Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
System Center Blog
- Home
- System Center
- System Center Blog
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed

2,222
2,917
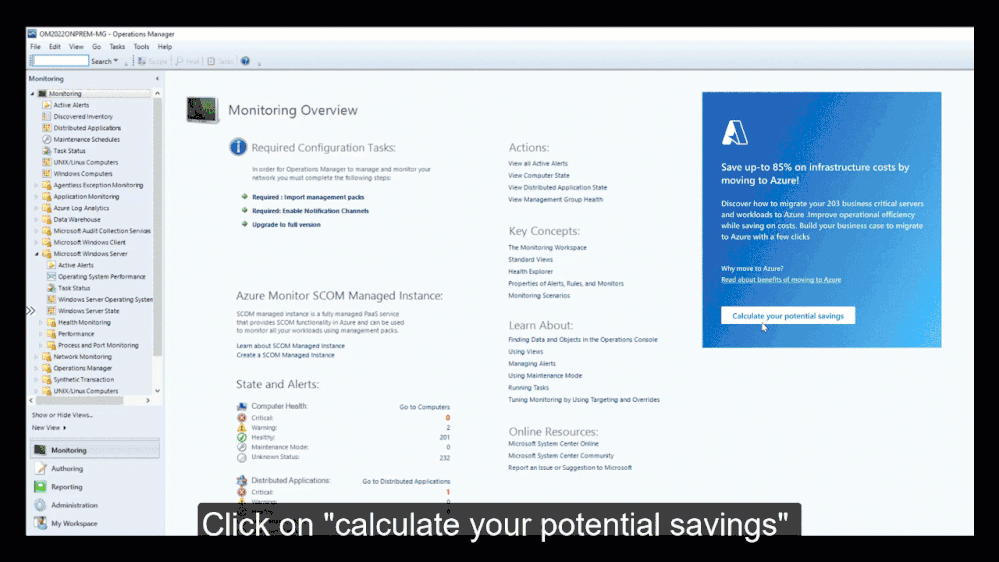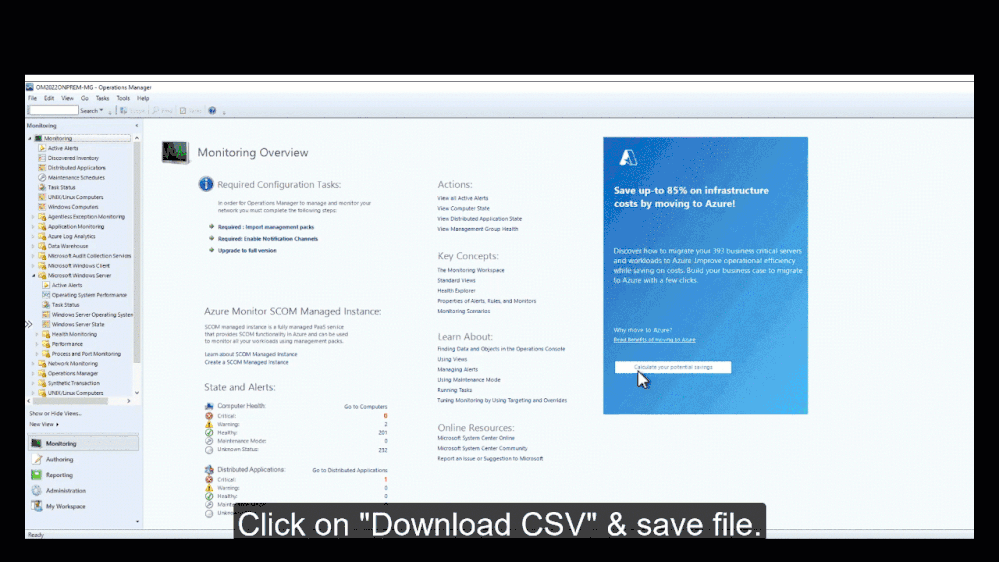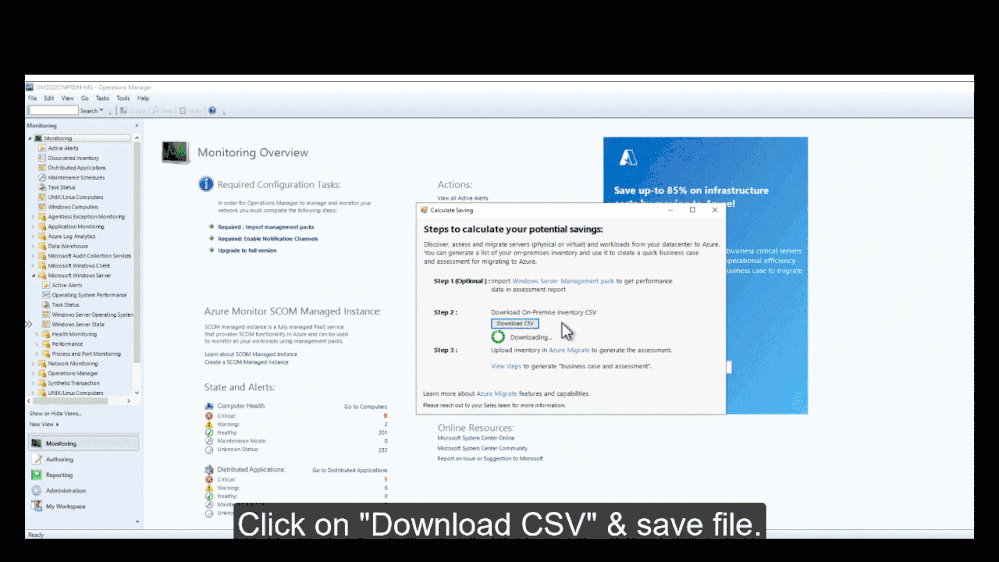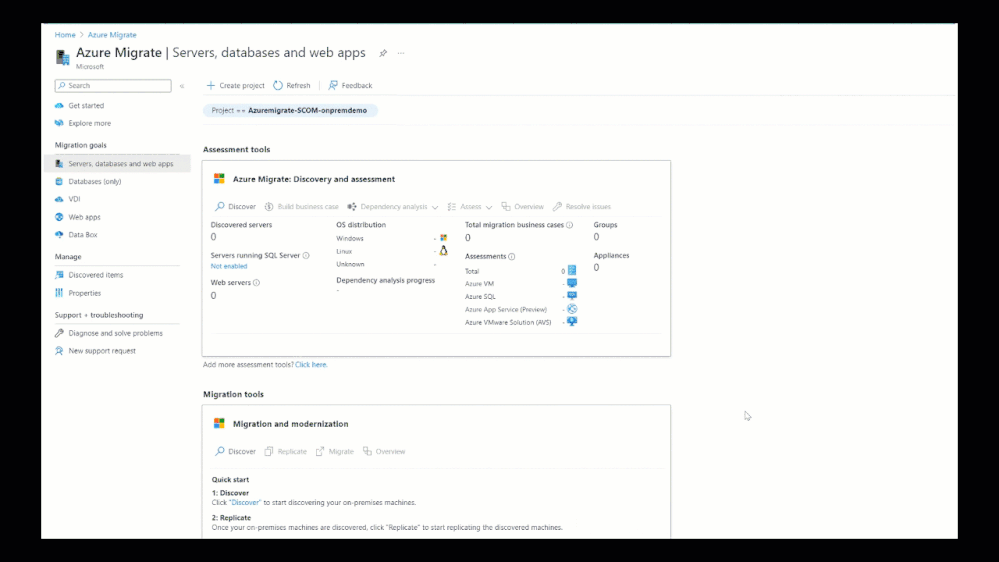

4,280
4,077
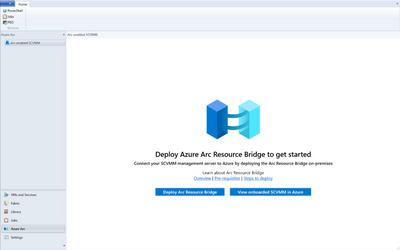
10.5K

6,770



8,830
12.9K
8,250
Latest Comments