Lync 2013 Persistent Chat HADR Deep Dive Pt. 1
As everyone knows by now, with the release of Lync Server 2013 we introduced much improved chat functionality, named Persistent Chat (pChat). Not only is it much improved, but it is also an actual role within the topology (no longer standalone application). One thing that I get questioned about a lot regarding pChat is High Availability and Disaster Recovery (HA-DR). Hopefully with this two part article I can help answer some of those questions.
Before we get into how to configure HA-DR, let’s first look at the basic architecture. Our design guidelines state that each pChat pool can have up to 8 servers (4 Active, 4 Standby) with each of the 4 Active servers supporting 20K concurrent users. Based on our default user model this totals 80K concurrent users per pChat deployment although we can have up to 150K users provisioned. Having multiple Persistent Chat Server pools does not give you more scale (you can still have only 80,000 concurrently connected users across all your Persistent Chat Server pools). The primary reason for supporting multiple Persistent Chat Server pools is to support regulatory concerns.
Some important points to keep in mind with pChat HADR:
- pChat stretched pools supported - Before I go on, I want to mention that Lync Server 2013 supports stretched pools for pChat but NOT for FE pools’
- pChat workload is entirely reliant on SQL backend services (unlike Lync 2013 FE servers)
- pChat leverages two SQL redundancy technologies for HA and DR – SQL mirroring\SQL Clustering and SQL log shipping
- pChat is deployed centrally for the entire organization – unlike some regional requirements for other Lync services
- Branch Survivability scenarios don’t apply to the pChat workload
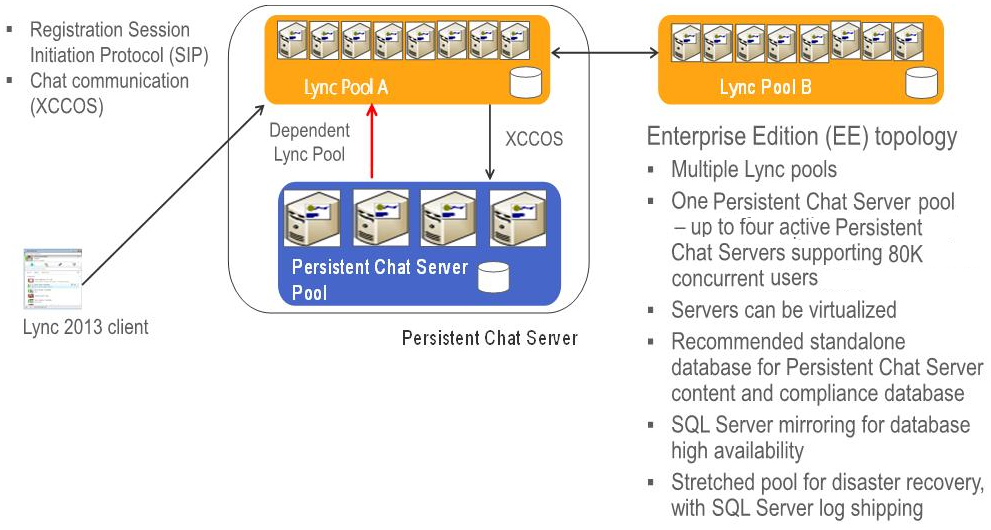
Figure 1: Lync Server 2013 pChat Architecture
pChat High Availability (Single Datacenter)
Let’s start by looking at pChat High Availability within a single datacenter or centralized datacenter (In Figure 2 below). I have broken out all the services to specific layers. The services contribute to our overall HA solution as follows:
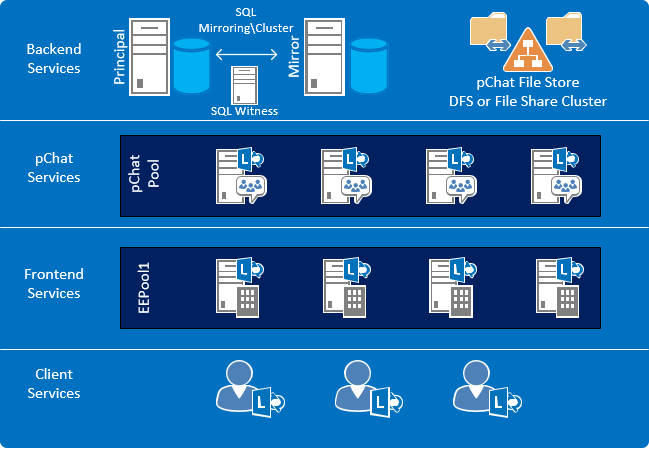
Figure 2: Lync Server 2013 pChat HA (Single Datacenter)
- Frontend Services - when the pChat clients log in they first connect to the FE servers, which authenticate the user and start to relay XCCOS messages between the pChat client and the pChat channel servers. We also utilize the FE servers for file posting into pChat room (only available for legacy clients at the moment). In order to achieve high availability within this layer, we deploy FE servers’ in an Enterprise Pool configuration so that if one FE server goes offline, the other FE server’s manage this traffic seamlessly and without interruption.
- pChat Services – in order to achieve HA inside this layer we deploy our pChat servers into a pChat Pool similar to the FE server’s. Configuring multiple pChat servers in a pool provides multiple channel service endpoints to accept connections. If a pChat server goes offline, clients will be reconnected to one of the other active pChat servers in that pool. Reconnection time is about 10 logons/second. This means with large deployments this could take quite a bit of time for failover to complete.
- Backend Services – the bulk of our pChat data (and compliance data) is stored within two backend databases. These databases are named MGC (pChat Data) and MGCOMP (pChat compliance data). We have two choices for HA with our SQL data: SQL Mirroring or SQL Clustering. Although both SQL HA methods are support our recommendation is Mirroring. In order to achieve seamless automatic failover in a mirrored configuration we must include a SQL witness server. Since clusters are setup for automatic failover nothing additional is needed here. Another backend server that needs to be highly available is the pChat File Store. This contains the data that is uploaded and gets downloaded to our pChat rooms. Again we have two HA options: DFS or File Share clusters. Either one will work, and the option you choose really depends on your environment. My recommendation and what I have been seeing customers lean towards is DFS (if available). The advantages of DFS over FS Cluster is automatic replication to multiple datacenters and topology namespace for the file share doesn’t need to be changed in failover scenario.
** Production pChat deployments should have a dedicated SQL Instance**
pChat Disaster Recovery (Multiple Datacenters)
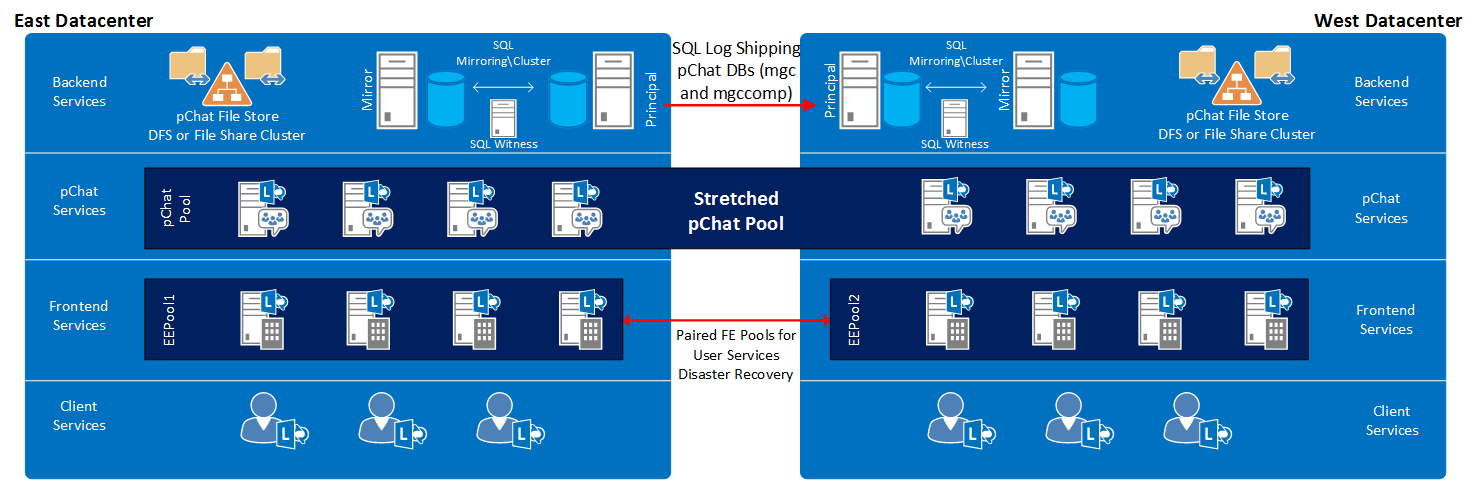
Figure 3: Lync Server 2013 pChat Disaster Recovery (Multiple Datacenters)
All of our discussions about pChat Disaster Recovery are going to reference the Topology Diagram in Figure 3. As we did previously, let’s break each service out individually, but this time as it pertains to Disaster Recovery.
- Frontend Services – with Lync 2013 we introduced a new concept for disaster recovery of user services on FE server called “Pool Pairing”. This allows us to replicate user data through a “Backup” service to a paired pool in another site. In the event of a failed datacenter or pool we would failover the FE services to the other pool and our users would connect there with current data.
- pChat Services– for disaster recovery of our pChat pool we can utilize a stretched pool. In a pChat stretched pool, the physical servers in a single pool span multiple datacenters (e.g. 4 pChat servers in East DC and 4 in West DC). Within the topology these will still appear as 1 pChat pool instance. There are two scenarios pertaining to bandwidth speed and availability between the datacenters that will affect which pChat servers should be active under normal operating conditions within the stretched pool.
- Stretched Pool configuration with Low Bandwidth\High Latency between datacenters - note that all active pChat servers MUST be in one datacenter and standby pChat servers in the other datacenter.
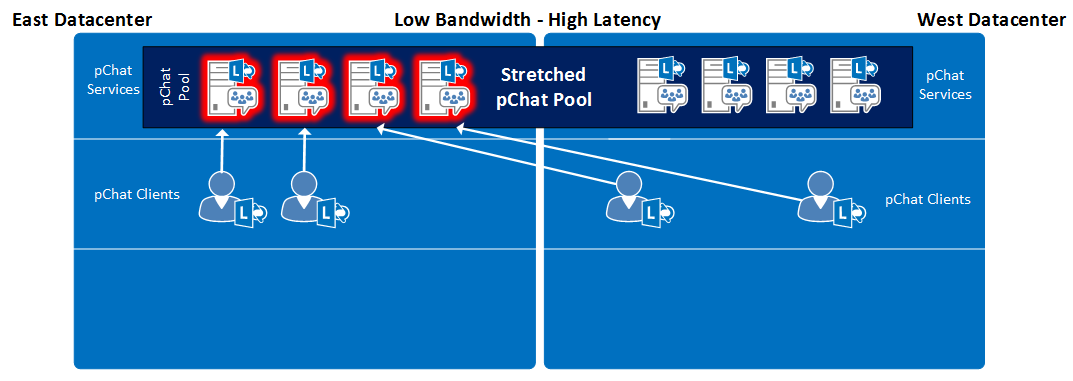
Figure 4: Stretched Pool configuration with Low Bandwidth\High Latency between datacenters
b. Stretched Pool configuration with High Bandwidth\Low Latency between datacenters – active pChat servers should be distributed evenly between datacenters. Note that there are 2 active pChat servers in each datacenter.
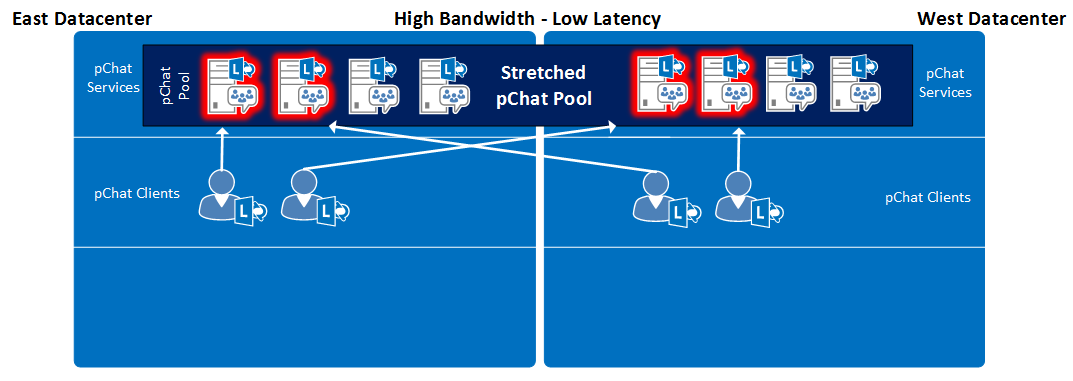
Figure 5:Stretched Pool configuration with High Bandwidth\Low Latency between datacenters
3. Backend Services – for pChat DR SQL log shipping is used to replicate backend data from one datacenter to the other. This provides an up-to-date replica of our MGC and MGCCOMP DBs across datacenters.
In part 2 of this article I am going to focus heavily on different DR failure scenarios including complete site outages (all services), pChat Server failover, FE Pool failure, setting active pChat servers, and Failback. This will include both individual steps for each scenario and detailed description of why we are performing each step. Stay tuned…
Understand HADR in Lync Server 2013 - link
Planning Front End Pool Pairing - link
pChat Capacity Planning (User model) - link
pChat Architecture - link