SharePoint の検索アーキテクチャ (
みなさんお久しぶりです。
SharePoint サポートチームの荒川です。
最近ブログの更新が途絶えていましたが、ちゃんと生きてますのでご安心ください。
今回は、検索のアーキテクチャをざっくりと解説したいと思います。
ざっくりと書きましたが結構長いです。長いですが、基本的な部分は押さえたつもりですので、興味がある方は、ぜひ時間があるときにご一読いただければと思います。
なお、この記事では、極力わかりやすく説明することを目的としていますので、あまり堅苦しい言い回しはしません。予めご容赦くださいませ。
クロールコンポーネントの概要
早速ですが、SPS2010 までの検索コンポーネント (クロール) のアーキテクチャを図にまとめてみました。
およそのイメージで表すとのような感じになります。(SPS2013はまた少し変わっているのですが、それはまた別の機会に記事にします。)
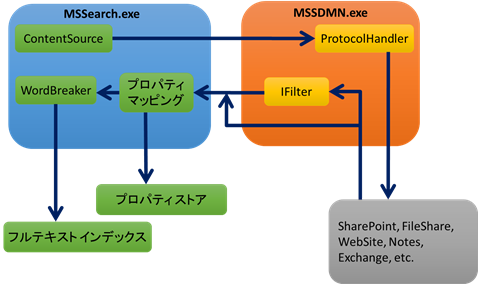
クロールのメインプロセスは mssearch.exe です。Windows サービス名は以下となります。
MOSS2007 ・・・ Office SharePoint Server Search
WSS3.0 ・・・ Windows SharePoint Services Search
SPS2010 ・・・ SharePoint Server Search 14
SPF2010 ・・・ SharePoint Foundation Search V4
この mssearch.exe はいわば司令塔のような役割を果たし、コンテンツソースを管理したり、インデックスファイルを作ったりしています。
mssdmn.exe はフィルタ デーモン プロセスと呼ばれ、mssearch.exe の部下のようなプロセスです。mssdmn.exe は mssearch.exe から指令を受けて、実際にコンテンツを取りに行って、取ってきたコンテンツの中身 (テキスト情報) を mssearch.exe に渡します。
なぜ mssearch.exe が自分でコンテンツを取りに行かないかというと、コンテンツを取りに行く作業はとても危険な作業だからです。
世の中には https:// や FTP://、File:// といった多種多様なプロトコルに溢れていますので、こういうプロトコルを色々と処理 (ハンドル) しなければなりません。また、取得されたコンテンツは多種多様なアプリケーションによって作成されていますので、ファイルの種類に応じて適切なフィルタリング処理を行い、テキスト情報だけを抽出する必要があります。このような処理はプロトコル ハンドラーや IFilter といったモジュールで実行されますが、この部分のプログラムに不具合があるとアプリケーションがクラッシュしてしまいますので、そういう危ない作業はすべて、部下である mssdmn が引き受け、最悪何か問題があっても mssdmn が犠牲となることで司令塔である mssearch.exe は守られる仕組みになっています。
SharePoint コンテンツのクロールの内部動作概要
ここで実際のクロール動作を解説します。
色々なプロトコルがありますが、今回はもっとも一般的な SharePoint サイトのクロールを例に説明します。
1. クローラー (mssearch.exe) はコンテンツ ソースの開始アドレスの指示に従ってクロール処理を開始する。
2. クロール対象の URL をフィルタ デーモン プロセス (mssdmn.exe) に渡す。
3. 対象が SharePoint サイトであると判断されると、SharePoint 用のプロトコルハンドラーが呼び出される。
4. SharePoint プロトコルハンドラーは Web フロントエンドサーバーの Site Data Web サービスと通信して、すべてのクロール対象コンテンツの URL 情報を取得する。
5. クローラーは取得した URL の一覧をクロール キュー (検索 データベース) に格納する。
6. クローラーはクロールキューからクロール対象となるコンテンツの URL を取得してフィルタ デーモン プロセスに引き渡し、フィルタ デーモン プロセスでは HTTP (HTTPS) プロトコル ハンドラーを経由してコンテンツのデータを取得する。
7. フィルタ デーモン プロセスはコンテンツの種類に対応した IFilter を使用してデータを解析処理する。
8. 解析されたテキスト データがクローラーに渡される。
9. クローラーは取得されたテキスト情報をもとに検索インデックスを作成する。
このように、クロール処理の裏では実に様々なことが行われています。
検索インデックスの作成処理
さて、コンテンツのテキスト情報が取得できたところで、今度はインデックスの作成処理に着目してみましょう。
インデックスの作成処理では、主に以下の 2 つのことが行われます。
・プロパティストアへのメタ情報の格納
・物理インデックス ファイルへのフルテキスト インデックス情報の格納
SPS2010 までの検索アーキテクチャでは、検索に関するデータを検索データベース (プロパティストア) と物理ファイルの両方に格納します。
プロパティストアには、ファイル名や更新者、タイトルといったドキュメントのプロパティ情報が格納されており、高度な検索オプションなどから利用できるプロパティ検索に利用されます。
物理インデックス ファイルには、全文検索で使用されるドキュメントの本文の情報が格納されます。
プロパティストアへのデータ格納は、クローラーの拡張プラグインである Search Archival Plugin (ARPI) で行われています。この部分はあまりトラブルにならないところなので、今回は特に掘り下げませんが、要はプロパティストアにプロパティデータを格納しているとだけ把握しておけばよいでしょう。物理インデックス ファイルは、同じくクローラーの拡張プラグインである Indexer Plug-in によって作成されます。
物理インデックスには、フルテキストのインデックスデータが格納されています。このデータはトークンと呼ばれる単位で処理され、キーワード検索を実行するにあたり最適化された形式で格納されています。
ワード ブレーカーの動作
ここで、検索時に使用されるトークンについて少し触れておきたいと思います。
フィルター デーモン プロセスより渡されたテキストデータは、mssearch.exe プロセスによりロードされているワード ブレーカーと呼ばれるモジュールで、ワード ブレーク処理されます。ワード ブレークとは、形態素解析と呼ばれる技術で単語として意味を成す最小単位である形態素 (トークンとも呼ばれます) に切り出す (ブレークする) 処理のことです。クロール処理では、このようにしてトークンに分割されたデータが、インデックスファイルに物理的に格納されることになります。
ワード ブレーカーは様々な国の言語用に開発されており、日本語環境の SharePoint では当然日本語のワードブレーカーがメインで使用されます。日本語ワードブレーカーで解決できないものはひとまずニュートラル ワード ブレーカーという、英語圏と同じワード ブレーカーが使用される仕組みになっています。
ワード ブレーク処理では、表記の揺らぎ補正や単語の一般化などが実行されますが、英語圏の場合は大抵はスペースで一単語を区切ることができるので楽なのですが、日本語をはじめ2バイト文字圏ではそういうわけにもいかないので、ワード ブレーク処理がとても複雑になる傾向にあります。
形態素解析については、SharePoint の専門用語ではなく、一般的な検索アルゴリズムでも使用されている、自然言語処理の基礎技術のひとつで、これだけで本が何冊もかけるくらい深い話になりますので、ここでは掘り下げません。
最終的に、このようにしてトークン化された文字列情報がインデックスに格納され、検索時にはクロール時と同等の方法でトークン化されたキーワードが物理ファイルと照会されることで、検索結果を素早く返すことができる仕組みになっています。
クロール時のワード ブレーク処理と検索時のワード ブレーク処理の違い
さて、ここまでの説明で、既にお気づきの方もおられるかもしれませんが、SharePoint では、クロールの時と、検索のときで同じ言語でワード ブレーク処理をしなければ検索結果が正しくなくなることに注意が必要です。
一般的に、検索結果が正しくないという問題に遭遇した時、初めに考えられる可能性は次の 3 つです。
・クロールに失敗している
・検索対象コンテンツへのアクセス権が無い、または無いことになっている。
・検索時のキーワードがインデックスのデータと一致しない
クロールに失敗していれば当然検索できません。一般的にこの問題はクロールログを分析することで検出できます。
検索対象コンテンツへのアクセス権がない場合も、検索結果にヒットしません。例えば、アクセス権をグループ単位で与えていてそのグループに所属するユーザーが変更された場合は即座に最新のアクセス権が反映されるため、最新のアクセス権に基づく検索結果が得られます。しかし、アイテムに対して直接ユーザー等のアクセス権が割り当てられている状況でアクセス権を変更した場合は、増分クロールを行うまで検索インデックスに含まれるコンテンツのアクセス権情報が更新されませんので、検索結果にコンテンツがヒットしないことがあります。このあたりの動きについては、以前に別の記事で紹介していますので、そちらをご参考ください。
最後に、検索時のキーワードがインデックスのデータと一致しない場合ですが、この問題は多言語の環境で比較的よく発生します。SharePoint では以下の例に示す情報を利用して、クロール時に使用するワード ブレーカーを選択します。
・サイトの言語設定
・Office ドキュメントが独自に持っているロケール情報
・HTML ファイルに含まれるエンコード指定
・Unicode テキストに含まれるバイトオーダーマーク
・上記で解決できない場合は、最終的にインデックスサーバーの OS のシステム ロケールを確認して適切なワード ブレーカーを判断
クエリに使用されるワード ブレーカーの検出の仕組みは単純です。ユーザーが検索クエリを実行するときに、検索文字列に対して使用されるワード ブレーカーはクライアントのブラウザの言語設定に依存します。具体的には、IE のインターネット オプションの [言語] の設定です。
たとえば、日本語環境のサイトに中国語で書かれたドキュメントがアップロードされていたりすると、本来中国語でワード ブレークしてほしいところを誤って日本語で処理してしまうことがあります。この場合、ブラウザの言語設定が日本語の環境では、問題なく検索結果が表示されますが、ブラウザの言語設定が中国語の環境では、キーワードが「正しく」ワード ブレーク処理されてしまうことにより、想定された結果が得られないという事態が発生します。同様に、日本語の SharePoint 環境に言語設定が英語に設定された IE で接続した場合もキーワードによっては正しい検索結果が得られないことがあります。
たとえば、「今日はとてもいい天気です」という文字列を日本語と中国語のワード ブレーカーで処理した場合、次のような違いが生じます。
・LCID 1041 日本語 のワード ブレーカーでワード ブレークした場合
今日は / とても / いい / 天気 / です
・LCID 1028 中国語 (台湾) のワード ブレーカーでワード ブレークした場合
今日 / はとてもいい / 天 / 気 / です
中国語のワード ブレーカーは中国語を想定して作られていますので、当然日本語を意味のある単語で正しく区切ってくれるとは限りません。
このような状況で、検索インデックスに格納された「天」と「気」に分断された情報を、「天気」でワード ブレークされた単語で照会しても、検索結果は得られないことになります。その逆も同様です。
参考資料
タイトル:SharePoint Server 2010 のエンタープライズ検索
URL :https://technet.microsoft.com/ja-jp/sharepoint/ee441229.aspx
タイトル:エンタープライズ検索のアーキテクチャ
URL :https://technet.microsoft.com/ja-jp/subscriptions/ms570748(v=office.12).aspx
タイトル:Microsoft Office SharePoint Server 2007 日本語ワード ブレーカーの概要
URL :https://download.microsoft.com/download/8/e/a/8ea58fbb-2ecb-4991-bbdd-d9509ce883db/Japanese%20LSP%20WB%20Overview%20for%20customer.doc