SharePoint Server 2013 の検索アーキテクチャ
みなさんこんにちは。
SharePoint サポートチームの荒川です。
今日は新しくなった SharePoint Server 2013 の検索アーキテクチャについてご紹介します。
SharePoint Server 2013 で大幅に変更された検索アーキテクチャ
SharePoint Server 2013 の大きな変更点の一つとして、サーチエンジンの刷新が挙げられます。アーキテクチャとしてこれまでの機能を一部残していますが、殆ど別物といっても過言ではありません。トポロジの変更も従来のように管理 UI から気軽に行えなくなっていますし、運用中に気軽にトポロジ変更したりもできなくなっていますので、検索アーキテクチャをしっかりと理解して、十分な計画のもとに実装する必要があります。
SharePoint 検索エンジンの歴史
従来の SharePoint 検索エンジンは、元々がシングルサーバーのシステムである MS Search 2.0、Microsoft Desktop Search から発展したシステムでした。このため、どちらかというと箱庭的な環境で使う分には管理性もよく使いやすいという反面、大規模なシステムになると耐障害性やパフォーマンスという観点ではさらなる機能の向上が求められる場面がありました。
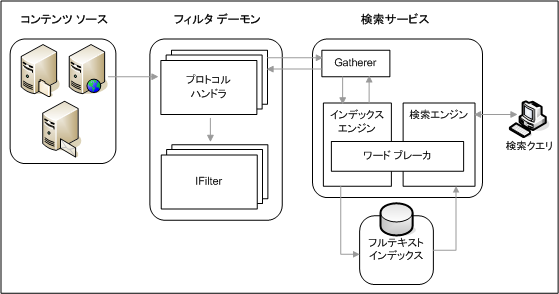
図:SharePoint Portal Server 2003 の検索アーキテクチャ
そうした背景を受け、FAST Search Server 2010 for SharePoint では、SharePoint Server 2010 の検索機能と統合能力に加えて、プラットフォームとしての柔軟性とスケーラビリティをいっそう高めると共に、高度なコンテンツ処理機能が提供されました。
SharePoint Server 2010 の検索機能とより密接な統合が可能になったことに加え、プラットフォームとしての柔軟性とスケーラビリティが大幅に向上し、コンテンツ処理コンポーネントやクエリ処理コンポーネント、ホストコントローラによるノード単位でのコンポーネントの実行など、SharePoint Server 2013 の検索アーキテクチャの基盤となる仕組みが導入されています。
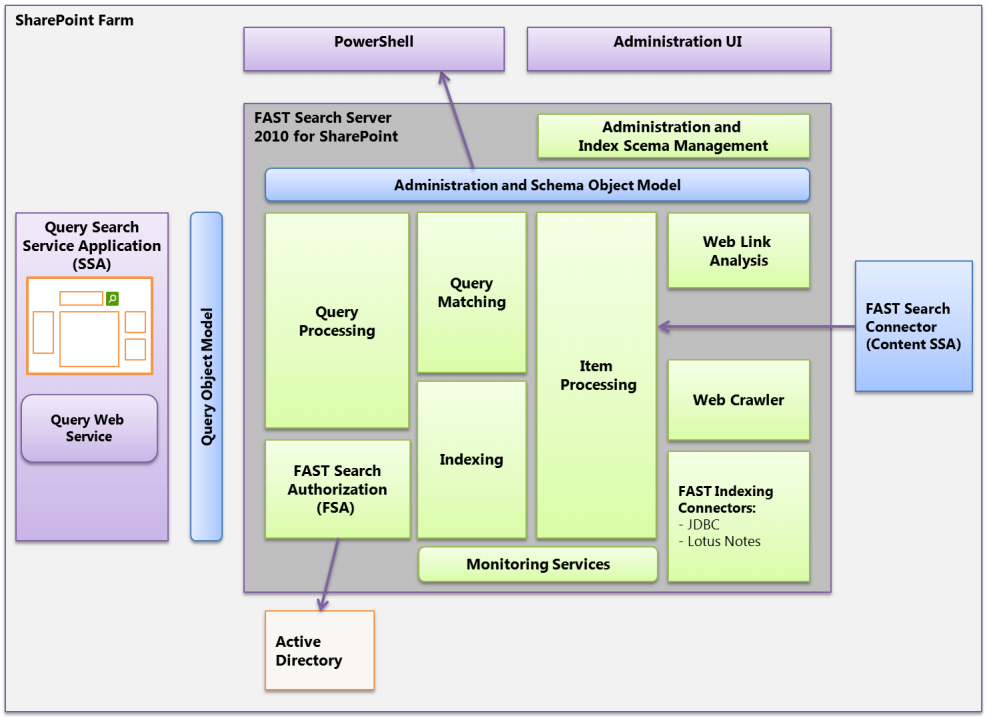
図:FAST Search Server 2010 for SharePoint の検索アーキテクチャ
FAST の長所は非常に大規模なシステムを構築できる点にありますが、構築の難易度が高いという反面もありました。現在リリースされている SharePoint Server 2013 の検索アーキテクチャでは FAST Search Server の仕組みと、これまでの SharePoint Search の仕組みが融合された新しい検索エンジンが採用されています。
SharePoint Server 2013 の検索コンポーネント モデル
下の図は、SharePoint Server 2013 の検索コンポーネント モデルを表したものです。
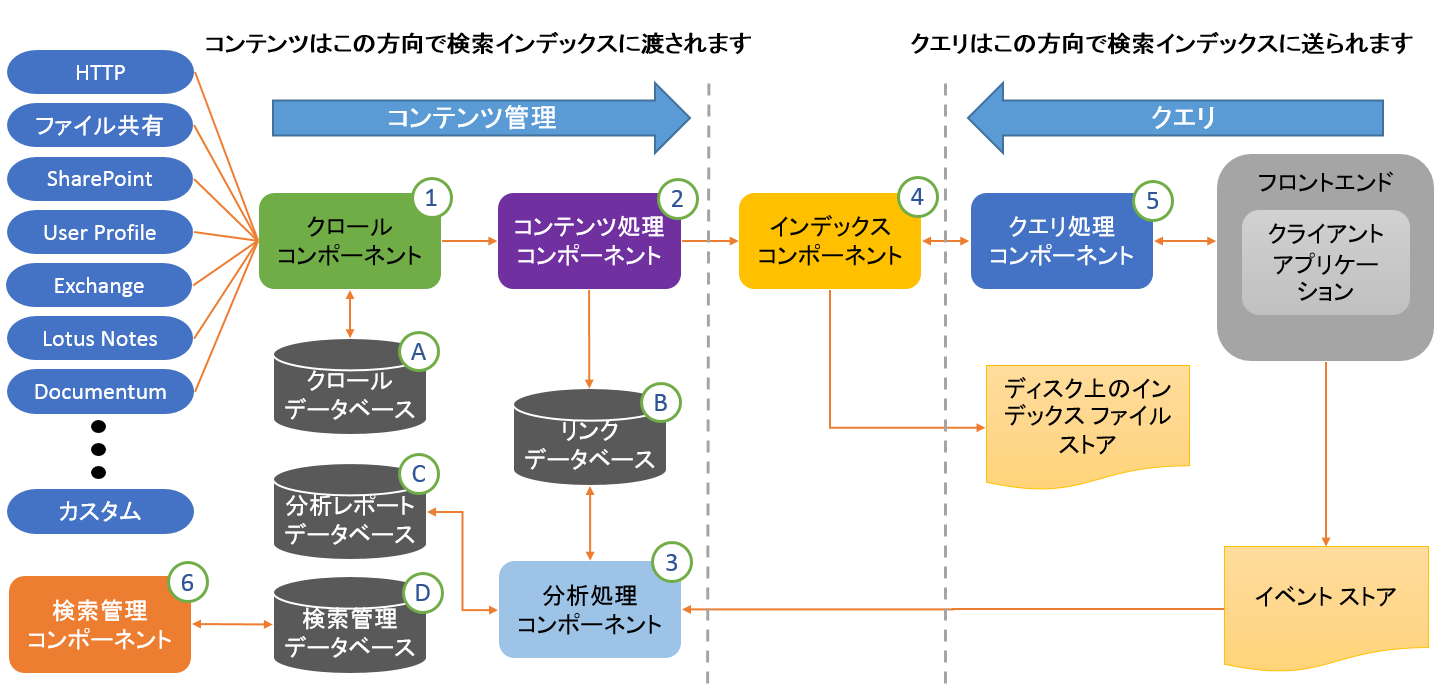
以下に、各プロセスごとに関連する検索コンポーネントの役割について解説します。
※上の図の各コンポーネントに付けられている数字、アルファベットは、後述の説明にあるものと対応しています。
クロールおよびコンテンツ プロセス
クロールおよびコンテンツ処理アーキテクチャには、クロール コンポーネント、クロール データベース、およびコンテンツ処理コンポーネントが含まれます。これらのコンポーネントは、両方とも、クロールの量とパフォーマンスの要件に基づいてスケール アウトできます。
1. クロール コンポーネント
・クロール コンポーネントは、クロール データベースで指定された情報に基づいてコンテンツ ソースのクロールを行います。クロール コンポーネントは、コンテンツ処理コンポーネントに、クロールされたアイテム (実際のコンテンツと、関連付けられたメタデータの両方) を送ります。
・クロール コンポーネントは、コンテンツ ソースを操作してデータを取得するコネクタ、またはプロトコル ハンドラーを呼び出します。複数のクロール コンポーネントを、同時にクロールするよう展開できます。
・クロール コンポーネントは、1 つまたは複数のクロール データベースを使用し、クロールされたアイテムについての情報を一時的に保存して、クロール履歴を追跡管理します。
・容量とクロールパフォーマンスを上げるには、クロール コンポーネントを追加します。
A. クロール データベース
・クロール データベースには、クロールされたアイテムの詳細な追跡および履歴情報が含まれます。
・このデータベースには、最後にクロールした時間、最後にクロールした ID、最後のクロール中に行われた更新の種類のような情報が含まれます。
・各クロール データベースには 1 つまたは複数のクローラーが関連付けられています。
2. コンテンツ処理コンポーネント
・コンテンツ処理コンポーネントは、クロール コンポーネントとインデックス コンポーネントの間に位置します。クロールされたアイテムを処理して、これらのアイテムをインデックス コンポーネントに渡します。
・コンテンツ処理コンポーネントは、ドキュメント解析とプロパティ マッピングのような処理を実行して、クロールしたアイテムを、検索インデックスに含めることができる成果物に変換します。
・コンテンツ処理コンポーネントとクエリ処理コンポーネントの両方が、言語学的処理を実行します。コンテンツ処理中の言語学的処理の例は、言語検出とエンティティ抽出です。
・コンテンツ処理コンポーネントは、リンクと URL の情報をリンク データベースに書き込みます。その一方で、分析処理コンポーネントは、コンテ
ンツ処理コンポーネント経由で、これらのリンクと URL の関連性についての情報を検索インデックスに書き込みます。
インデックスおよびクエリ プロセス
インデックスおよびクエリ アーキテクチャには、インデックス コンポーネント、インデックス パーティション、およびクエリ処理コンポーネントが含まれます。これらすべては、コンテンツ ボリューム、クエリ ボリューム、およびパフォーマンス要件に基づいて、スケール アウトできます。
4. インデックス コンポーネント
・インデックス コンポーネントは、インデックス レプリカの論理表現です。検索アーキテクチャでは、各インデックス レプリカについて 1 つのインデックス コンポーネントを準備する必要があります。
・インデックス コンポーネントはコンテンツ処理コンポーネントから処理されたアイテムを受け取って、それらのアイテムをインデックス ファイルに書き込みます。
・インデックス コンポーネントはクエリ処理コンポーネントからクエリを受け取り、その代わりに結果セットを渡します。
・クエリは、クエリ処理コンポーネント経由でインデックス レプリカに送られます。システムは、インデックス レプリカに着信したクエリを送り、負荷分散します。
・インデックスは、インデックス パーティションと呼ばれる別々の部分に分割できます。各インデックス パーティションには、インデックスの異なる部分が含まれます。検索インデックスは、すべてのインデックス パーティションの集合体です。インデックス パーティションは、ディスク上の一連のファイルに保存されます。
・検索インデックスは、以下の 2 つの方向に規模調整できます。
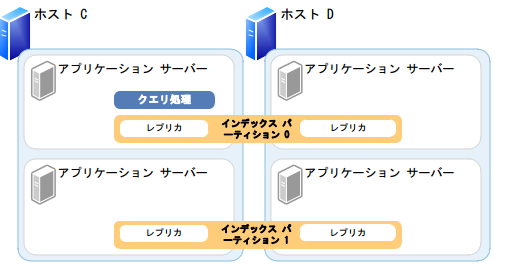
インデックス レプリカ
・インデックス レプリカは、クエリ負荷またはフォールト トレランスの需要に従ってインデックス パーティションに追加できます。各インデックス パーティションは、1 つまたは複数のインデックス レプリカを持っています。インデックス パーティション内の、各インデックス レプリカは同じ情報を持っています。たとえば、ファームに 1 つのインデックス パーティションがあるとします。このインデックス パーティションには、3 つのインデックス レプリカが含まれ、各インデックス レプリカはクエリ全体の 3 分の 1 に対して機能します。
・各インデックス レプリカについて 1 つのインデックス コンポーネントを準備する必要があります。
・フォールト トレランスと冗長性を実現するには、各インデックス パーティション用に追加のインデックス レプリカを作成し、複数のアプリケーション サーバー上でインデックス レプリカを配布します。
インデックス パーティション
・コンテンツ ボリュームが増大した場合は、それを処理できるようにインデックス パーティションを追加できます。たとえば、3 つのインデックス パーティションがあるファームでは、各インデックス パーティションにインデックスの 1/3 が含まれます。通常は検索インデックスで 1 千万のアイテムごとに 1 つのインデックス パーティションを追加することを推奨しています。
・各インデックス パーティションには、同じ情報を含む 1 つまたは複数のインデックス レプリカが含まれます。
5. クエリ処理コンポーネント
・クエリ処理コンポーネントは、検索フロントエンド コンポーネントとインデックスコンポーネントの間に位置します。
・クエリ処理コンポーネントは、検索クエリおよび結果を分析、処理します。
・クエリ処理コンポーネントとコンテンツ処理コンポーネントの両方が、言語学的処理を実行します。クエリ処理中の言語学的処理の例は、単語区切り処理とステミングです。
・クエリ処理コンポーネントは、検索フロント エンドからクエリを受け取ったとき、正確さ、再現率、および関連性を最適化する目的で、クエリを分析して、処理します。次に、処理されたクエリは、インデックス コンポーネントに送信されます。
・インデックス コンポーネントは、処理されたクエリに基づく結果セットを、クエリ処理コンポーネントに戻します。一方で、クエリ処理コンポーネントは、その結果セットを処理してから、検索フロント エンドにそれを戻します。
分析プロセス
分析アーキテクチャは、分析処理コンポーネント、分析レポート データベース、およびリンク データベースから構成されます。
3. 分析処理コンポーネント
・分析処理コンポーネントは、クロールされたアイテムの分析 (検索分析) と、ユーザーが検索結果をどう操作するかの分析 (利用状況分析) を行います。その情報を使用して、検索関連性を向上し、検索レポート、おすすめ候補、およびディープ リンクを作成します。
・このコンポーネントは以下を抽出します。
検索分析情報
リンク、アンカーテキスト、人に関連する情報、メタデータなどで、これらは、分析処理コンポーネントが、コンテンツ処理コンポーネント経由で受信したアイテムから抽出します。情報は、未処理のままリンク データベースに保存されます。
利用状況分析情報
フロント エンドからイベントストア経由で取得されたアイテムの表示回数などです。
・分析処理コンポーネントは、上記の両方の種類の情報を分析します。次に、分析結果は、検索インデックスに含まれるように (部分的な更新を使用して) コンテンツ処理コンポーネントに戻されます。さらに、利用状況分析からの結果は、分析レポート データベースに保存されます。
B. リンク データベース
リンク データベースは、コンテンツ処理コンポーネントによって抽出された情報を保存します。さらに、検索クリックについての情報を保存します。これは、ユーザーが検索結果ページから検索結果をクリックした回数です。この情報は未処理のまま保存されます。分析処理コンポーネントは分析を行います。
C. 分析レポート データベース
・分析レポート データベースは利用状況分析の結果を保存します。
・さらに、分析レポート データベースは、さまざまな分析からの統計情報を保存します。SharePoint は、この情報を使用して、さまざまな統計を示す Excel レポートを作成します。
検索管理
検索管理は、検索管理コンポーネントとそれに対応するデータベースから構成されます。
検索管理コンポーネント
・検索管理コンポーネントは、検索で重要なさまざまなシステム プロセスを実行します。
・このコンポーネントは、準備を行います。準備とは、その他の検索コンポーネントから追加のインスタンスを追加して、初期化することです。
・Search Service アプリケーションごとに、1 つの検索管理コンポーネントをアクティブにできます。
検索管理データベース
・検索管理データベースは、トポロジ、クロール ルール、クエリ ルール、およびクロールされたプロパティと管理プロパティ間のマッピングのような、検索構成データを保存します。
・検索管理データベースは、各 Search Service アプリケーションに 1 つのみ存在します。
SharePoint Server 2013 の検索トポロジ モデル
SharePoint Server 2013 ではシステムの要求に応じて柔軟に検索トポロジを構成できます。
下の図は、アイテムが 1,000 万個以下の小規模ファームに対応した検索トポロジの例です。
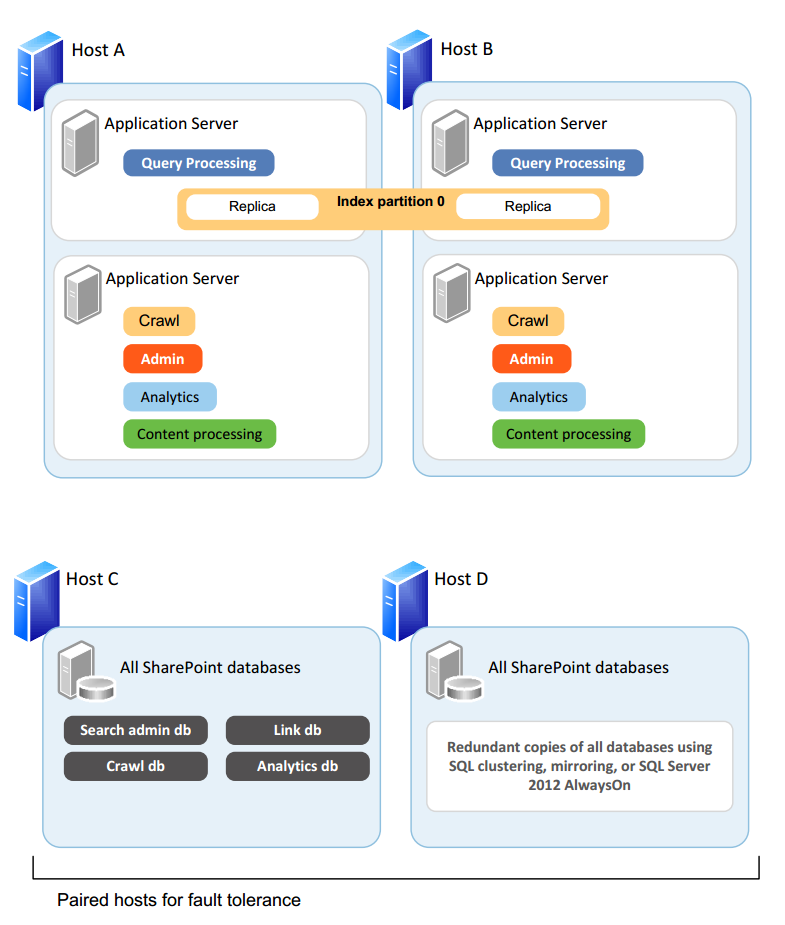
上記の例では、クエリの役割と検索管理、クロールの役割でサーバーを分けて、すべての検索コンポーネントで冗長性を持たせています。
また、以下は、最大 4 千万アイテムの検索に対応したエンタープライズ検索用の多目的フォールト トレラント ファームの例です。
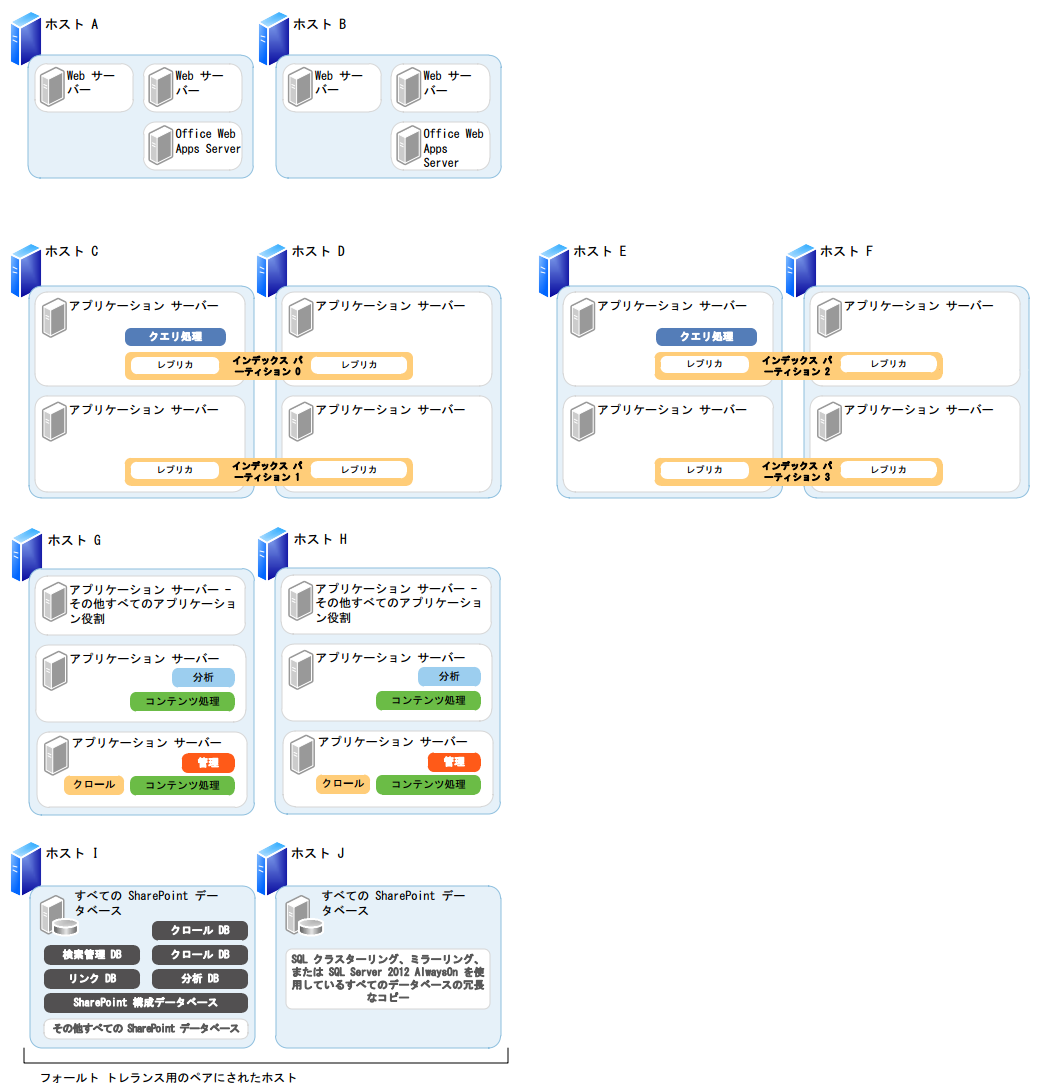
検索トポロジの構成方法についてここでは詳しく述べませんが、要点のみ以下にまとめておきます。
・SharePoint Server 2013 をインストールして Search Service アプリケーションを作成した直後は、Search Service アプリケーションが既定の検索トポロジで作成されています。既定の検索トポロジでは、すべての検索コンポーネントは、サーバーの全体管理をホストするサーバー上にあります。
・SharePoint Server 2013 では検索トポロジを変更するためのユーザー インターフェイスが提供されておらず、すべての操作は PowerShell から行う必要があります。
具体的な手順等については、後述の参考資料「SharePoint Serever 2013 で検索トポロジを管理する」に記載されていますので、そちらをご参照ください。
参考資料
以下の Technet カテゴリには、検索機能を計画する際に役に立つ情報が集約されていますのでご参考ください。
タイトル:検索の新機能 (SharePoint Server 2013)
URL :https://technet.microsoft.com/ja-jp/library/ee667266.aspx
タイトル:SharePoint Server 2013 で検索を計画する
URL :https://technet.microsoft.com/ja-jp/library/cc263400.aspx
以下の Technet カテゴリには、実際に Search Service アプリケーションを作成および構成する際に役に立つ情報が集約されていますのでご参考ください。
タイトル:SharePoint Server 2013 で Search Service アプリケーションを作成および構成する
URL :https://technet.microsoft.com/ja-jp/library/gg502597.aspx
タイトル:SharePoint Serever 2013 で検索トポロジを管理する
URL :https://technet.microsoft.com/ja-jp/library/jj219705.aspx
タイトル:SharePoint 2013 のアーキテクチャの設計 (IT 担当者)
URL :https://technet.microsoft.com/ja-jp/sharepoint/fp123594.aspx
タイトル:Enterprise search architectures for SharePoint Server 2013
URL :https://www.microsoft.com/en-us/download/details.aspx?id=30383
タイトル:Internet sites search architectures for SharePoint Server 2013
URL :https://www.microsoft.com/en-us/download/details.aspx?id=30464
タイトル:SharePoint Server 2013 の検索アーキテクチャ
URL :https://www.microsoft.com/ja-jp/download/details.aspx?id=30374
以下の資料では、SharePoint Server 2013 の既知の問題について報告されていますが、本稿と関連する情報として、検索トポロジの構成時に New-SPEnterpriseSearchIndexComponent が、誤ったサーバーで RootDirectory の存在を確認する問題が取り上げられています。対処方法についても記載がありますのでこちらも併せてご参考ください。
タイトル:SharePoint Server 2013 の既知の問題
URL :https://office.microsoft.com/ja-jp/help/HA102919021.aspx