Topology changes in System Center 2012 Operations Manager (Overview)
OM Community,
In this blog post, I will explain the changes made to the Operations Manager 2012 infrastructure topology. The purpose of this post is not to do a deep technical explanation on how some of these new features work but more of an overview around the new changes and how they may affect you. Over the next few months, we (Operations Manager Team) plan to blog additional technical details.
First things first(let’s review):
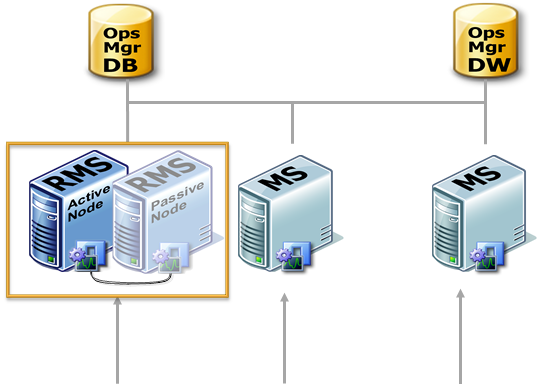
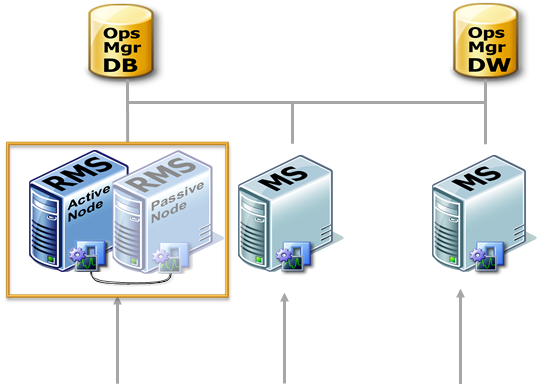
In previous versions, Operations Manager (2007, 2007 SP1, R2) had a parent-child topology, meaning that in a Management Group a Management Server called the Root Management Server (commonly known as the RMS) acted as a parent to one or more secondary Management Servers or Gateways. The RMS has many unique responsibilities in the Management Group (see below)
{kind=link}
{kind=link}

The RMS provides the following services:
- Console access
- Role based access control
- Distribution of configurations to agents
- Connectors to other mgmt systems
- Alert notifications
- Health aggregation
- Group Calculations
- Availability
- Dependency Monitor
- DB Grooming
- Enables model based mgmt
The RMS also introduces the following customer challenges:
- Performance and scalability bottleneck
- Single point of failure (for RMS workloads)
- High availability requires clustering
With these kind of challenges it was very important for most IT & Operations teams to ensure their RMS was highly available and easily recoverable in cases of a disaster.
This left them with two options:
- Cluster the Root Management Server (see picture)
- Promote a secondary Management Server to the RMS

Unfortunately, both of these options created additional complexity and burdens to the IT & Operations teams, Windows clustering is complex to setup and requires additional shared storage. Patching a clustered RMS was cumbersome and prone to creating instability in the Management Group. Promoting a secondary Management Server was a manual process that required the person to run a specialized command line tool then change multiple configuration files and registry keys on the other components like Reporting Server, Web Console, or other Management Servers. Depending on the customers SLA to the business they would implement one or both of these solutions to ensure some level of availability in the Management Group.
Also, by having this single point of failure in the Management Group it has created a bottleneck that limits the scale out numbers around how many Windows Agents, Unix Agents and console a single Management Group can support.
During product planning for OM12, we quickly identified this as one of our highest priorities. By removing the single point of failure we can provide our customers a much better story around High Availability and lower their costs to maintaining a Operations Manager infrastructure. Also, we can scale the Management Group out to support new OM12 features like Network Monitoring and Application Monitoring (APM).
The Major Change (RMS Removal)
After an in-depth investigation we decided to remove the Root Management server role from a Operations Manager topology. As a result, we needed to figure out how to distribute the workloads the RMS performed. This boils down to three things.
- SDK Service - Make sure this service is running on all Management servers and that any kind of SDK client (Console, Web Console, Connector, PowerShell) can connect to it.
- Configuration Service (responsible for detecting and issuing new configuration to all Health Services in the Management Group). Federate the Configuration Service to each Management Server so they all work together to keep the Management Group up to date.
- Health Service - Balance the RMS specific workloads amongst all Management servers in the Management Group and make sure during a failure the work is redistributed.
SDK Service
In OM12, setup sets this service to automatically start on every Management Server during install. We support any SDK client connecting to any Management Server. At Beta, you will need to configure NLB on the SDK Service for automatic failover.
Configuration Service
In order to federate the Config Service we needed to rewrite the config service almost completely. If you remember in OM 2007 versions the RMS always required a huge amount of memory to properly function. One of the main reasons for this was the Config service. You see every time the Config Service starts, it reads the Operational Database and loads its view of the instance space into memory in XML. In larger Management Groups, this file can easily grow to over 6 GB. The Config Service uses this file to compare against the Operational Database to detect changes and issue new configuration to Health Services. Now that every Management Server will have a running active Configuration Service it is not reasonable to store this in memory any longer. Moving forward the Config Service will store this data in a centralized database (Operational db) that all Config Services in the Management Group participate in keeping up to date and utilizing it to detect configurations changes to the instance space. A fantastic benefit that came out of this design is a much faster startup of Config Service. Once the database is initially created, on subsequent starts the Config Service does not need to rebuild this database from scratch and instead just maintains it. Therefore, it starts issuing configuration much sooner after restart. This is a major improvement over OM 2007 versions where in a large management group it could take up to an hour to start issuing configuration to agents.
Health Service (Resource Pools)
To distribute the RMS specific workloads to all management servers, we needed to develop a mechanism for each Health Service on the management server to function independently, while still having awareness of the workloads the other management servers are performing. This helps to ensure we do not get workflow duplication or missed workflows. To achieve this we added a new feature to OM12 called Resource Pool. Resource Pools are a collection of Health Services working together to manage instances assigned to the pool. Workflows targeted to the instances are loaded by the Health Service in the Resource Pool that ends up managing that instance. If one of the Health Services in the Resource pool were to fail, the other Health Services in the pool will pick up the work that the failed member was running. We also use Resource Pools to bring high availability to other product features like Networking and Unix monitoring. In a follow up blog post I will dive into far more detail on how resource pools work and how to tell where things are running.
To distribute the RMS specific workloads we create three resource pools by default.

- All Management Servers Resource Pool – We have re-targeted most RMS specific instances and workflows to this pool. By default if a instance does not have a “should manage” relationship set the Configuration Service will assign it to this pool.

- Notifications Resource Pool – We have re-targeted the Alert Subscription Service instance to this pool. The reason we did not use the “All Management Servers Resource Pool” was so you can easily remove the management servers from the pool that should not be participating in Notifications. For example, you may have three management servers but only one SMS modem. You would remove the other management servers from the pool so the Notifications workflows do not run where no modem is present.
- AD Assignment Resource Pool – Again we have re-targeted the AD Integration workflows to this pool so you can more easily control the location around where the AD assignment workflows will be running.
Notice in the screen capture above we have a column called Membership and it is set to “Automatic” for the default pools. This means all management servers in the management group are automatically a member of these pools. In order to change this you need to open PowerShell and run a PowerShell command (see below).
Get-SCOMResourcePool –Name “AD Assignment Resource Pool” | Set-SCOMResourcePool –EnableAutomaticMembership $FALSE


Now I can right click properties of the “AD Assignment Resource Pool” and modify the management server membership. Note: New management servers added to the Management Group will no longer be members of this resource pool automatically.


At this point you may be wondering about workflows targeted to the RMS that are outside of the OpsMgr product groups control (other management packs from different Microsoft teams or third party vendors). In order for us to not to break backwards compatibility and provide support for legacy management packs we decided to leave the Root Management Server instance and add a special role to one of the management servers in the Management group called the RMS Emulator. This RMS Emulator is only for backwards compatibility to legacy management packs and is in no way required for the management group to function correctly.
You can easily tell which management server is the RMS Emulator by opening the Console and navigating to the Management Servers view in the Administration space. We have added a new column called “RMS Emulator”. By default the first management server installed in the management group is the RMS Emulator. When upgrading to OM12 the former RMS is the RMS Emulator. Note: When upgrading from a secondary management server using the UpgradeManagementGroup switch the RMS Emulator is the management server you are running this from. On a follow-up blog post we will dive into more detail on setup and upgrade changes.

We have provided PowerShell cmdlets to move the RMS Emulator from one management server to another incase the management server acting as the RMS Emulator where to fail.

• To identify the current RMS Emulator in PowerShell
get-SCOMRMSemulator
•Move to the another Management Server
–First assign the new RMS Emulator management server to a variable
$MS = get-scommanagementserver –Name <FQDN of Management Server>
Set-SCOMRMSEmulator $MS
•Delete the RMS Emulator
Remove-SCOMRMSEmulator
–Type “Y” to approve
–Run get-SCOMRMSemulator to validate it is removed. You should see a message that says the RMS Emulator Role not found.
•Add RMS Emulator role to the MG
–First assign the new RMS Emulator management server to a variable
$MS = get-scommanagementserver –Name <FQDN of Management Server>
Set-SCOMRMSEmulator $MS
–Run “get-SCOMRMSEmulator” to verify its been created
Design Considerations
A few things to keep in mind when planning your OM12 Management groups with the topology changes.
- Due to the introduction of Resource Pools it is recommended that all management server have no more then 5ms latency between them. This means that if you are currently using management servers in multiple datacenters or sites we recommend you move all management servers to a single data center and use Gateway servers at the other sites.
- Moving forward the Product Group recommendation will always be to have two management servers in a Management Group at all times. By doing this you will always have High Availability for your management group and a much easier recovery during a disaster.
I hope this post has provided you with a lot of information to get you started on designing a Operations Manager 2012 topology. The next post in our series will be about the Setup and Upgrade changes.
Thanks
Rob Kuehfus | Program Manager | System Center
Disclaimer
This posting is provided "AS IS" with no warranties, and confers no rights. Use of included utilities are subject to the terms specified at https://www.microsoft.com/info/copyright.htm.