Remember to vote for your AlwaysOn Availability Groups
While visiting a customer and helping them set up AlwaysOn Availability Groups we came across a surprising "feature". On my laptop I had build a demo lab consisting of one domain controller, three Windows 2008R2 Core member servers with SQL 2012 SP1 installed and a full Windows 2008 R2 installation with SQL Server management studio installed. I had setup the cluster, enabled AlwaysOn and created an empty database to create an availability group. I tested the availability group by manually failing over using management studio and this worked fine.
But that's in the demo world. Usually we have all kind of conditions that cause our demo's not to work with our customers. In this case the customer had set up an availability group as well and the failover was working when initiated from management studio. But stopping the SQL Server service caused the Availability Group to stay in a resolving state and never failover. I tried this on my machine and it failed over perfectly. The only difference between my setup and the customer was that I was using a three node cluster and they were using a two node + file share cluster. To match the customers setup I removed the third replica from the availability group and evicted this node from the cluster. This left me with a two node cluster. What is important to remember is that this is not a recommended setup. In this setup you will never have majority and the cluster will go offline when one of the nodes goes offline. This basically defeats the purpose of a cluster. But to satisfy my curiosity I stopped the SQL Server service. To my surprise the availability group failed over to the other node.
A quick recap:
- Three node cluster with an availability group: Stopping the service fails over the availability group
- Two node cluster (not recommended) with an availability group: Stopping the service fails over the availability group
- Two node with file share witness: Stopping the service leaves the secondary in a resolving state and the listener remains offline
This is a known issue and if you read the signs along the road you would have noticed this. The reason I missed it at first is that in the earlier builds the link in the warning did not work. Below is a screenshot of the warning you will get when you perform a failover in the third scenario.
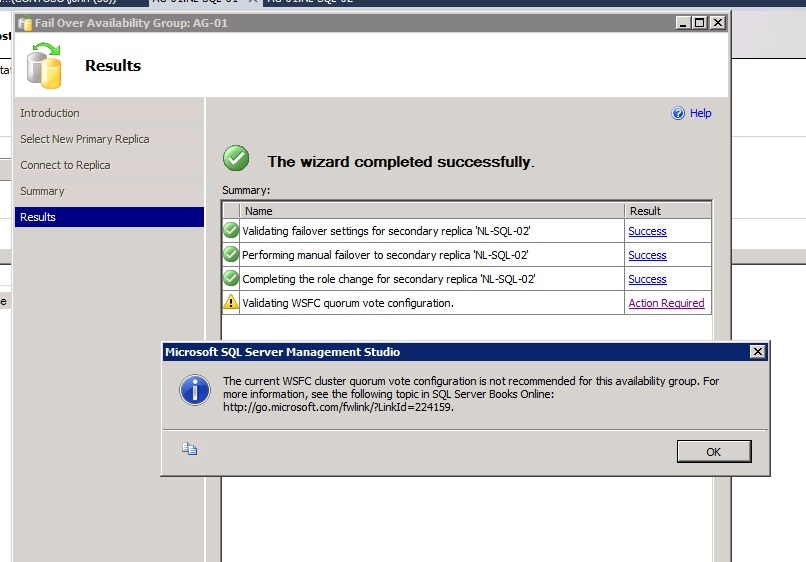
There is a KB article that describes this behavior (https://support.microsoft.com/kb/2761129) and this references the same KB article (https://support.microsoft.com/kb/2494036) that is mentioned in the link in the warning message. In short it turns out that the nodes do not have a vote. You can see this by querying sys.dm_hadr_cluster_members or clicking the View Cluster Quorum Information link in the AlwaysOn dashboard. This will show NULL or Not Available. This means the nodes do not have a vote and we need the vote to determine if there is quorum.
After applying the hotfix we get the desired behavior and the dmv and dashboard show 1 indicating each node has a vote. Stopping the service results in a failover leaving the new primary in a Not Synchronizing state. This is the expected state but leaves the availability group at risk. Another replica must come online as soon as possible to start synchronizing. In this state the transaction log will not be able to truncate and reuse the space within the log file.