Hyper-V Cloud Fast Track Architecture Brief
(NOTE: this is a cross-post from the Virtualization Team Blog. Download the whitepaper now!)
So you heard about the Hyper-V Cloud Fast Track program and wonder … what exactly is it? Is it marketecture or is there some meat to it? What do these “pre-architected, pre-validated” solutions consist of, and how were those decisions arrived at? What was the architecture and validation methodology? Well my friend, this post is for you.
 Myself and David Ziembicki authored the Hyper-V Cloud Fast Track Reference Architecture and Validation Guide used to align Microsoft and OEM partners on a common architecture and for OEMs to re-use and expand upon for their own Reference Architectures. Dave and I are Solution Architects within Microsoft Services in the US Public Sector organization.
Myself and David Ziembicki authored the Hyper-V Cloud Fast Track Reference Architecture and Validation Guide used to align Microsoft and OEM partners on a common architecture and for OEMs to re-use and expand upon for their own Reference Architectures. Dave and I are Solution Architects within Microsoft Services in the US Public Sector organization.
A few details to get out of the way: First, each OEM (HP, Dell, IBM, Hitachi, Fujitsu, NEC) brings something unique to the table. Each OEM partner will be jointly publishing with Microsoft their Hyper-V Cloud Fast Track Reference Architecture, which will detail the hardware specifications, configurations, detailed design elements, and management additions. Available to you right now are some great resources such as solution briefs, a new white paper, and Fast Track partner web sites. In this post I will share with you the common architecture elements that apply to all program partners and how those decisions were made.
Next, I’d like to direct you to the Private Cloud TechNet Blog where I have detailed the Principles and Concepts which underlay the architecture of this program. Now, those principles are actually pretty lofty goals and the program will address more and more of them over time. A brief preview of the concepts is listed below. I feel it’s important to provide a glimpse of them now because they are what Hyper-V Cloud Fast Track aims to achieve. Please reference the post for deeper insight on these.
Private Cloud Concepts
- Resiliency over Redundancy Mindset – This concept moves the high-availability responsibility up the stack from hardware to software. This allows costly physical redundancy within the facilities and hardware to be removed and increases availability by reducing the impact of component and system failures.
- Homogenization and Standardization – by homogenizing and standardizing wherever possible within the environment, greater economies of scale can be achieved. This approach also enables the “drive predictability” principle and reduces cost and complexity across the board.
- Resource Pooling – the pooling of compute, network, and storage that creates the fabric that hosts virtualized workloads.
- Virtualization – the abstraction of hardware components into logical entities. I know readers are of course familiar with server virtualization, but this concept speaks more broadly to benefits of virtualization across the entire resource pool. This may occur differently with each hardware component (server, network, storage) but the benefits are generally the same, including lesser or no downtime during resource management tasks, enhanced portability, simplified management of resources, and the ability to share resources.
- Fabric Management – a level of abstraction above virtualization that provides orchestrated and intelligent management of the fabric (i.e., datacenters and resource pools). Fabric Management differs from traditional management in that it understands the relationships and interdependencies between the resources.
- Elasticity – enables the perception of infinite capacity by allowing IT services to rapidly scale up and back down based on utilization and consume demand
- Partitioning of Shared Resources – While a fully shared infrastructure may provide the greatest optimization of cost and agility, there may be regulatory requirements, business drivers, or issues of multi-tenancy that require various levels of resource partitioning
- Cost Transparency – provides insight into the real costs of IT services enabling the business to make informed and fair decisions when investing in new IT applications or driving cost-reduction efforts.
Hyper-V Cloud Fast Track Architecture Overview
With the principles and concepts defined we took a holistic approach to the program thinking first about everything that would be ideal to achieve an integrated private cloud and pairing down from there to what now forms the first iteration of the offering. As stated, future versions will address more and more of the desired end-state.
Scale Unit
Scale Units represents a standardized unit of capacity that is added to a Resource Pool. There are two types of Scale Unit; a Compute Scale Unit which includes servers and network, and a Storage Scale Unit which includes storage components. Scale Units increase capacity in a predictable, consistent way, allow standardized designs, and enable capacity modeling.
Server Hardware
The server hardware itself is more complex that it might seem. First, what’s the ideal form-factor? Rack-mount or Blade? While we certainly have data that shows blades have many advantages for virtualized environments, they also can add cost and complexity for smaller deployments (4-12 servers). This is one decision where we provided guidance and experience on, but ultimately left the decision to the OEM as to when blades made sense for their markets. Most OEMs who have both blade and rack-mount options and will be offering both through this program.
For CPU, all servers will have a minimum of 2-socket, quad-core processors yielding 8 logical processors. Of course, many of the servers in the program will have far more than 8 LPs, likely 12-24 will be most common as that’s the current price/performance sweet-spot. BTW - Hyper-V supports up to 64 LPs. The reason for this is that although the supported ratio of Virtual Processors to Logical Processors is 8:1, real-world experiences with production server workloads have shown more conservative average ratios. Based on that we concluded 8 LPs should be the minimum capacity starting point.
Storage
Storage is where, for me anyway, things begin to get really interesting. There are just so many exciting storage options for virtualized environments these days. Of course, it’s also a design challenge: which features are the highest priority and worth the investment? We again took a holistic approach and then allowed the partner to inject their special sauce and deep domain-expertise. Here’s the list of SAN storage features we targeted for common architecture criteria:
- High Availability
- Performance Predictability
- Storage Networking
- Storage Protocols
- Data De-duplication
- Thin Provisioning
- Volume Cloning
- Volume Snapshots
- Storage Tiering
- Automation
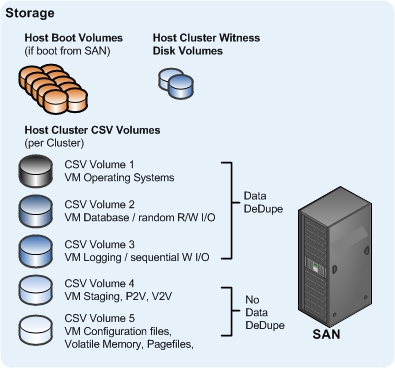
Cluster Shared Volume design example
One of the really cool advantages of this program is that it allows for multiple best-of-breed private cloud solutions to emerge taking advantage of each vendor’s strength. You can only find this in a multi-vendor, multi-participant program.
On the Hyper-V side we provided common best-practices for Cluster Shared Volume configuration, sizing, and management as well as considered such things as MPIO, Security, I/O segregation, and more.
Network
Networking presents several challenges for Private Cloud architectures. Again here we find a myriad of choices from the OEMs and are able to leverage the best qualities of each where it makes sense. However, this is an area where we sometimes find IT happening for IT’s sake (i.e. complex, advanced networking implementations because they are possible and not necessarily because they are necessary to support the architecture). We need to look at the available products and features and only introduce complexity when it’s justified as we all know increased complexity often brings with it increased risk. Some of those items include:
- Networking Infrastructure (Core, Distribution, and Access Switching)
- Performance Predictability and Hyper-V R2 Enhancements (VMQ, TCP Checksum Offload, etc.)
- Hyper-V Host Network Configuration
- High Availability
- 802.1q VLAN Trunks
- NIC Teaming
NIC Teaming in particular is one of those items that can be tricky to get right being there are different vendor solutions each with potentially different features and configuration options. Therefore it’s an example of a design element that benefits greatly from the Hyper-V Cloud Fast Track program taking all the guesswork out of NIC Teaming providing the best-practice configuration tested and validated by both Microsoft and the OEM.
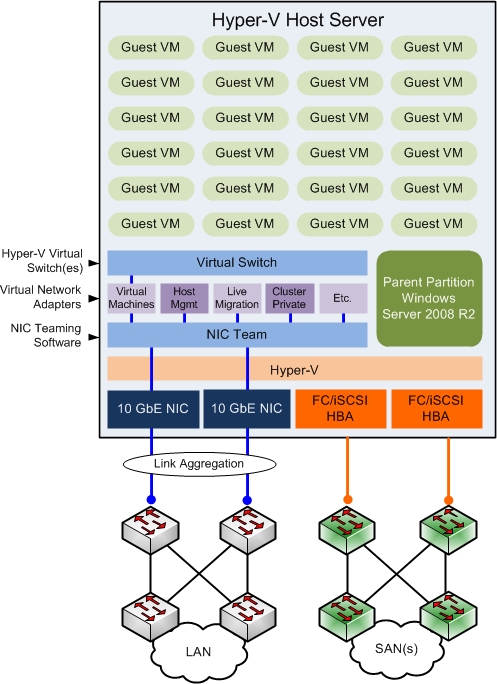
NIC Teaming design example
Private Cloud Management
Let’s face it, cloud computing places a huge dependency on management and operations. Even the most well designed infrastructure will not achieve the benefits promised by cloud computing without some radical systems management evolution.
Again leveraging the best-of-breed advantage, a key element of this architecture lies in that the management solution may be a mix of vendor software. Notice I said may. That’s because a vendor who is a big player in the systems management market may have chosen to use their software for some layers of the management stack while others may have chosen to use an exclusively Microsoft solution consisting of System Center, Forefront, Data Protection Manager, etc. I will not attempt to cover each possible OEM-specific solution. Rather, I just want to point out that we recognize the need and benefit of OEMs being able to provide their own elements of the management stack, such as Backup and Self-Service Portal. Some are, of course, essential to the Microsoft virtualization layer itself and are non-replaceable such as System Center Virtual Machine Manager and Operations Manager. Here is a summary of the management stack included:
- Microsoft SQL Server
- Microsoft System Center Virtual Machine Manager and Operations Manager
- Maintenance and Patch Management
- Backup and Disaster Recovery
- Automation
- Tenant / User Self-Service Portal
- Storage, Network and Server Management
- Server Out of Band Management Configuration
The Management layer is so critical and really is what transforms the datacenter into a dynamic, scalable, and agile resource enabling massive capex and opex cost reduction, improved operational efficiencies, and increased business agility. Any one of these components by themselves is great, but it’s the combination of them all that qualify it as a private cloud solution.
Summary
There are several other elements I would love to delve into such as Security and Service Management, but this post could go for quite a while. I’ll leave the remainder for the Reference Architecture Whitepaper which we just published, as well as the OEM-specific Reference Architectures published by them.
I hope you found this article useful and that it sheds some light on the deep and broad collaborative effort we have embarked upon with our partners. Personally, I am very happy that this program was created and am confident it will fill a great need emerging in datacenters everywhere.
Adam Fazio, Solution Architect, Microsoft