Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Networking Blog
The Official Blog Site of the Windows Core Networking Team at Microsoft
URL
Copy
Options
Author
invalid author
Searching
# of articles
Labels
Clear
Clear selected
464XLAT
AKS
AKSHCI
aks-hci
Azure
Azure Kubernetes Service
Azure Stack
Azure Stack HCI
CLAT
Containers
ctstraffic
ddr
DNR
DNS
DoH
DoT
Edge
EncryptedDNS
HCI
http
http.sys
http3
http sys
hybrid cloud
iperf
iperf2
iperf3
IPv4
IPv6
Kubernetes
Latency
MicrosoftSDN
Microsoft SDN
MsQuic
network
Networking
Network Virtualization
ntttcp
Performance
Policy
QUIC
SDN
SoftwareDefinedNetworking
Software Defined Networking
throughput
TLS 1.3
transport
VxLan
Windows
Windows Server
WS2022
- Home
- Windows Server
- Networking Blog
Options
- Mark all as New
- Mark all as Read
- Pin this item to the top
- Subscribe
- Bookmark
- Subscribe to RSS Feed

1,711


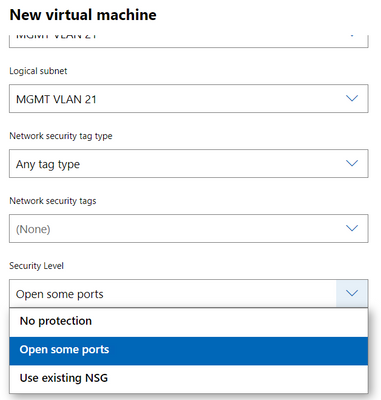
6,903

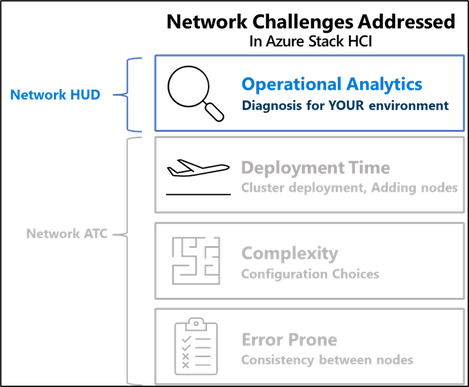
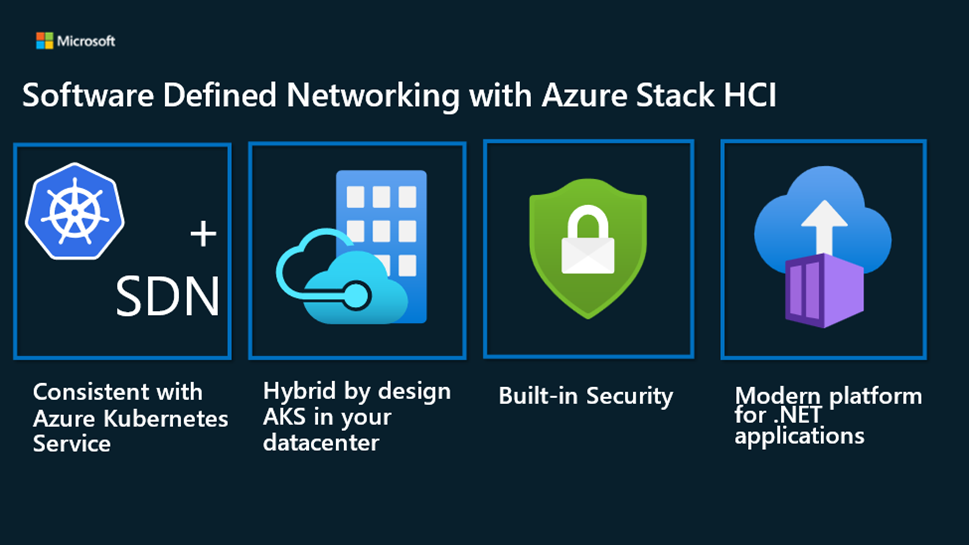
6,370
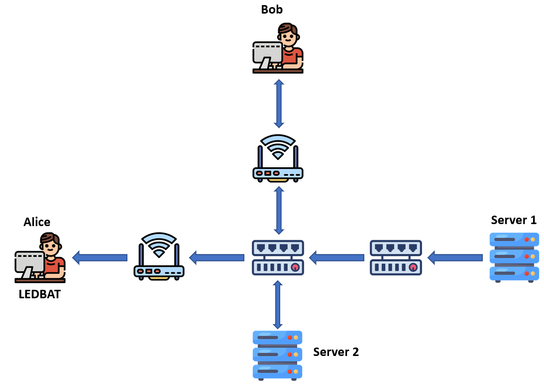




6,881
26.8K



Latest Comments