn reflète un ID de bloc de journal complété avec des zéros. Il ne s'agit pas d'un numéro séquentiel réel dans le journal. Pour plus d'informations, consultez Présentation des valeurs de colonne de numéro séquentiel dans le journal, plus loin dans cette rubrique. |
last_redone_lsn |
numeric(25,0) |
Numéro séquentiel dans le journal réel du dernier enregistrement du journal qui a été restauré sur la base de données secondaire. last_redone_lsn est toujours inférieur à last_hardened_lsn. |
last_hardened_time |
datetime |
Sur une base de données secondaire, heure de l'identificateur de bloc de journal pour le LSN de dernière sécurisation renforcée (last_hardened_lsn). Sur une base de données principale, reflète l'heure correspondant à la valeur minimale de LSN renforcé. |
last_redone_time |
datetime |
Heure à laquelle le dernier enregistrement du journal a été restauré sur la base de données secondaire. |
log_send_queue_size |
bigint |
Quantité d'enregistrements du journal dans la base de données principale, en kilo-octets (Ko), qui n'a pas encore été envoyée aux bases de données secondaires. |
redo_queue_size |
bigint |
Quantité d'enregistrements du journal dans les fichiers journaux du réplica secondaire qui n'a pas encore été réexécutée, en kilo-octets (Ko). |
synchronization_state_desc |
nvarchar(60) |
Description de l'état de déplacement des données, un des suivants : NOT SYNCHRONIZING SYNCHRONIZING SYNCHRONIZED REVERTING INITIALIZING |
Référence : https://msdn.microsoft.com/fr-fr/library/ff877972.aspx
L’expertise Microsoft Consulting Services au service de ses clients
MCS propose une offre de service packagée pour vous aider à implémenter AlwaysOn dans votre environnement. Il est possible de procéder de prime abord en mode POC (Proof Of Concept) afin de valider vos attentes vis-à-vis de la solution.
La solution AlwaysOn a notamment été implémentée en France dans
- Plusieurs grandes banques françaises
- Des entreprises spécialisées dans la livraison de produits à domicile, afin de garantir la haute disponibilité de leur application CRM
- Des entreprises proposant des services Cloud à leurs clients sur des applications critiques.
Cette offre de service peut aussi bien être mise en œuvre dans le cadre d’un projet géré par Microsoft Services, que dans le cadre d’une assistance technique sur certains aspects du projet (architecture du cluster Windows, validation de la stratégie d’utilisation, performances améliorées par l’utilisation d’un réseau heartbeat dédié pour les synchronisations des bases d’un AlwaysOn Availability Group …).
Nous vous accompagnons depuis l’implémentation d’AlwaysOn dans votre environnement, tout en vous aidant à mieux appréhender cette solution, jusqu’à l’adaptation de vos stratégies de monitoring et de backup.
Pour plus d’informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d’informations sur les blogs « SQL Server chez les clients ».
 |
Sophie Bismuth, Consultante BI/SQL &Dynamics CRM, Microsoft Consulting Services J’interviens dans le cadre de projets décisionnels s’articulant autour de la stack BI de Microsoft ou d’une brique Dynamics CRM. J’aborde également les thématiques d’architecture, de Disaster Recovery et d’optimisations de performance. |