Exchange 2013 - Outlook i Load Balancing cz. 2
Automatyczne przelaczenie na osrodek zapasowy w Exchange 2013
W moim poprzednim wpisie przedstawilem zmiany w dystrybucji polaczen do serwerów Exchange 2013. W drugiej czesci artykulu chcialbym zaprezentowac, jak modyfikacje w dzialaniu roli Client Access wplywaja na przelaczanie sie na zapasowy osrodek przetwarzania
danych. Postaram sie odpowiedziec na pytanie: czy mozemy osiagnac w pelni automatyczne przelaczenie na osrodek zapasowy, w przypadku awarii jednej z lokalizacji.
Wspólna nazwa staje sie faktem!
W poprzedniej czesci artykulu stwierdzilem, ze przy polaczeniach do serwerów CAS nie jest wymagane Affinity. Kazdy serwer Client Access (nawet ten, znajdujacy sie w innym Site’cie AD niz serwer Mailbox) moze proxowac polaczenie HTTPS do serwera Mailbox, na którym znajduje sie nasza skrzynka pocztowa. Polaczenia pomiedzy lokalizacjami (cross-site) odbywaja z wykorzystaniem protokolu HTTPS. To, do której lokalizacji trafi nasze polaczenia nie ma zasadniczego znaczenia, na jakosc polaczenia do skrzynki. Oznacza to, ze mozemy skorzystac z wspólnej nazwy dla wielu lokalizacji z serwerami Exchange 2013, poniewaz nie jest istotne, do którego serwera CAS trafi nasze polaczenie HTTPS.
DNS Round Robin
W mechanizmie DNS Round Robin wiele adresów IP jest powiazanych z jedna nazwa. Brak Affinity oraz mozliwosc uzycia wspólnej nazwy dla kilku lokalizacji powoduja, ze w konfiguracji Site Resilient musimy skorzystac z mechanizmu DNS Round Robin. Trzeba pamietac, ze DNS Round Robin nie dystrybuuje polaczen w sposób równomierny, ani nie potrafi w sposób skuteczny reagowac na wszystkie mozliwe scenariusze awarii. Rozwiazaniem drugiego problemu jest mechanizm IP Failover wbudowany w system operacyjny. Zarówno Outlook jak i przegladarki
internetowe, potrafia skorzystac z tego mechanizmu. Proces IP failover powoduje, ze jesli dla danej nazwy, serwer DNS zwraca wiecej niz 1 adres IP, to klient bedzie próbowal polaczyc sie po kolei z kazdym z nich dotad az polaczenie sie powiedzie.
Jak wyglada konfiguracja srodowiska ze wspólna nazwa?
W schemacie ponizej pokazano srodowisko z dwoma lokalizacjami, zapewniajace automatyczne przelaczenie w przypadku awarii jednej z lokalizacji. Sklada sie ono z dwóch load balancerów, czterech serwerów Exchange bedacych czlonkami DAG (po dwa w kazdym datacenter) oraz File Share Witness umieszczonego w trzecim datacenter. Niezbedne jest rozmieszczenie serwerów Exchange symetrycznie w dwóch osrodkach przetwarzania danych. W przeciwnym wypadku awaria datacenter, w którym znajduje sie wiecej niz polowa serwerów bedacych czlonkiem DAG, oznaczac bedzie utrate wiekszosci w klastrze.
W DNSie utworzono rekordy dla wspólnej nazwy, które rozwiazuja sie na adresy IP obydwu load balancerów. Urzadzenia dystrybuujace polaczenia sa niezbedne, do równomiernego kierowania polaczen do dzialajacych serwerów CAS.
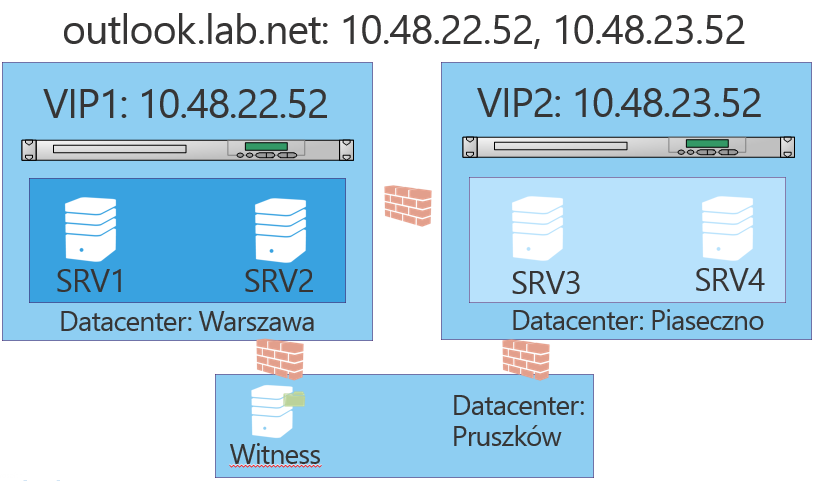
Waznym elementem projektu jest dobre zaplanowanie polaczen sieciowych miedzy lokalizacjami. Kazdy osrodek powinien miec bezposrednie i niezalezne polaczenia z pozostalymi osrodkami.
Przelaczenie na osrodek zapasowy
Przeanalizujmy, co sie stanie w przypadku awarii lacza internetowego w datacenter Warszawa. Otóz, uzytkownicy, którzy byli podlaczeni do Load Balancera w Warszawie, utraca polaczenie. Jednakze klienci spróbuja polaczyc sie z drugim adresem IP (10.48.23.52) dla nazwy outlook lab.net, dzieki mechanizmowi IP Failover. Po zestawieniu polaczenia z tym adresem polaczenia, beda proxowane przez serwery CAS w datacenter Piaseczno do serwerów z rola mailbox w Piasecznie i Warszawie. Komunikacja bedzie wygladala jak na schemacie ponizej:
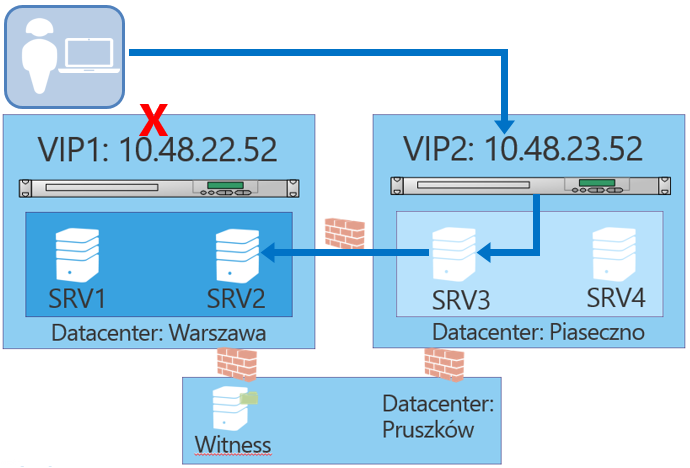
Wykonanie zmian w DNSie nie jest konieczne, jak to mialo miejsce w przypadku Exchange 2010. Jednakze, jesli naprawa lub wymiana load balancera zajmie dluzszy czas, zalecane jest usuniecie adresu IP load balancera z DNS. Dzieki temu nowe polaczenia beda nawiazywane szybciej, poniewaz klient nie bedzie próbowal dokonac polaczenia z load balancerem, który ulegl awarii.
W przypadku calkowitej awarii jednego z osrodków przetwarzania danych, mechanizm IP Failover sprawi, ze polaczenia HTTPS klientów zostana przekierowane do load balancera w drugim osrodku. Po awarii osrodka, DAG wciaz bedzie mial quorum, poniewaz serwery w dzialajacym datacenter, beda mogly skomunikowac sie z File Share Witness. Serwer Exchange z dzialajacego osrodka, który jako pierwszy skomunikuje sie z serwerem FSW otrzyma dodatkowy glos do formowania quorum. Zapewni to dalsze funkcjonowania klastra. Bazy skrzynkowe przelacza sie automatycznie do dzialajacego datacenter.
Jak to dziala w praktyce?
Zobaczmy jak w praktyce bedzie wygladalo przelaczenie. Ponizej znajduje sie schemat mojego srodowiska laboratoryjnego z dwoma load balancerami, w dwóch róznych lokalizacjach.
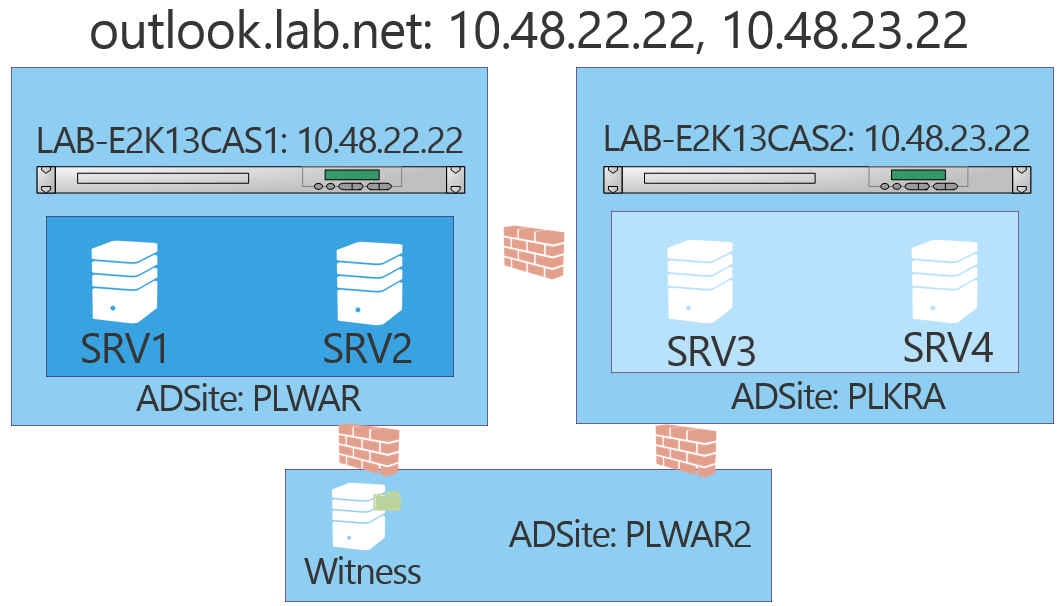
Dla polaczen RPC over HTTP uzywana jest wspólna nazwa outlook.lab.net, która w DNSie rozwiazuje sie na adresy IP Load Balancerów z obu lokalizacji.
Po nawiazaniu polaczenia z serwerem Exchange sprawdzmy, jakie informacje dotyczace nazwy outlook.lab.net znajduja sie w lokalnym cache’u DNS. W tym celu wykonuje polecenie ipconfig /displayDNS w wierszu polecen.
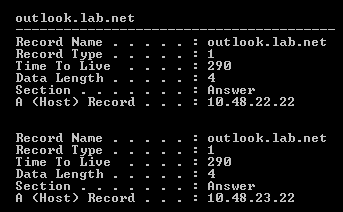
Serwer DNS zwrócil dwa adresy IP dla nazwy outlook.lab.net:10.48.22.22 i 10.48.23.22. Sprawdzmy, z którym Load Balancerem Outlook nawiazal polaczenie. W tym celu wykonuje polecenie netstat –ab w wierszu polecen.

Widzimy, ze polaczenie zostalo nawiazane z Load Balancerem LAB-E2K13CAS1.
Zasymulujmy awarie serwerów CAS, poprzez zatrzymanie Default Web Site na obu serwerach CAS w Site’cie PLWAR. Sprawdzmy, co stanie sie z polaczeniem Outlooka.
Po zatrzymaniu Default Web Site, Outlook traci polaczenie:

Po chwili jednak Outlook ponownie nawiazuje polaczenie.

Sprawdzmy, jak wygladaja polaczenia TCP na naszym komputerze. Wykonuje polecenie netstat –ab z wiersza polecen:

Widzimy, ze tym razem polaczenie jest nawiazane z load balancerem LAB-E2K13CAS2
Test zostal wykonany z wykorzystaniem Outlook 2013. To samo zjawisko zaobserwujemy, gdy bedziemy korzystac z Outlook 2007 lub 2010.
Podsumowanie
Exchange 2013 znaczaco upraszcza mechanizm przelaczenia pomiedzy dwoma osrodkami.
Pamietajmy, ze DNS Round Robin nie jest rozwiazaniem zapewniajacym wysoka dostepnosc. Pozwala on klientom reagowac na okreslone problemy z polaczeniem, ale nie zapewnia poziomów dostepnosci, jakie wymagane sa w ramach pojedynczego osrodka. Dlatego wysoka dostepnosc w ramach pojedynczej lokalizacji zapewniamy za pomoca load balancera, który jest w stanie reagowac na duzo bardziej zlozone problemy po stronie infrastruktury Exchange.
Ponadto, aby zapewnic automatyczne przelaczanie baz skrzynkowych, musimy
- Umiescic serwer File Share Witness w trzeciej lokalizacji.
- Zapewnic niezalezne polaczen miedzy osrodkami, aby awaria jednego z datacenter nie powodowala utraty polaczenia z File Share Witness.
- Symetrycznie rozlozyc serwery Exchange pomiedzy osrodkami. W obydwu osrodkach umiescic taka sama ilosc serwerów Exchange bedacych czlonkiem DAG