Linked Server behavior when used on JOIN clauses
Recently, a client had some performance problems with a query that executed a join with a remote table using a linked server. The client asked why similar queries, that use filters over the local tables and returned a few rows, sometimes compile IO expensive queries on the remote server.
It’s important to know how SQL Server compile queries with remote tables, this will help us to tune our queries and have good response times, because by using less IO and transferring less data over the network we will have a better performance.
When working with linked servers is very important to know that SQL Server must send the data from the remote server to the servers that is calling the remote object to evaluate and apply the filters defined in the JOIN clause.
When you use Linked Servers on a JOIN clause, SQL Server will compile the best plan to execute the query, avoiding unnecessary data transmission over the network, so the query will take less time to execute. Let’s review some examples step by step of how SQL Server manages queries involving remote tables:
CASE 1: On the following example the JOIN uses a remote table and no filters are in-place. You can see that all records are returned from the remote server because when you don’t have filters all the records are necessary on the local server to evaluate and execute the JOIN condition.
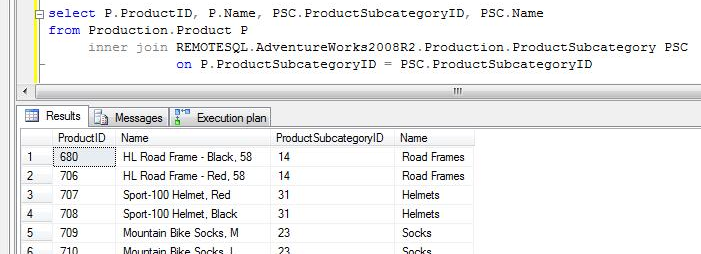
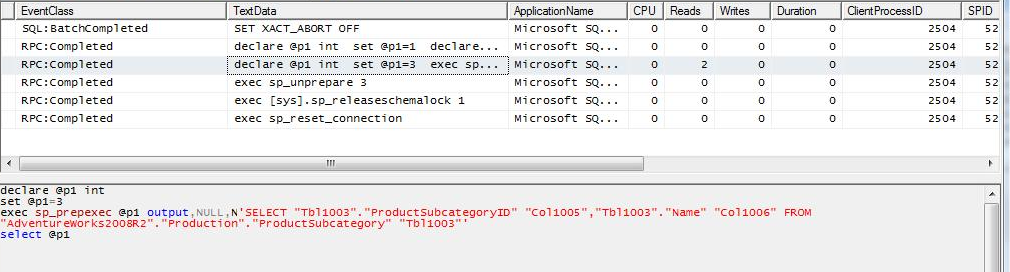
CASE 2: to the case 1 query we applied a filter on a column of the remote table. You can see that SQL Serve check the statistics of the remote table to build the best query, and you can see the filter statement for the remote table on the identified column
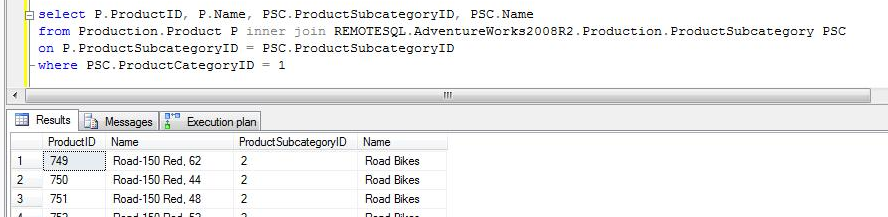
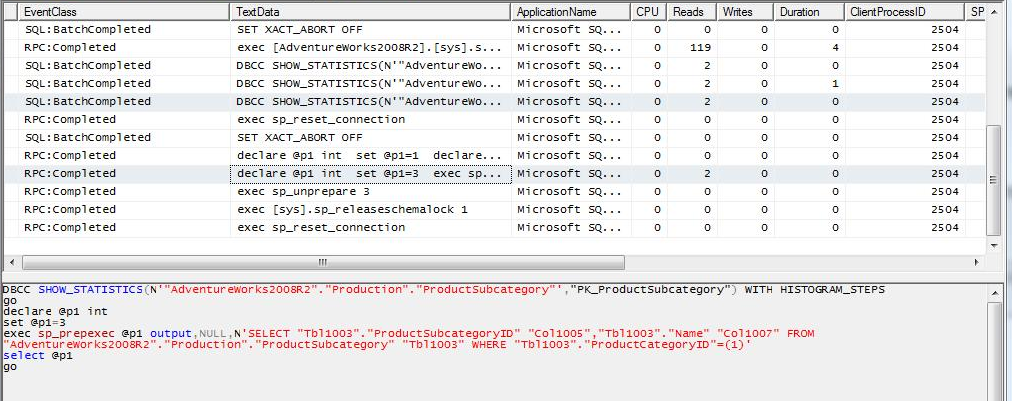
CASE 3a: to the case 1 query we applied a filter on a column of the local table. You can see that SQL Server first apply the filter and if it obtains a low number of different values (relative per query) after applying the filter, it builds a query to get only the necessary data from the remote table using the JOIN condition on the corresponding field, and this will be execute as many times as different values return the filter on the local table.
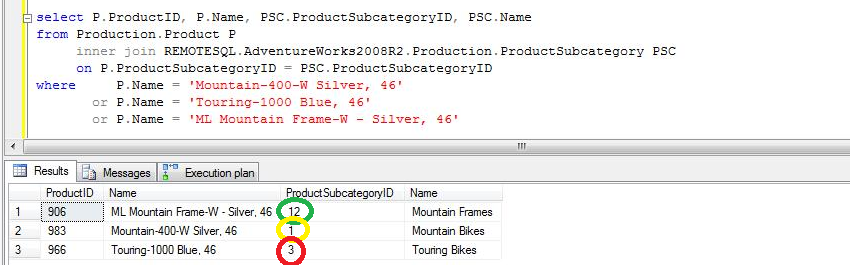
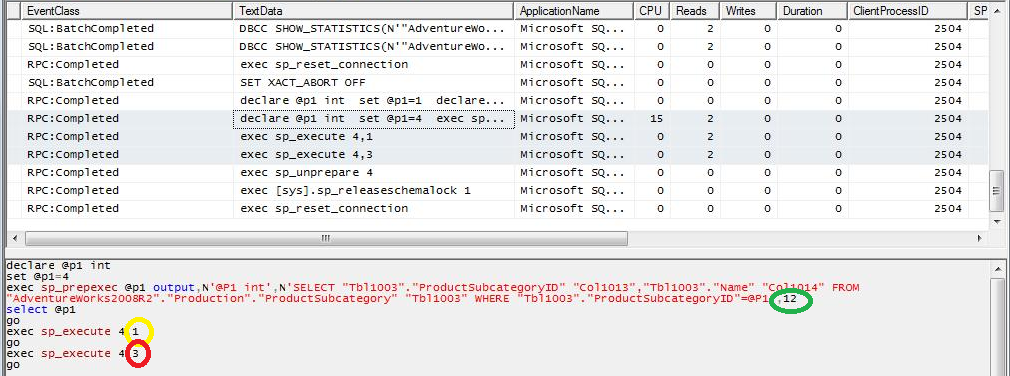
CASE 3b: to the case 1 query we applied a filter on a column of the local table. You can see that SQL Server first apply the filter and if it obtains a high number of different values (relative per query) after applying the filter, SQL Server will send one query with no filters, it only specifies the required columns and sorts the result on the JOIN condition field to help the execution, because it will need to execute a Merge Join instead of a Nested Loop Join.
NOTE: you will see this behavior with either the existence of an index on JOIN field or not

CASE 4a: to the case 1 query we applied a filter on a column of the local table that causes that no record is returned for the table and so no record is returned for the query. As you can see SQL Server will not execute a query to return data (because it’s not necessary), however it will establish a session to the remote server and execute some queries to return statistics and to get a schema lock on the remote table.

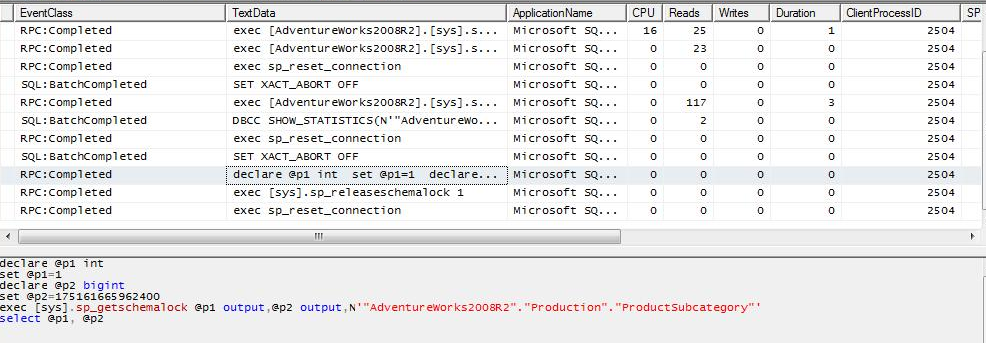
The same will happen when you execute the same query form the case 1, but with a condition that makes that no record is returned when the filter its applied on the remote table: no query to return data is executed after checking the remote table statistics.

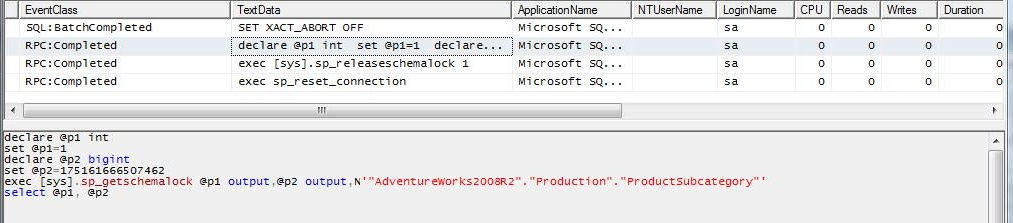
CASE 4b: to the case 1 query we applied a filter on a column of the local table that causes that no record is returned for the table and so no record it’s returned for the query, also we included a filter on the remote table on a column that have a UNIQUE index defined, you can see that unlike the case 4a, SQL Server will execute a query on the remote server using a filter on the indicated remote column.
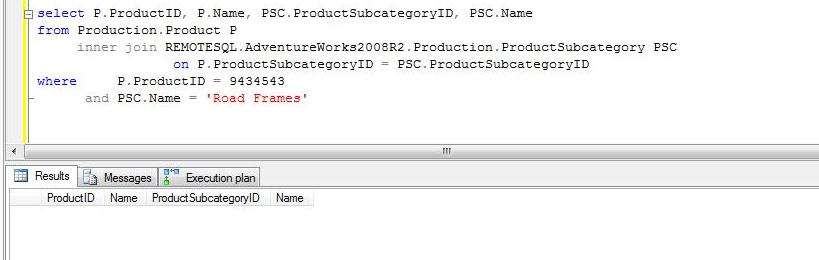
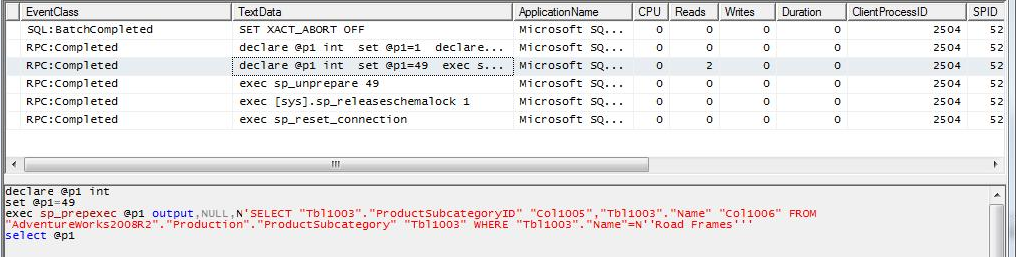
NOTE: LEFT JOINS and RIGHT JOINS will behave exactly the same way as an EQUAL JOIN. The queries send to the remote server will be built depending on the data to be returned, indexes and statistics.
In the case reported by my client, the difference between executions of similar queries was caused because SQL Server wasn’t able to create the best query to be executed on the remote server after adding one or two conditions to the query, and the situation was even worse because of outdated statistics on the local and remote databases.
After reviewing the SQL Server behavior when using Linked Servers on JOIN clauses, we can conclude:
- Maintaining statistics updated is not only important for SQL Server to compile the best execution plans for local operations, they are also important when using linked servers in order to define if it’s necessary to execute a query against the remote server, and if necessary it will use them to build the best query to return the least amount of data possible.
- Even if SQL Server determine that it’s not necessary to execute a query against the remote server to satisfy the query, SQL Server will establish a connection, query statistics and apply schema locks on the remote object, and this could lead to some delays and blocking, for example, a previous schema lock on the object will lead to a block.
- On the developing and troubleshooting faces, analyzing the query that SQL Server executes on the remote server it’s really useful to identify the root cause of what it seems to be a bad behavior. The cases 3a and 3b are examples of cases on which distribution, data volume and statistics could lead to a big difference on performance. Cases 4a and 4b are example of SQL Server could design the remote queries differently just due to the use of different conditions.
“The opinions and views expressed in this blog are those of the author and do not necessarily state or reflect those of Microsoft”