SharePoint 2013 Crawl Tuning Part 2: Content Processing Component
In part 1, we took a crawl performance baseline and came to the conclusion that our feeding bottleneck was the content processing component. So, we have expanded our SharePoint farm to two servers and we have added an additional Contend Processing Component on our new server. Our search topology now looks like this:
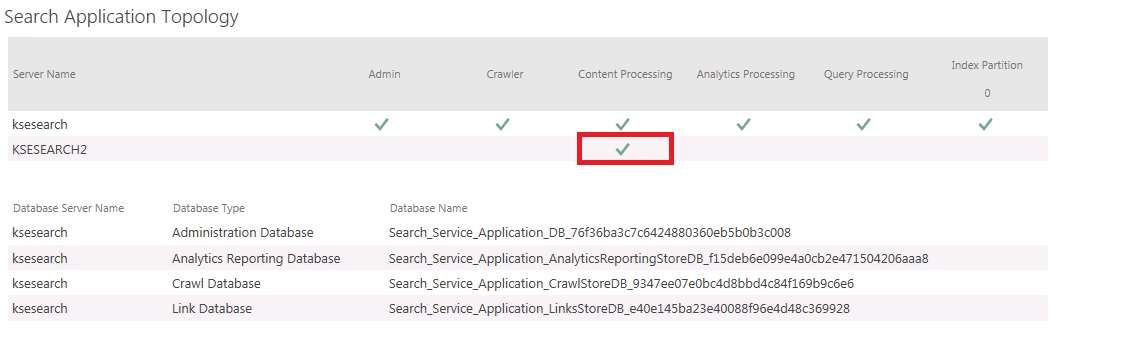
We'll now rerun the same full crawl test we performed in part 1 and collect counters from both servers.
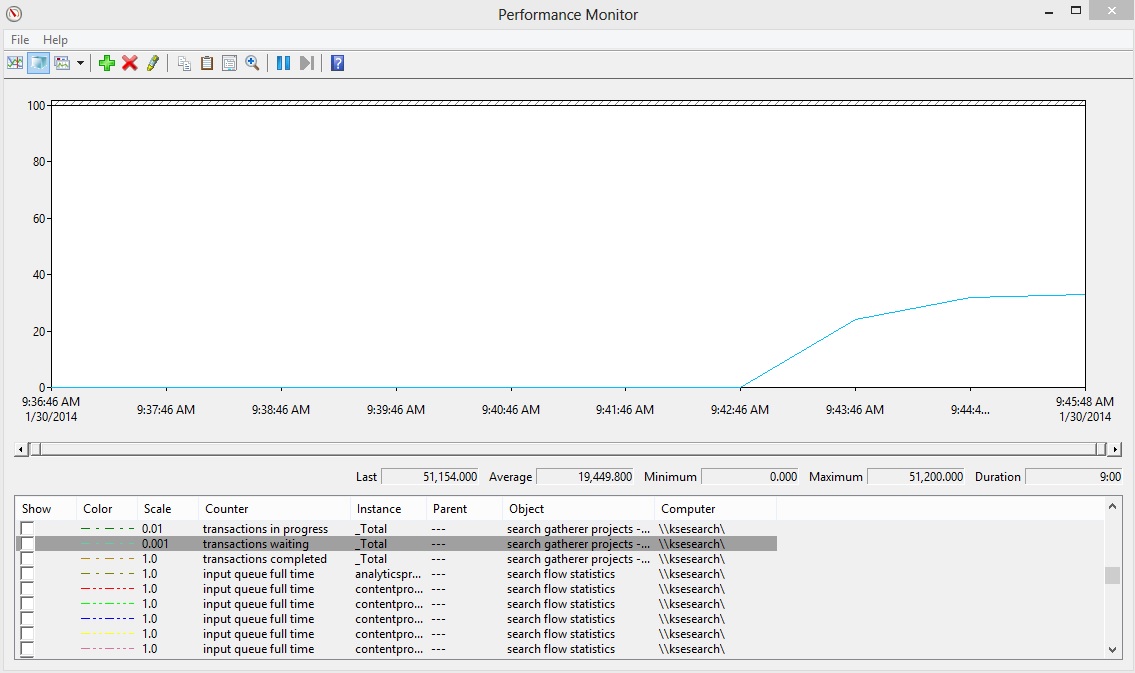
Our transactions waiting is still increasing, so we still see that the bottleneck is downstream of the crawler.
{kind=link}
The Content Processing Component still looks like our bottleneck, but there is slightly less load now that is spread over two CPCs. Here is the Search Flow Statistics\Input Queue Full Time to compare against part 1.
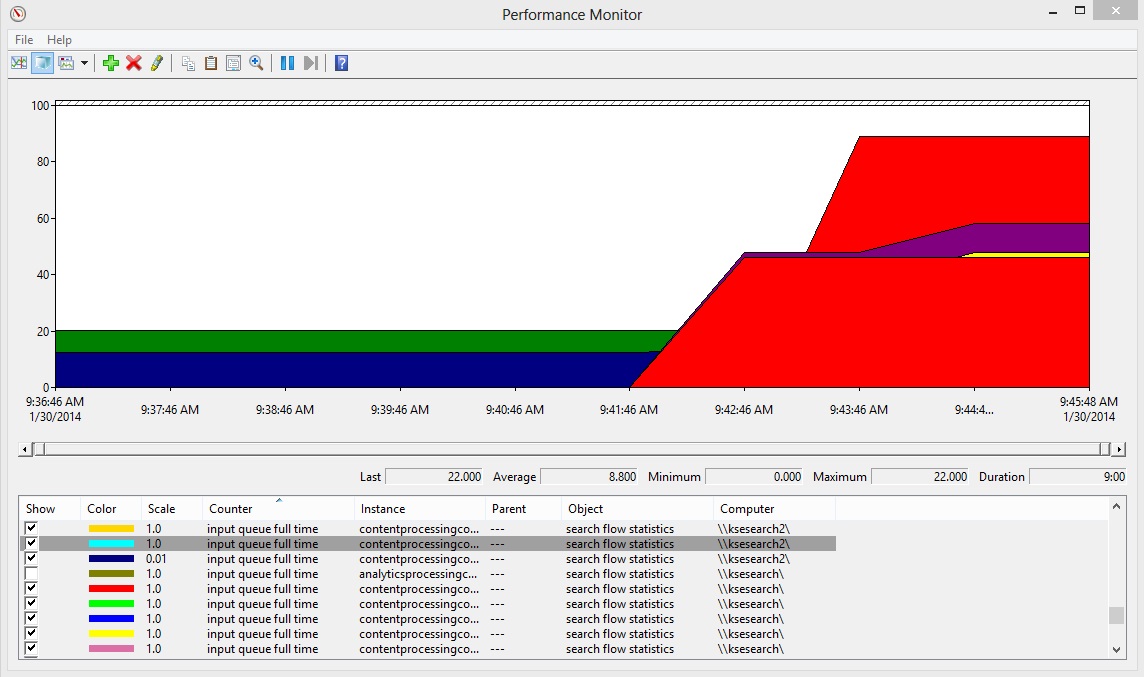
Now, the most important metric: did we improve our crawl time? By adding this single component to our search topology, we were able to cut our time for a full crawl nearly in half. Going from 85 minutes to 45 minutes. This dramatic improvement in performance shows how valuable tuning your search infrastructure can be.

In future installments we'll take a look at what to do when other components are the bottleneck. See part 3